
“Serverless” may be a buzzword, but it's not an empty one. Less than five years since it launched, AWS Lambda has already been adopted by nearly half of companies with infrastructure in AWS. In this report, we examine the serverless usage of thousands of companies to provide a look at how (and how much) serverless is being used in the real world.
Serverless eliminates the need to provision and manage infrastructure components (e.g., servers, databases, queues, and even containers), allowing teams to focus on code while minimizing their operational overhead. This report will focus specifically on a subset of serverless known as functions-as-a-service (FaaS), which provides the same pay-as-you-go model that defines the public cloud, but at the level of “functions” rather than infrastructure components. Functions are simply pieces of code that perform a discrete unit of business logic when invoked by a user request or some other event.
For the purposes of this report, we focus on AWS Lambda, which at the start of 2020 is the most mature and widely adopted serverless platform in our user base and beyond. In future editions of the report, we may examine serverless offerings from other providers, such as Google Cloud Platform and Microsoft Azure.

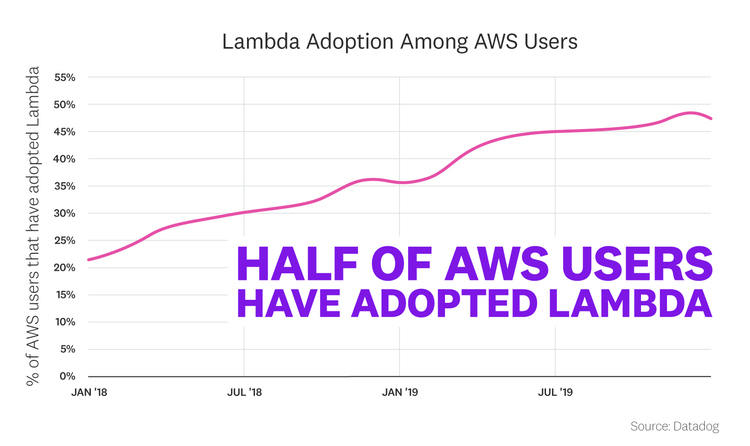
Half of AWS users have adopted Lambda
At the dawn of 2020, Lambda is no longer a niche technology. Nearly half of Datadog customers that use Amazon Web Services have now adopted Lambda. (See the Methodology section below for how we define Lambda adoption and AWS usage.) This adoption rate, along with the breakdown of Lambda usage by environment size (covered in the next fact), shows that Lambda is no longer limited to cloud-native early adopters or niche use cases. On the contrary, serverless functions are now in widespread use across a variety of companies with an infrastructure footprint in AWS.

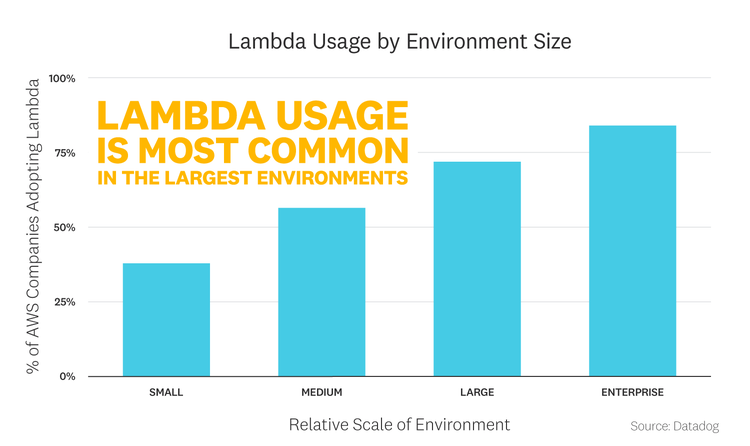
Lambda is more prevalent in large environments
Perhaps surprisingly, the widespread adoption of Lambda has not been driven by newer, smaller companies. Rather, we see a clear correlation between Lambda adoption and the scale of a company's infrastructure environment, whether that environment is primarily servers, containers, or serverless functions. (See the Methodology section below for more on these size distinctions.) Among the companies with the largest infrastructure footprints, more than three quarters have adopted Lambda.

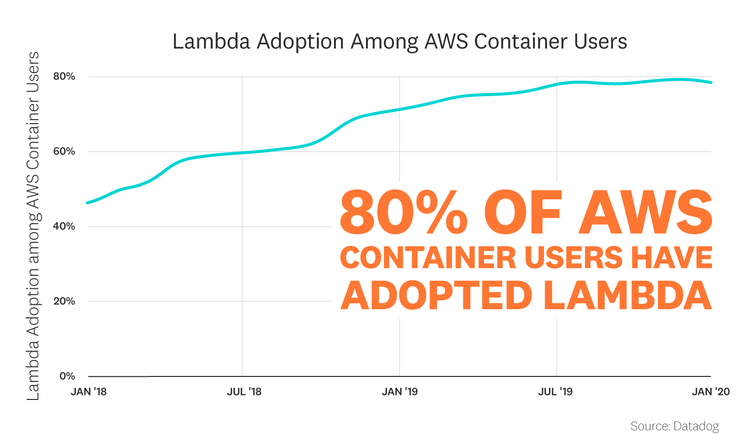
Container users have flocked to Lambda
Lambda has proved especially popular among companies running containers in AWS. As of January 2020, nearly 80 percent of organizations in AWS that are running containers have adopted Lambda. Although serverless functions and containers are two very different environments, they tend to be embraced for similar reasons, such as abstracting away infrastructure concerns for ease of operations. There are some use cases in which Lambda and container infrastructure are directly connected (e.g., using Lambda functionsto trigger Amazon Elastic Container Service tasks), but many more organizations may be running them separately to fill different needs. For example, a company might run the bulk of their application in a container cluster, while offloading bursty, short-running tasks (such as payment processing) to serverless functions.

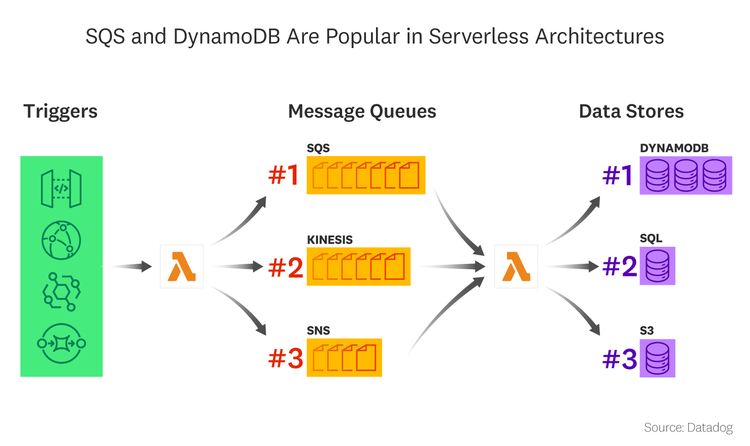
Amazon SQS and DynamoDB pair well with Lambda
Lambda users have a vast array of technology choices when it comes to connecting their functions to infrastructure and application components. Once a function is triggered, it often sends the data it produces to a message queue, which routes the data onward to other Lambda functions, server-based applications, or cloud services. Message queues help organizations embrace the “pay only for what you use” model of serverless. Instead of a function calling another function and waiting idly for a response (and racking up billable invocation time), serverless functions can make calls asynchronously via a message queue. And because functions are ephemeral and stateless, they often read from or write to a separate, persistent data store.
Among the services that are called or queried in the same request as a Lambda function, Amazon DynamoDB comes out on top. The key-value and document store is a natural fit for Lambda functions, given that it is a hosted, auto-scaling data store that promises low latency. The next most popular choices for data stores in Lambda use cases are SQL databases (whether Amazon RDS instances or self-managed databases) and Amazon S3, respectively. Amazon SQS (Simple Queue Service) is the top choice for a message queue in Lambda requests, followed by Amazon Kinesis and Amazon SNS (Simple Notification Service). SQS is a logical fit for serverless architectures: it is simple to set up and scale, relatively inexpensive, and offers tight integration with Lambda.

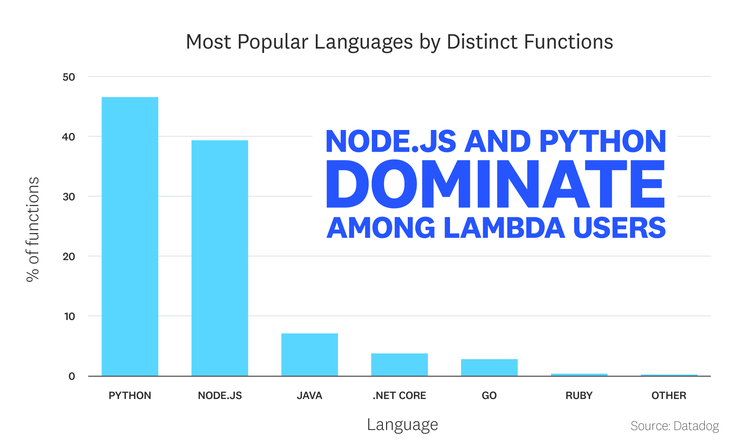
Node.js and Python dominate among Lambda users
Among the languages and frameworks available to Lambda users, we see two clear leaders in terms of usage: Python and JavaScript (via Node.js). Forty-seven percent of all deployed Lambdas currently run Python, with another 39 percent running Node.js applications. Python 3 outweighs Python 2 (which reached end of life in January 2020) by a factor of two to one.
The popularity of the Python and Node.js Lambda runtimes reflects recent trends in application development as well as the evolution of the Lambda service itself. AWS first launched Lambda in preview in 2014 with Node.js as the first supported runtime, before adding Java and Python support in 2015. Support for C# (via .NET Core), Go, and Ruby were added more recently, in 2018.

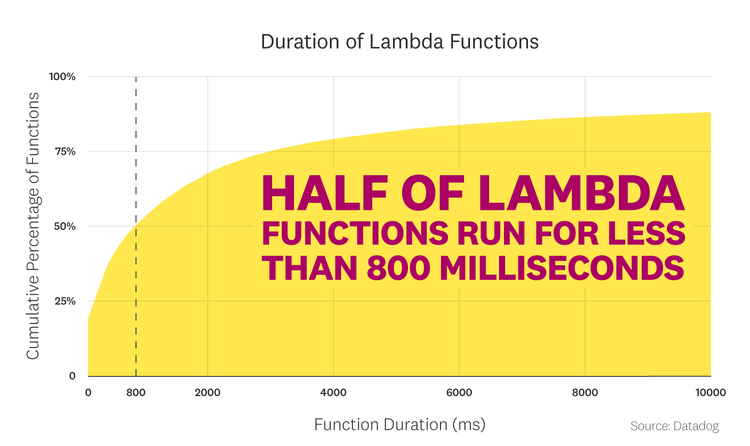
The median Lambda function runs for 800 milliseconds
The median Lambda function runs for about 800 milliseconds, averaged across all its invocations, but the tail of the latency distribution is long. One quarter of Lambda functions have an average execution time of more than 3 seconds, and 12 percent take 10 seconds or more. The long duration of some Lambda functions is notable because serverless latency impacts not only app performance but cloud costs. Lambda pricing is based on “GB-seconds” of compute time: the memory allocated to your function (detailed in the following fact), multiplied by the duration of its invocations.
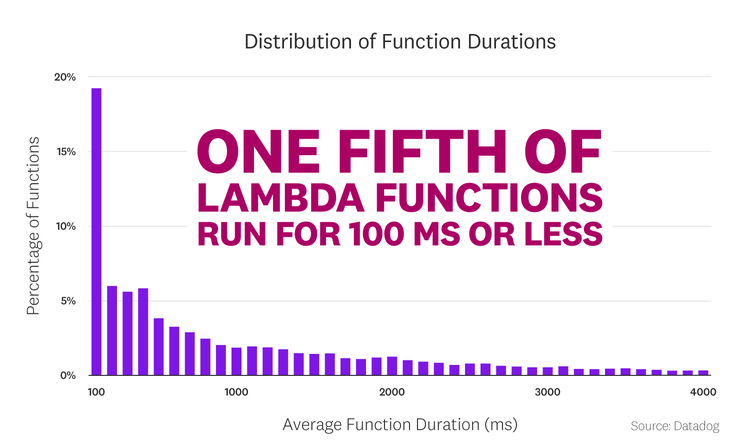
Zooming in on the distribution of function duration reveals that nearly one fifth of functions execute within 100 milliseconds, and roughly one third execute within 400 milliseconds.

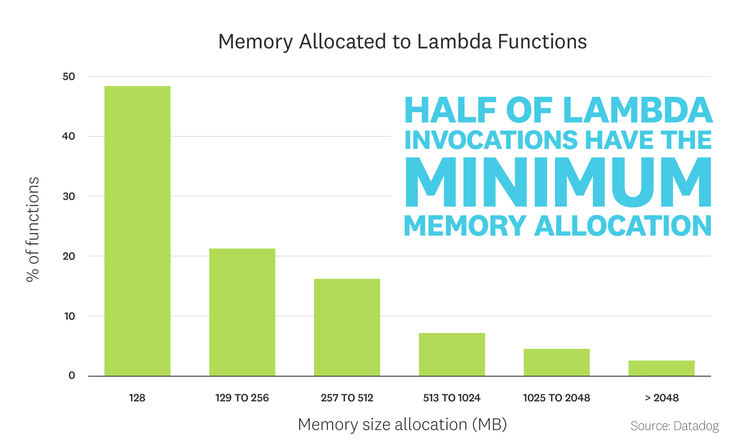
Half of Lambda functions have the minimum memory allocation
As mentioned above, the cost of a Lambda invocation is calculated from the product of the duration and the function's memory. As such, companies running Lambda are incentivized to limit the memory allocation of their functions (which is a configurable setting and is therefore easier to control than the function's duration). Indeed, 47 percent of functions are configured to run with the minimum memory setting of 128 MB. By contrast, only 14 percent of functions have a memory allocation greater than 512 MB, even though users can allocate up to 3,008 MB per function.

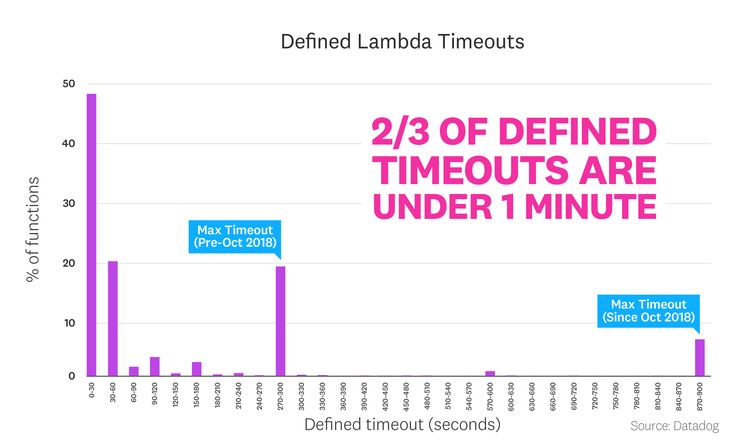
Two thirds of defined timeouts are under 1 minute
Each Lambda function has a configurable timeout setting, ranging from 1 second to 15 minutes, the longest allowed duration for a Lambda invocation. Most functions make use of short timeouts: two thirds of configured timeouts are 60 seconds or less. (The default timeout when a function is created is 3 seconds.)
Short timeouts are often advised, both because hanging functions can run up cloud costs and because Lambda application architectures often necessitate a fast response. Amazon API Gateway, which is commonly used to provide a REST interface in front of a Lambda function, has a maximum timeout setting of 29 seconds. So any Lambda functions behind an API Gateway that take longer than 29 seconds to respond will result in an error, even if the Lambda completes its work successfully. Despite those considerations, many functions have been configured to use the maximum allowable timeout setting—both the current 900-second limit and the previous limit of 300 seconds (which was in effect until October 2018).

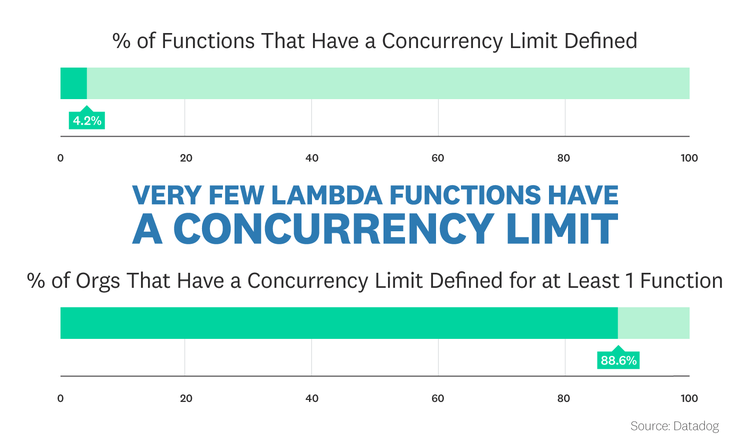
Only 4 percent of functions have a defined concurrency limit
By default, Lambda customers are limited to 1,000 concurrent executions of all functions in a given region. Users can set per-function concurrency limits, which effectively reserves a portion of the total concurrency pool for a specific function. If the function exceeds its concurrency limit, it will be throttled.
Today, only 4.2 percent of all functions have a configured concurrency limit, even though most organizations are aware of the optional limit. Indeed, 88.6 percent of companies running Lambda make use of concurrency limits for at least one function in their environment. The functions that do have a defined concurrency limit are far more likely to be throttled. Over a 5-day evaluation window, 8.3 percent of functions with a concurrency limit were throttled at least once, as compared to just 0.3 percent of functions that are constrained only by per-region, rather than per-function, limits.
Sign up to receive serverless updates
eBooks | Cheatsheets | Product Updates

METHODOLOGY
Population
For this report, we compiled usage data from thousands of companies in Datadog's customer base. But while Datadog customers cover the spectrum of company size and industry, they do share some common traits. First, they tend to be serious about software infrastructure and application performance. And they skew toward adoption of cloud platforms and services more than the general population. All the results in this article are biased by the fact that the data comes from our customer base, a large but imperfect sample of the entire global market.
Lambda adoption
In this report, we consider a company to have adopted Lambda if they ran at least five distinct Lambda functions in a given month. The Datadog Forwarder function, which ships data such as S3 and CloudWatch logs to Datadog, is excluded from the function count.
AWS usage
We consider a company to be using AWS if they ran at least five distinct Lambda functions or five distinct EC2 instances in a given month. In this way, we can capture an AWS user base comprising companies that are exclusively running EC2 instances, exclusively running serverless functions, or running a mix of both.
Scale of environments
To estimate the relative scale of a company's infrastructure environment, we examine the company's usage of serverless functions, containers, physical servers, cloud instances, and other infrastructure services. Although the boundary between categories (such as “medium” and “large”) is necessarily artificial, the trend across categories is clear.