

2025年の DASH の基調講演は、Datadog のプラットフォームが進化を遂げた新たな節目となりました。AI を活用したインサイトによりオブザーバビリティがさらに強化され、システムの状態をより正確かつリアルタイムに把握できるようになりました。その結果、ワークフローの効率化や障害への迅速な対応が可能となっています。基調講演では、チーム間のサイロを解消しインフラの複雑性を軽減しながら、パフォーマンスやセキュリティの課題に素早く対応するための数十の新機能を発表しました。
Datadog は、柔軟な管理ができる状態を保ちながら、チームがスピード感を持って行動できるよう支援するツールを提供しています。たとえば、AI ワークロードのデバッグ、カスタム Datadog アプリの構築、マルチクラウド環境でのセキュリティの確保、テストの信頼性向上など、さまざまな場面で活用できます。
Datadog のインフラ監視、Software Delivery、ガバナンス 機能の主要なアップデートを含む、基調講演の主な発表内容を以下にご紹介します。また、Datadog で実現できることについては、他のまとめ記事もあわせてご覧ください。
AI ワークロードを監視・保護
複雑・分散・予測しにくいエージェント型システムに対応する
マルチエージェントシステムは、同じ入力に対してもエージェントが異なる判断を下したり、別の経路をたどったりするといった予測しにくい挙動により、デバッグが困難です。Datadog LLM Observability の新しい実行フローチャートでは、AI エージェントの実行内容と意思決定の流れを可視化します。エージェント同士の相互作用を実行フローチャート上で視覚的に明示するだけでなく、各エージェントが使用したツールや、実行時に行った検索・取得ステップも確認可能です。セットアップは簡単で、LLM Observability SDK を使えば、OpenAI Agent SDK、LangGraph、CrewAI、Bedrock Agent SDK などのフレームワークで構築された AI エージェントの動作を自動で追跡できます。 詳細は ブログ記事 (英語) をご覧ください。この機能は現在プレビュー版を提供中です。ご希望の方はこちらのフォーム からご登録ください。

LLM Experiments で LLM アプリの構築・検証・チューニングを一貫して行う
LLM Experiments は、LLM アプリケーションやエージェントの構築ライフサイクル全体を支援する、Datadog の LLM 製品スイートにおける新機能です。ゼロから、または本番環境のトレースデータをもとにデータセットを作成し、バージョン管理できます。実験を行い、ログを収集して、強力な可視化機能を使って結果を比較することで、プロンプト、モデル、プロバイダー、アーキテクチャの変更がパフォーマンスに与える影響を把握できます。LLM Experiments を活用すれば、最も効果的なバージョンを自信を持って特定し、本番環境にデプロイできます。さらに、複数のモデルプロバイダーをまたいでプロンプトをすばやくテスト・調整・改善できる専用環境「Prompt Playground」もあわせて提供しています。
詳しくは ブログ記事 (英語) をご覧ください。プレビュー版のご利用を希望される方は こちら からお申し込みいただけます。

AI Agents Console を使って、スタック内のすべての AI エージェントの動作と相互作用を監視する
AI Agents Console を使用すると、OpenAI の Operator のようなコンピューター操作エージェント、Cursor のような IDE エージェント、GitHub Copilot に代表される DevOps エージェント、Agentforce のようなエンタープライズ向けビジネス エージェント、さらには社内開発された独自のエージェントまで、エンタープライズ スタック内のあらゆる AI エージェントの動作と相互作用を監視できます。各エージェントのアクションを完全に可視化し、セキュリティやパフォーマンスの状況を把握し、ユーザーエンゲージメントを分析し、ビジネス価値を定量的に評価する――それらすべてを1 か所で一元的に実現します。AI Agents Console は現在プレビュー版を提供中です。ご利用を希望される方は こちら からお申し込みください。

Datadog GPU Monitoring で AI インフラの最適化とトラブルシューティングを行う
組織が AI や LLM ワークロードを拡大するにつれ、GPU の非効率的な利用やアイドル状態のインフラによりコストが増加し、パフォーマンスが低下するリスクが高まります。Datadog GPU Monitoring を使用すると、エンジニアリングチームや ML チームは、クラウド、オンプレミス、CoreWeave や Lambda Labs のような GPU-as-a-Service プラットフォームにわたって GPU の使用率や障害状況など、リソース全体の健全性をリアルタイムで把握できます。アロケーション、使用率、障害パターンに関するリアルタイムのインサイトにより、ボトルネックの特定、アイドル状態の GPU にかかる無駄なコストの削減、プロビジョニングのギャップの解消が可能になります。使用状況メトリクスをコストに直接結び付け、パフォーマンスに影響を与えるハードウェアやネットワークの問題を可視化することで、Datadog は、AI ワークロードを大規模環境でも安定して運用するための、迅速かつコスト効率の高い意思決定を支援します。詳しくは ブログ記事 (英語) をご覧ください。プレビュー版のご利用を希望される方は こちらのフォーム にご記入ください。

Data Observability でデータ ライフサイクルの信頼性を確保する
Data Observability は、データの取り込みから変換、下流における活用に至るまで、データ ライフサイクル全体の信頼性を確保する鍵となります。しかし、十分な Data Observability ソリューションがない場合、ユーザーは手動チェックやアドホックな SQL クエリ、あるいは事後的なアラートに頼ってデータ品質の問題を検知せざるを得ず、多くの場合、利害関係者が異常に気付いた後になってようやく問題が判明します。Datadog Data Observability は、ボリューム・行数変化・鮮度などの品質チェック、カスタム SQL ベースのモニター、異常検知、Snowflake や Tableau をまたぐ列レベルのリネージ、パイプライン全体の可視化、そしてデータ問題発生時のターゲット アラートを備えた包括的なソリューションです。詳細は 専用ブログ記事 (英語)をご覧いただくか、プレビュー版 にご登録の上、お試しください。

効率的なログの保存・検索
Flex Frozen でツールの切り替えや長期のログ保管にともなう運用負荷を解消する
新しい Frozen Tier を備えた Flex Logs for Datadog Log Management は、すべてのログを 1 つのプラットフォームにコスト効率よく集約できるよう支援します。これにより、外部ストレージの維持・管理にかかる負担や、作業の中断を招くようなツール間の切り替えを不要にします。Flex Frozen を使えば、ログを最大 7 年間、完全に管理されたストレージに保存しながら、コストを抑えつつ、リハイドレーションなしでそのまま検索可能です。これにより、監査対応や長期的な分析も迅速に行うことができます。そのため、Flex Frozen はコンプライアンス対応やインシデント発生後の調査などの目的でログを長期保管する際に最適なソリューションです。Flex Logs の詳細については、関連ブログ (英語) および ドキュメント (英語) をご覧ください。

Archive Search でアーカイブされたログをリハイドレーションせずにそのまま検索・活用する
Archive Search を使用すると、データをリハイドレーションしたり外部ツールにエクスポートしたりすることなく、Amazon S3 などのクラウド ストレージや Datadog の Flex Frozen Tier に保存されたアーカイブ ログを直接クエリできます。これにより、現在お使いの Datadog インターフェースとクエリ言語をそのまま使って、インシデント調査、コンプライアンス監査への対応、長期的なトレンド分析を効率的に行うことができます。 Archive Search は Log Workspaces や Datadog Sheets と統合されており、ログとインフラのメトリクスやトレースを相関的に分析できるため、調査がスムーズになり、ツールを切り替える手間もなくなります。Datadog プラットフォーム上で、ログをその場でプレビューし、関連するコンテキストを確認しながら、ログライフサイクル全体を通じた可視性を維持できます。詳しくは ブログ記事 (英語) をご覧ください。プレビュー版 のご利用を希望される方はご登録ください。

Bits AI Data Analyst と会話しながら、Datadog Notebooks のデータを分析・可視化する
Bits AI Data Analyst を使えば、Datadog Notebooks 上で自然言語と AI によるガイダンスを活用し、データの探索、可視化、課題の調査、レポート作成までを対話形式で行うことができます。複雑なクエリを手作業で書いたり、SQL とデータ変換を組み合わせたりする必要はありません。ユーザーは次のような高度な分析リクエストを自然言語で入力するだけで、自動的に処理が実行されます。
- 「過去 1 日のエラーログをすべて取得し、重複のないログメッセージを表示して。」
- 「サービスごとのレイテンシーを分解し、主な要因を特定して。」
- 「エラーログを既知の問題リストと結合し、新たに検出されたものをハイライトして。」
- 「デプロイタグと相関する 5xx エラーのスパイクを見せて。」
Bits AI はプロンプトを解釈し、クエリ、変換、結合、可視化などから構成される Notebook セルの論理的なステップを自動的に構築します。各セルは前のステップに基づいて順に積み上げられていくため、ユーザーは問題を段階的に深掘りしながら、調査の精度を高め、背景を踏まえた形で結果を理解することができます。Datadog Notebooks 内の Data Analyst 機能は現在プレビュー提供中です。ご利用を希望される方は こちら からお申し込みください。
複雑なデータを分析
Sheets のスプレッドシートのような操作感でデータを分析する
Datadog Sheets は、ログ、RUM イベント、クラウドコストデータ、インフラメトリクスなどのテレメトリーデータを分析できるスプレッドシート形式のインターフェースを提供します。使い慣れたスプレッドシートの機能で、ルックアップの実行、ピボットテーブルの作成、計算列の追加などが可能です。これにより、コードを書くことなく、データセットの結合、結果の集計、トレンドの調査まで柔軟に行えます。分析結果は視覚化してチーム内で共有したり、ダッシュボードに追加して継続的なモニタリングやコラボレーションに活用したりできます。詳しくは ブログ記事 (英語)と ドキュメント (英語) をご覧ください。

Notebooks で関連情報を活用しながら段階的な分析フローを構築する
Datadog は Notebooks 内で高度な分析機能を直接サポートするようになりました。複数ステップにわたるクエリの実行、変換処理の適用、結果の連結などを、柔軟で視覚的なインターフェース上で行えます。これにより、複雑なログからインサイトを抽出し、異なるデータセットを相関させ、調査の過程を文書化する作業を、Datadog 上だけで完結できます。Log Workspaces と同等の機能を備えるだけでなく、インラインでの解説表示や他の分析ツールとの統合といった拡張機能も提供しています。 詳しくは ブログ記事 (英語) をご覧ください。

迅速かつ効率的なソフトウェア デリバリーとインシデント対応
Datadog IDP でソフトウェアを短時間で確実にリリースする
Datadog Internal Developer Portal (IDP) は、開発者が共有されているエンジニアリングナレッジをすばやく検索したり、一般的な本番環境のタスクをセルフサービスで実行したり、新しいサービスコードの本番準備状況を評価したりできるよう支援します。Datadog IDP には、こうした用途を支える 3 つのコア機能を備えています。
- Software Catalog — サービス、キュー、データ ストアがシステム全体の中でどのような位置づけにあるかを、階層チャートによって可視化します。さらに、各コンポーネントの上流・下流の依存関係をマッピングし、それぞれのコンポーネントを通過するリアルタイムトラフィックも自動で検出します。
- Self-Service Actions — インフラやプラットフォームチームにチケットを出さずに、インフラのプロビジョニング、新しいサービスのスキャフォールド (初期構成) 作成、CI/CD の設定をセルフサービスで実行できます。
- Scorecards — 新サービスをリリースする前に、オブザーバビリティ (可観測性) のベストプラクティス、オーナーシップ、ドキュメント、本番準備状況といった基準に基づいてアプリケーションコードを本番リリースに向けた基準で自動的に評価する仕組みを提供します。
Datadog IDP がどのようにソフトウェア デリバリーを支援・加速するのかについては、ブログ記事 (英語) と ドキュメント (英語) をご覧ください。

Incident Response で復旧作業とチーム連携を統合する
インシデント対応はとかく混乱しがちです。発生直後の数分間は、複数のデバイスやプラットフォームを切り替えながらトリアージを行い、その後も関係者への情報共有のために、たびたび別のツールに移る必要があります。Datadog On-Call と Incident Response に新たに追加された機能により、これらの作業をシームレスに管理できるようになりました。AI 音声エージェントを使えば、電話から直接インシデントの概要を把握し、そのまま対応を開始できます。ハンドオフ通知を活用すれば、関連するコンテキストにすぐアクセスでき、他の対応メンバーとの連携もスムーズです。さらに、ステータスページを通じて、ユーザーに対して復旧の進捗状況を自動的に通知できます。詳細は ブログ記事 (英語) をご覧ください。

APM Latency Investigator でレイテンシー問題をすばやく調査する
分散システムにおける応答時間の増加原因を特定するには、トレース、メトリクス、ログ、プロファイリングデータを手作業でつなぎ合わせ、下流のボトルネックやデプロイの変更、データベースの遅延など、複数の仮説を検証する必要があります。Datadog の Latency Investigator for APM (現在プレビュー提供中) は、は、こうした仮説をバックグラウンドで自動的に検証し、過去のトレースを比較しながら、「Change Tracking」、「Database Monitoring」(DBM)、プロファイリングの各シグナルを相関させます。これにより、チームは大量のテレメトリーデータをすべて精査することなく、根本原因をすばやく切り分け、影響範囲を把握できます。ご利用を希望される方は こちらのフォーム からお申し込みください。

Proactive App Recommendations でパフォーマンスの問題点をすばやく修正する
システムが複雑になるにつれ、パフォーマンスや信頼性の問題は発見も対応もますます難しくなります。Proactive App Recommendations は APM、Real User Monitoring(RUM)、Continuous Profiler、Database Monitoring(DBM)などからのテレメトリーデータを分析し、問題を自動で検出して、実行可能な修正案を提示します。トレースデータやセッションリプレイ、プロファイリングのインサイトといったコンテキストを活用することで、検出から解決までをひとつのワークフローで完結できます。推奨された修正内容は、Datadog から離れることなく、すぐにプルリクエストとして生成可能です。API の順次呼び出しによって発生する処理の遅延を自動で検出・解消、フロントエンドでのユーザーの苛立ちを示す操作への対応 、非効率なコードパスの最適化など、Proactive App Recommendations を使えば、オブザーバビリティのデータをそのままアクションへとつなげられます。詳しくは ブログ記事 (英語) をご覧ください。

AI を活用したワークフローの効率化
Bits AI で自然言語を使って Datadog アプリをすばやく構築する
Bits AI に自然言語で要望を伝えるだけで、Datadog アプリを構築できます。たとえば「GitLab のデプロイをロールバックするアプリを作って」と入力すると、Bits AI が既存のデータや権限に基づいて、UI コンポーネントやアクション、ロジックを自動で生成します。フィールドやフロー、スタイルの微調整もチャットで対応可能で、コードに触れることなく短時間でアプリを完成させることができます。また、いつでも生成された定義にアクセスして内容を確認・編集することもできます。詳細は こちらのフォーム にご記入いただくか、カスタマー サクセス マネージャーまでお問い合わせください。

オンコール対応を支援する AI「Bits AI SRE」を活用する
Bits AI SRE は、オンコール対応を支援するAI アシスタントです。アラートを自律的に調査し、インシデント対応の調整も担います。Datadog、Slack、GitHub、Confluence などと統合されており、テレメトリーデータの分析、ドキュメントの参照、直近のデプロイ内容の確認を通じて、アラートの根本原因を特定します。ときには、PC を開く前に問題を把握できることもあります。Datadog On-Call を利用すれば、Bits による調査結果をスマートフォンから確認でき、どこにいても一歩先の対応が可能です。アラートがインシデントへと発展した際には、Bits が対応の調整役として関係者への情報共有、関連インシデントの提示、ポストモーテム(事後分析レポート) の作成までを担います。Bits は、すでにチームが使っているツールの中で自然に動作し、チャットを通じて連携しながら各調査から継続的に学習していきます。詳しくは ブログ記事 (英語)をご覧ください。
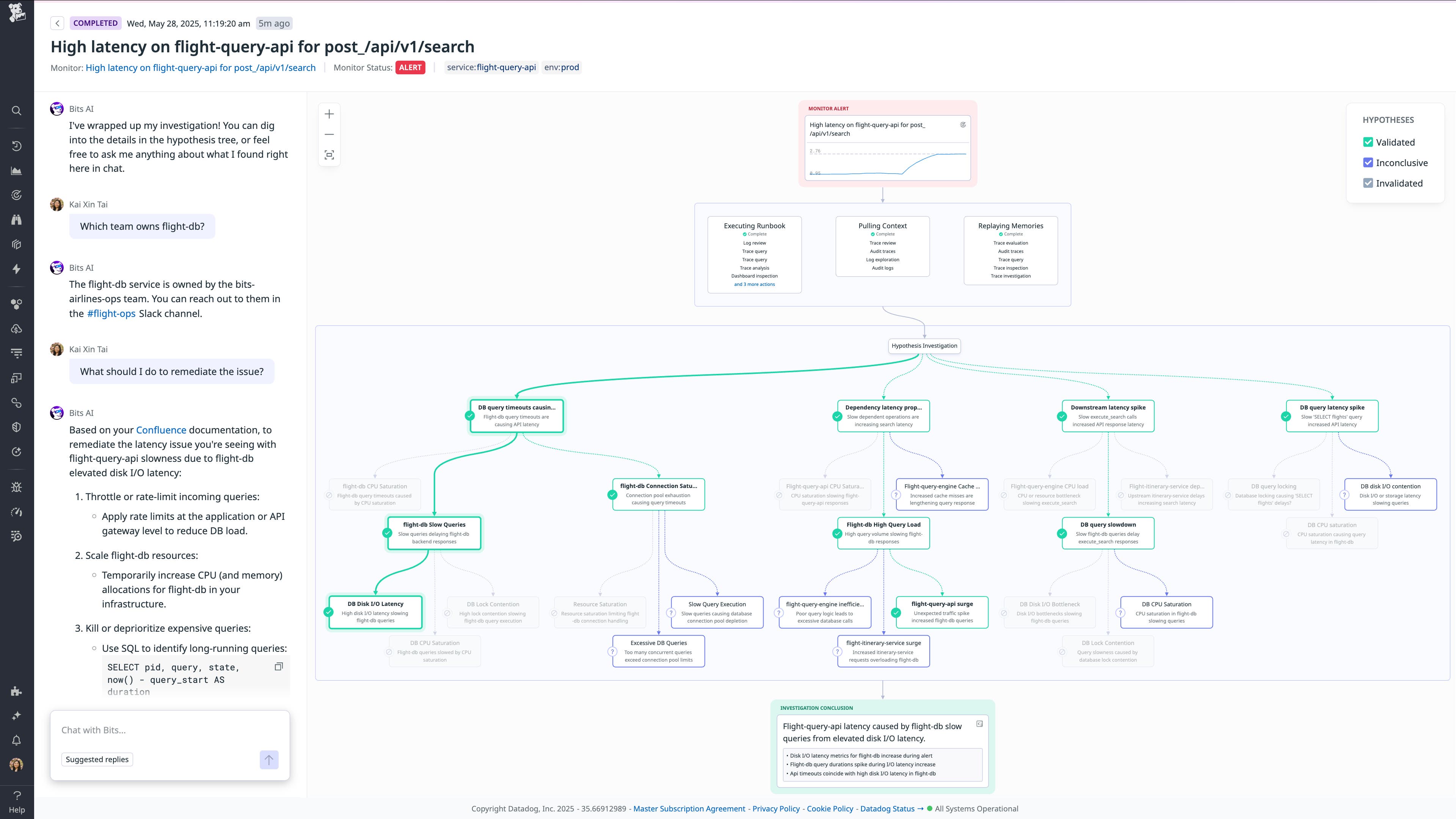
Bits AI Dev Agent で問題を自動的に特定し修正コードを生成する
Bits AI Dev Agent は、テレメトリーデータを自律的に監視し、重要な問題を検出して、本番環境にそのまま適用可能なプルリクエストを自動生成する、Datadog ネイティブの AI コーディングアシスタントです。リアルタイムのログ、メトリクス、セキュリティシグナル、ランタイムコンテキストを活用し、チーム標準に準拠したテスト付きの修正コードを的確に提案します。開発者は、豊富なコンテキストと明確な説明が添えられたプルリクエストを自分のタイミングで確認・レビューできるため、トラブルシューティングに時間を取られることなく、レビューやコード品質の向上に集中できます。
詳しくは ブログ記事 (英語) をご覧ください。プレビュー版 のご利用を希望される方はご登録ください。また、Bits AI SRE と Bits AI Security Analyst の新機能もぜひご確認ください。

Bits AI Security Analyst を使って Cloud SIEM の調査を自動化する
Datadog の Bits AI Security Analyst は、Datadog Cloud SIEM シグナルを自律的にトリアージし、潜在的な脅威を詳細に調査します。調査結果に基づき、明確かつ実行可能な対応策を提示することで、セキュリティチームの調査業務刷新します。Datadog にネイティブ統合されており、緩和に向けた豊富なコンテキストとガイダンスを提供することで、チームは進化する脅威に対して、より高い精度とスピードで先手を打つことができます。
Bits AI Security Analyst は現在プレビュー提供中です。こちら からご登録いただくか、ブログ記事 (英語) で詳細をご覧ください。

Action Interface 上で Bits AI を使い自然言語でアクションを実行する
Action Interface を使えば、ワークフローや専用アプリを用意することなく、チャットから Bits AI を介して、安全かつ監査可能なインフラ操作をその場で実行できます。SRE、オンコール、プラットフォーム、セキュリティ エンジニアは、サービスの再起動、サーバーのリブート、キャッシュのフラッシュ、ユーザーアカウントの隔離などの操作をわずか数秒で安全かつ制御された方法で実行可能です。すべての操作はロールベースのポリシーに従って適切にチェックされ、Datadog Audit Trail に記録されるため、確実な追跡性を担保できます。詳しくは ドキュメント (英語) をご覧ください。

Datadog Cursor Extension で本番環境の問題をリアルタイムでデバッグする
Datadog Cursor Extension は、Datadog の リモート MCP Server と連携し、Cursor IDE 上から Datadog のツールやオブザーバビリティデータに直接アクセスできるようにします。Cursor チャットで対話すると、Cursor Agent が Datadog Error Tracking と Live Debugging を活用して、アプリケーションコードにログポイントを追加します。これにより、エラーのトラブルシューティングや、実稼働データに基づくユニットテストの生成を支援します。Cursor Extension を使えば、ログポイントが実行時に取得した変数の値をリアルタイムで確認でき、Cursor Agent によって問題の原因となっているコード行を特定することも可能です。
Datadog Cursor Extension は現在 プレビュー版 としてご利用いただけます。ブログ記事 では、Cursor Extension を使って実際のビジネス課題をどのようにトラブルシューティングできるかをご紹介しています。詳しくは、ドキュメント (英語)をご覧ください。
Datadog MCP Server でAI エージェントを Datadog のツールやコンテキストに接続する
リモート版 Datadog MCP Server により、AI エージェントが Datadog のテレメトリーデータにアクセスできるようになります。これにより、認証や HTTP リクエストの処理、関連性の高いコンテキストをレスポンスに含めるといった、AI エージェントの運用における課題を解消できます。MCP Server は自然言語プロンプトの意図を解釈し、それに対応する Datadog のエンドポイントに後続リクエストを送信します。たとえば、Cursor や Claude、Codex などの MCP に準拠したエージェントに Redis のエラーを検索するよう依頼すると、エージェントは Datadog MCP Server を介して Datadog 環境から Redis ログを取得し、エラーの内容を表示します。
Datadog リモート MCP Server は現在 プレビュー版 としてご利用いただけます。本機能の詳細については ドキュメント (英語) をご覧いただくか、Redis エラーを検出し、進行中のインシデントと相関付ける一連の流れを紹介した ブログ記事 (英語) をご参照ください。


