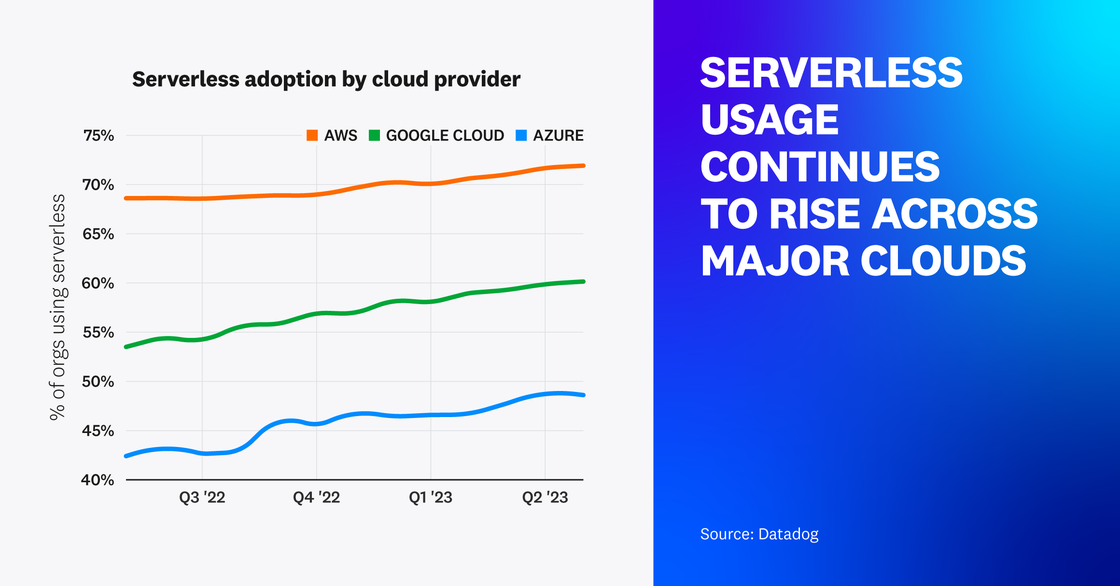
Major cloud providers continue to see significant serverless adoption
Over the past year, serverless adoption for organizations running in Azure and Google Cloud grew by 6 and 7 percent, respectively, with AWS seeing a 3 percent growth rate. Over 70 percent of our AWS customers and 60 percent of Google Cloud customers currently use one or more serverless solutions, with Azure following closely at 49 percent.
For this year’s report, we have included two new serverless platforms in our data: Azure Container Apps and AWS CloudFront Functions. While FaaS solutions continue to be the primary driver of overall serverless popularity, we see that cloud providers are expanding their suite of serverless tools to better meet the needs of their customers. As cloud providers improve their existing solutions and deliver newer and wider sets of offerings—such as serverless containers and serverless edge computing—more organizations are able to use these tools to deliver value to their customers.
Note: For the purpose of this fact, a serverless organization uses at least one of the following technologies:
- AWS: AWS Lambda, AWS App Runner, ECS Fargate, EKS Fargate, AWS CloudFront Functions
- Azure: Azure Functions, Azure Container Apps, Azure Container Instances
- Google Cloud: Google Cloud Functions, Google App Engine-Flex, Google Cloud Run
Google Cloud leads in fully managed container-based serverless adoption
In 2022, we reported that organizations were extending their use of serverless technologies beyond traditional functions with managed runtimes—such as AWS Lambda, Google Cloud Functions, and Azure Functions—toward functions packaged as containers and fully managed container-based application platforms.
Those trends have continued across all three major clouds—particularly in Google Cloud, where 66 percent of all serverless organizations now use container-based serverless workloads (i.e., Cloud Run and 2nd gen Cloud Functions).
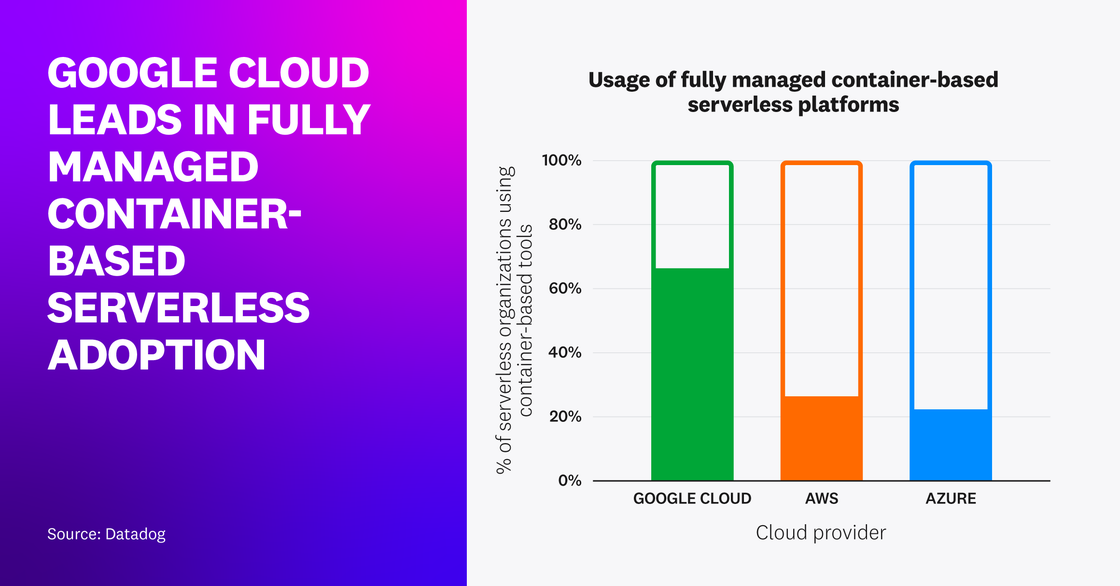
While Google Cloud has led in this category since launching Cloud Run in 2019, this year AWS increased to 26 percent of serverless organizations running fully managed container workloads with containerized Lambda functions and AWS App Runner. This is up from roughly 20 percent last year. Close behind is Azure at 22 percent; albeit starting with smaller numbers, Azure’s year-over-year growth in container-based workload adoption has been notably impressive at 76 percent, driven by the release of Azure Container Apps in May 2022.
One reason why container-based serverless compute platforms have grown more popular is likely because they simplify serverless adoption and migration. For instance, organizations can upload their existing container images to cloud provider-hosted registries and seamlessly deploy those containers as microservices. Serverless container products also support a wider breadth of languages and larger total application sizes compared to serverless functions, further aiding workload migration.
“At Google Cloud, we are committed to serving our customer needs for portability and flexibility with our serverless offerings. Cloud Run and 2nd gen Cloud Functions—our container-first approach to Functions-as-a-service (FaaS)—gives customers the ability to run their workloads on any cloud platform, on prem, and any container platform on Google Cloud, making it easy to go from Cloud Functions to Cloud Run and Google Kubernetes Engine. This approach serves our customers by saving them money, reducing their need to rework their workloads between platforms.”
Product Manager, Serverless, Google Cloud
Frontend development is the leading category of emerging serverless platforms
The major cloud providers, such as AWS, Google Cloud, and Azure, are not the only players in the serverless compute game. Today, modern frontend development and content delivery network (CDN) platforms such as Vercel, Netlify, Cloudflare, and Fastly also offer developers specialized serverless compute capabilities that are tightly integrated with their core platform offerings. Seven percent of all organizations that are monitoring serverless workloads in a major cloud are also running workloads using at least one of these emerging cloud platforms. Of these, 62 percent use a frontend development platform like Vercel or Netlify, and 39 percent use edge compute offerings from Cloudflare and Fastly.
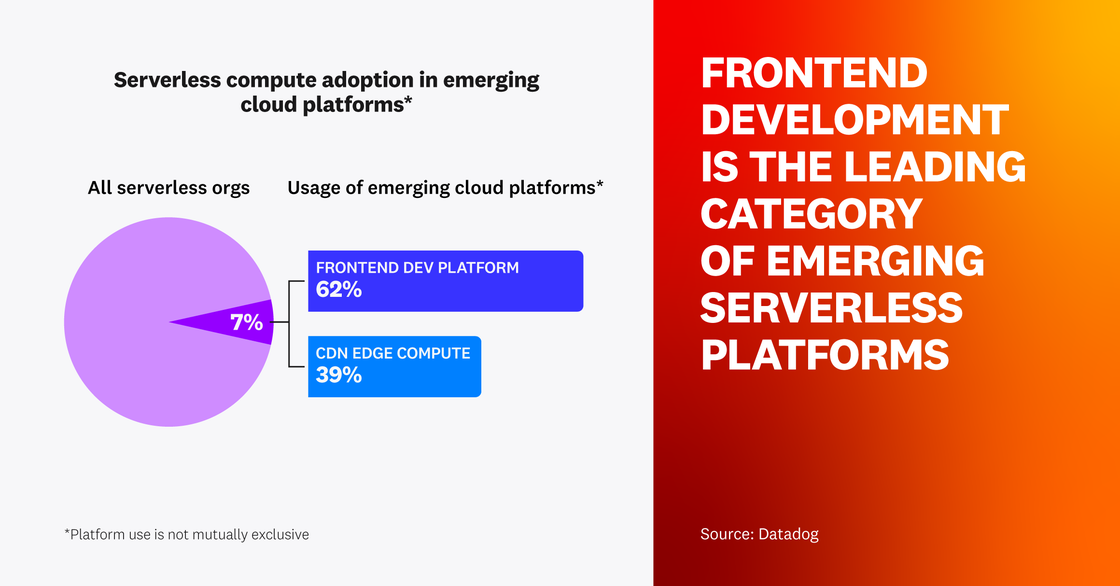
Platforms like Vercel Functions and Netlify Functions enable frontend developers to easily create and run entire applications from the cloud, making full-stack projects and development accessible to even more people. Meanwhile, distributed edge platforms like Cloudflare Workers and Fastly Compute@Edge enable developers to build serverless applications closer to end users in a tightly integrated way with their existing CDN provider, meaning they can more easily deliver highly performant A/B testing, personalization, authentication, and more.
Cloudflare, Vercel, and others have evolved to embrace both frontend development and edge compute for full-stack development. For example, Cloudflare offers Pages and other tools to enable building full-stack applications in tandem with Workers. And when deploying an app in Vercel, developers can make use of their Edge Network. Overall, the evolution of CDN and frontend development platforms outside of the major cloud providers suggests organizations are embracing alternative options for providing highly performant end-user experiences.
“From a frontend perspective, developers have always understood the power of the server for rendering better end-user experiences and SEO, but historically the barrier of entry to maintaining and provisioning a globally distributed edge network has been prohibitive for everyone but the largest companies. With innovations in the frontend cloud ecosystem—such as streamlined access to the serverless primitives and frontend frameworks that increasingly embrace a server-first model, like Next with React Server Components—we’re seeing the industry shift back to what made the web great to begin with: faster, more personalized, more first-party, and more private experiences.”
CEO, Vercel
Node.js and Python remain dominant languages for AWS Lambda functions
Python and Node.js are still the most popular languages used among AWS Lambda developers. In fact, well over half of the invocations in our Lambda dataset were from functions written in Python or Node.js. In addition to being among the two earliest languages to be supported by Lambda, both languages have robust tooling for Lambda and large communities of developers. This is why, when organizations are starting out with serverless, they tend to do so with Python and Node.js.
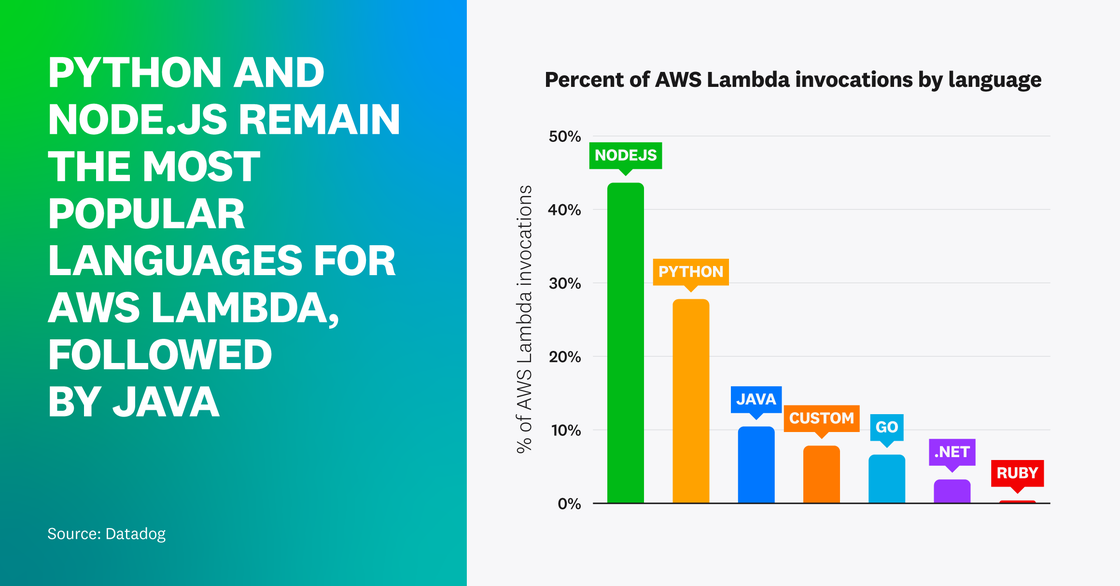
Per our research, Java is the third most common Lambda language, closely followed by custom runtimes and Go. Together they account for just under a quarter of all the Lambda invocations by our customers. Java’s status as the third most common Lambda language is likely due to a growing number of large enterprise organizations migrating their existing workloads and applications written in Java over to Lambda.
Additionally, custom runtimes are the fastest-growing types of functions and have seen their share of Lambda function invocations increase by more than 50 percent year over year. It is our belief that custom runtimes have risen in popularity because of the increased interest in serverless containers, which extend the capabilities of serverless by enabling developers to write functions in languages Lambda doesn’t natively support, such as PHP and Rust.
“In 7 years of running production workloads on AWS Lambda, across Node, Python, Java, and custom runtimes, I can't think of one time where our client has regretted the decision. The operational burden is dramatically lower and—after an initial learning curve—developer and DevOps productivity much higher.”
CTO, Trek10
AWS Lambda function cold starts in Java are two times longer than Python or Node.js
One of the main concerns of serverless developers today is overcoming the challenge of cold starts, which occur when a serverless compute platform must create a new execution environment in order to serve a request. The impact of cold starts in Lambda varies depending on which runtime a function is written in. For instance, Node.js and Python functions experience the shortest cold start durations whereas Java functions experience the longest. Java’s average cold start duration—which is nearly three times as long as Python’s—is likely due to the time it takes to load the Java Virtual Machine (JVM) and libraries Java requires to run.

Our research also revealed that the amount of memory allocated to Lambda functions varies by runtime. This is likely because increasing the memory allocated to a Lambda function also increases the amount of CPU allocated to it, which helps to reduce cold start durations. Runtimes that already have the shortest cold start durations—such as Python and Node.js—typically have less memory allocated to them than Java. AWS continues to develop a suite of tools that help developers combat cold starts and lessen their impact on serverless function performance, such as provisioned concurrency, proactive initialization, and Lambda SnapStart.

“Datadog's 2023 The State of Serverless report unveils insights on how developers accelerate modern app development by adopting the serverless operational model. As we strive to enhance the developer experience, we continue to innovate across many areas, such as Lambda SnapStart for Java, which delivers up to 10x faster function startup performance without developers making changes to their code.”
Head of Product Management, AWS Lambda
AWS Lambda use on ARM has doubled over the past year
In 2021, AWS announced support for Lambda functions on ARM-based Graviton2 processors, promising faster execution times and up to 34 percent lower costs compared to x86-based processors. The portion of serverless organizations using Lambda that have adopted ARM has doubled in the past year, with 11 percent of organizations now using ARM in some capacity to invoke Lambda functions.
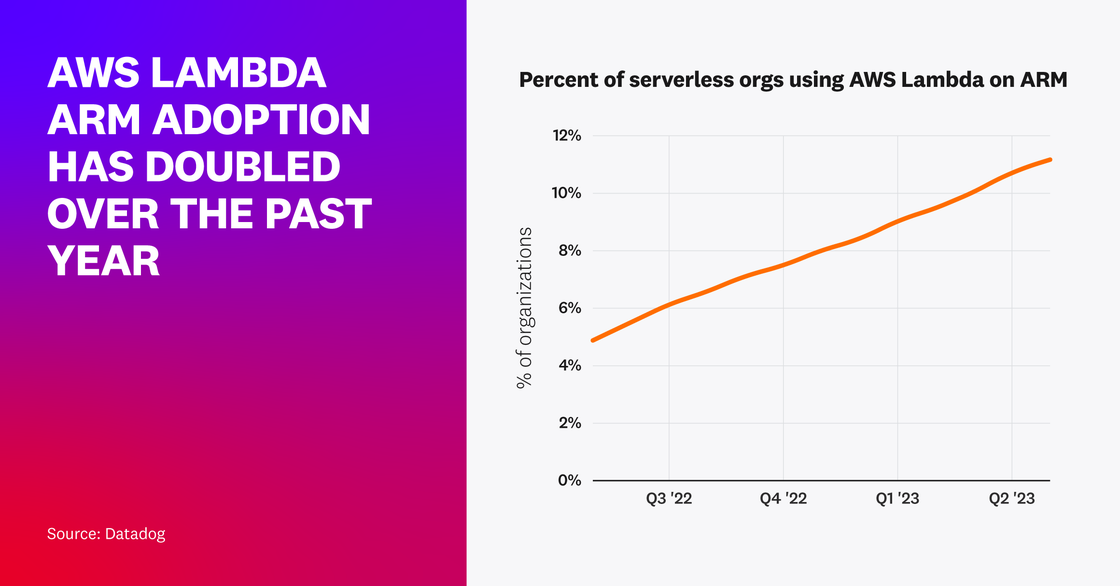
Among these organizations that have begun adopting ARM, 29 percent of their functions using ARM-eligible runtimes are now running on ARM. These adoption trends suggest that these organizations are likely getting the combined performance and cost benefits that were proposed.
But these numbers also show that there is still opportunity for even more eligible functions to be moved to ARM. One reason why we haven’t seen more AWS Lambda functions moved to ARM could be that Graviton2 is not yet available in all AWS regions (see here for the latest) and is only compatible with a subset of Node, Python, Java, .NET, Ruby, and custom runtimes. Because they are not universally available, deployment and automation tools like the Serverless Framework have not yet begun setting them as the default configuration.
Based on conversations with our customers, we expect to see adoption continue to grow as regional and runtime availability continue to increase and as ARM becomes a default configuration for serverless tooling.
“Lambda functions powered by ARM-based Graviton2 processors offer better performance at a lower cost. We expect to see them become the default choice across deployment frameworks as they become available in more regions.”
AWS Serverless Hero and CEO, Ampt
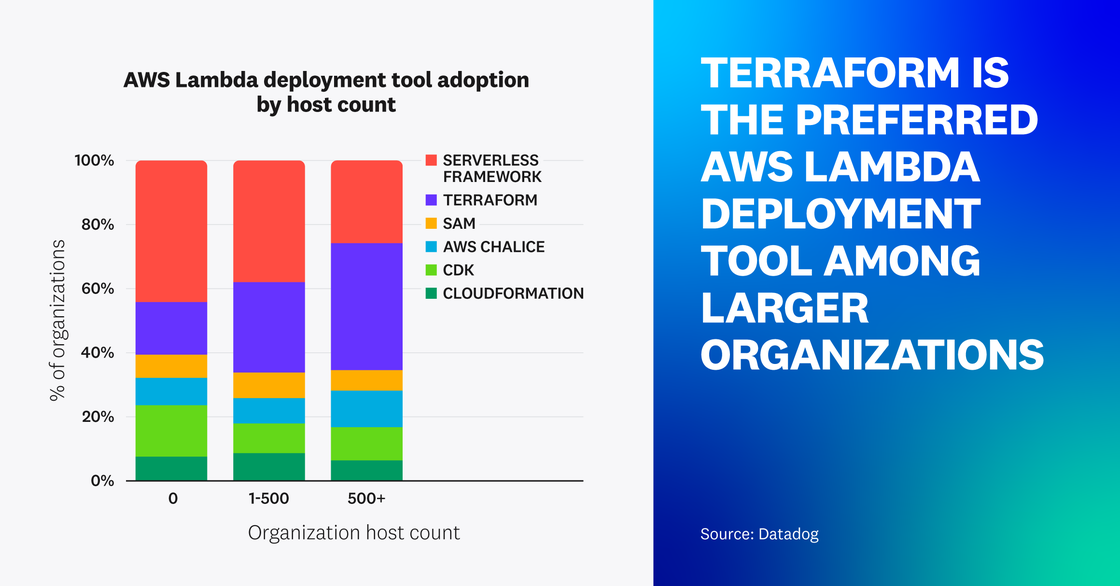
Terraform is the preferred AWS Lambda deployment tool among larger organizations
Infrastructure as code (IaC) tools like the Serverless Framework and Terraform help developers overcome the challenge of manually deploying and configuring Lambda functions and other resources at scale. AWS offers CDK, SAM, and Chalice as frameworks on top of their IaC platform, CloudFormation. These tools enable teams to better define their infrastructure and manage all of their serverless resources in a programmatic way. Our observations reveal that as organizations mature and expand, the preferred IaC tool for deploying and managing their Lambda functions shifts in predictable ways.
For instance, the Serverless Framework is the most popular IaC tool for managing AWS Lambda functions among Datadog customers. It provides streamlined opinionated workflows that make it straightforward to deploy applications and serverless infrastructure together. This, along with the strong community support it has among developers, has made it a popular and inviting entry point for newcomers and serverless-focused teams.
With that said, we’ve seen that as organizations’ host counts increase, they tend to use Terraform for managing AWS Lambda. This suggests that Terraform’s flexibility, multi-cloud support, and wide adoption and use by DevOps teams are preferred by larger organizations operating within a diverse cloud infrastructure.
“Startup and serverless-only teams have the freedom to choose the purpose-built tools for building serverless apps, like Serverless Framework, SST, and others. As serverless technologies become a key piece of an organization's infrastructure alongside traditional workloads, those teams need to prioritize a solution that allows them to manage all of their workloads centrally.”
AWS Serverless Hero and CEO, Buttonize.io
65 percent of organizations have connected AWS Lambda functions to a VPC
As organizations adapt and replace parts of their existing services with Lambda, it’s important to make sure every serverless function remains integrated across their entire infrastructure. To do this, many teams connect Lambda functions directly to the virtual private clouds (VPCs) that contain their broader compute and database resources in isolated networks. In addition to providing granular network accessibility and security, VPCs are increasingly required for organizations to connect serverless workloads for larger applications to existing infrastructure services, such as Elastic Cloud Compute (EC2) or Relational Data Store (RDS) instances in standard deployments.
Over the last year, 65 percent of Datadog customers using Lambda have deployed at least five of their Lambda functions connected to a dedicated VPC in their own AWS account. Even more customers—80 percent—have at least one Lambda function connected to a dedicated VPC, while 10 percent run all of their functions with their own VPC.
There are risks and tradeoffs to consider when connecting Lambda functions to your account’s VPC. By not using the default AWS-monitored and secured VPC, your organization may be taking on a greater footprint of responsibility within the shared responsibility model. Additionally, while AWS has made significant improvements to ENI connection performance in recent years, there is still an additional cold start cost to VPCs.
“Teams adopting Lambda still need to make informed decisions based on their security, performance, and functional requirements, which won’t be one-size-fits-all. Today, those commonly involve the need to connect to VPCs to integrate with existing applications, infrastructure, and compliance requirements, though VPCs are not a universal fit for all applications or cases. As applications and teams evolve, there is an opportunity to move toward more cloud-native and serverless-first solutions for networking and security, such as RDS proxies and VPC endpoints.”
Principal Architect, Arc XP, A Washington Post Company