


Matt Perpick
Alarm Bells Ringing
On my way to meet friends last Friday night, my phone buzzed in my pocket. One of our internal alerts was ringing. Sobotka, the system that processes Datadog’s incoming metrics data, was falling behind. Its backlog was growing and my night out was finished. I cancelled my dinner plans, grabbed my laptop, and got to work.
Diagnosis
Each of our internal systems has a dashboard that graphs its application and system metrics. My first stop to get a handle of the problem was Sobotka’s dashboard and, at a glance, it gave some pretty good high-level information. The throughput in metrics per second was lower than normal and in turn the backlog was growing. Sobotka wasn’t keeping up with the growing influx of customer metrics. The Sobotka servers were performing fine—CPU, load, and IO were all normal. So, It looked like the problem had to be elsewhere.
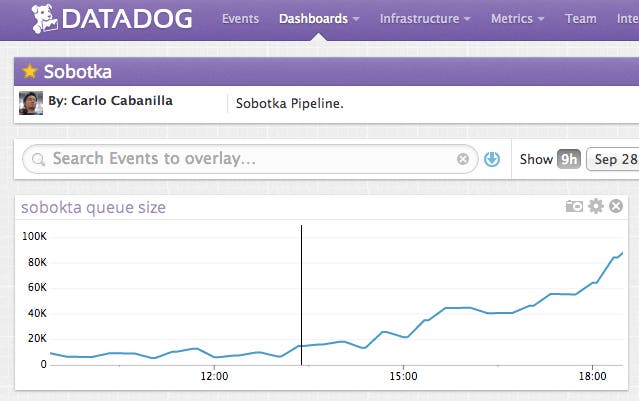
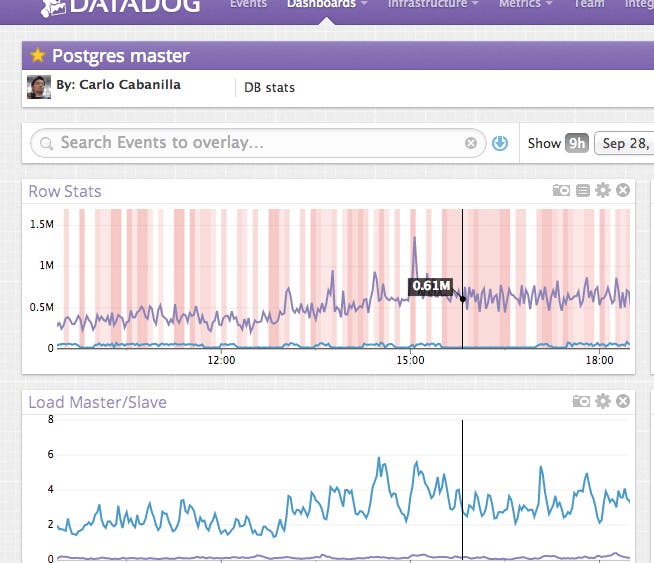
A quick survey of Sobotka’s dependencies (each on their own dashboard) suggested our Postgres instance might be the bottleneck. There was a big jump in the number of rows returned by the database at the exact same time the backlog started to grow and the load on the box was up as well. It looked like Sobotka was running more queries than ever and the database couldn’t keep up.
The fix
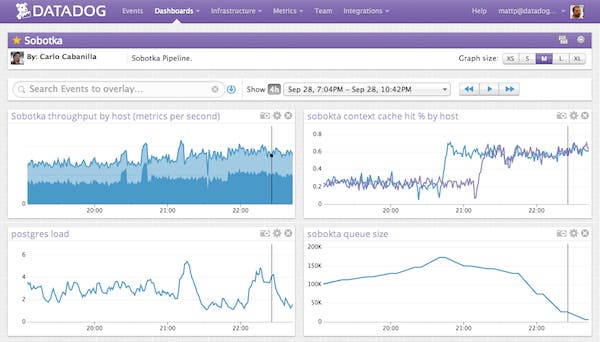
We needed a quick fix to reduce load on the database and get back on track. Earlier in the week we’d noticed one of Sobotka’s critical path caches was expiring too often and it was only hitting the cache 30 percent of the time, which isn’t nearly enough for a fast code path. An “I’ll fix it later” item was quickly upgraded to “Fix right f#
Things were momentarily worse while Sobotka’s in-process caches warmed up, but soon enough our hit percentage rose from ~25% to ~60% and our throughput started climbing. This gave Sobotka enough horsepower to chew through the backlog and some breathing room while we expand our capacity.
Epilogue
Sobotka, like most modern web applications, is complex. It is built of many processes on many machines, from libraries we wrote and systems we didn’t write, each which logs its critical data in different places. Finding a problem in Sobokta could be very hard, because the problem could be anywhere.
But despite its complexity, seeing inside of Sobotka is not complicated. It has a great dashboard with high-level metrics that measure the health of the system as a whole (like the backlog size, throughput and error rate). If these key metrics are not at expected levels (which we assert with alerts), we can drill down into real time graphs that show the health of sub-components like our caches or databases to root out the problem. We also graph system metrics to connect the application’s behaviour to what the machine is actually doing. And most of all, when we find a gap in Sobotka’s telemetry, we can add more metrics. It’s a living process.
Sobotka’s multi-layered telemetry doesn’t make the system any less complex, but it gives us a way of decomposing that complexity into small, understandable pieces — much like we try to do when we write software in the first place. That’s why we were able to go from an alert to a fix to a release in under an hour. Because we could see what was happening with the system.
Never again
I’ve worked on other systems with very poor telemetry—no graphs, no easy access to logs, not even SSH access to run top on a machine. Operational issues were true crises. If the site went down we couldn’t answer basic questions like “Are there more users than normal?”, “Which page is slow?” and “How long does this query usually take?” And worst of all, we often struggled to answer, “How can we fix this?” We just could not connect the dots between our systems, our application and our users quickly enough. I don’t look back fondly on those times.
Eureka
The first time I had great real-time graphs to help debug an operational issue was a “Eureka!” moment in my career as a maker of software. I had a similar moment the first time I merged a complex change with git and it just worked, and another one the first time a unit test caught a showstopper bug in a continuous integration build. Each of these times, I remember thinking “I’ll never work without tools like this again.”
And that’s what we’re trying to build at Datadog, an indispensable tool for developers and ops trying to see inside their critical systems.



