- Product
Infrastructure
Applications
Data
Logs
Security
- Overview
- Code Security
- Software Composition Analysis
- Static Code Analysis (SAST)
- Runtime Code Analysis (IAST)
- IaC Security
- Cloud Security
- Cloud Security Posture Management
- Cloud Infrastructure Entitlement Management
- Vulnerability Management
- Compliance
- Cloud SIEM
- Workload Protection
- App and API Protection
- Sensitive Data Scanner
- Security Labs Research
- Open Source Projects
- Secret Scanning
Digital Experience
Software Delivery
Service Management
AI
Platform Capabilities
- Bits AI Agents
- Metrics
- Watchdog
- Alerts
- Dashboards
- Notebooks
- Mobile App
- Fleet Automation
- Governance Console
- Access Control
- Incident Response
- Case Management
- Event Management
- Workflow Automation
- App Builder
- Cloudcraft
- CoScreen
- Teams
- OpenTelemetry
- Integrations
- IDE Plugins
- MCP Server
- Pup CLI
- Agent Directory
- API
- Marketplace
- DORA Metrics
- Customers
- Pricing
- Solutions
- Financial Services
- Manufacturing & Logistics
- Healthcare/Life Sciences
- Retail/E-Commerce
- Government
- Education
- Media & Entertainment
- Technology
- Gaming
- Amazon Web Services Monitoring
- Azure Monitoring
- Google Cloud Monitoring
- Oracle Cloud Monitoring
- Kubernetes Monitoring
- Red Hat OpenShift
- Pivotal Platform
- OpenAI
- SAP Monitoring
- OpenTelemetry
- Application Security
- Cloud Migration
- Monitoring Consolidation
- Unified Commerce Monitoring
- SOAR
- DevOps
- FinOps
- Shift-Left Testing
- Digital Experience Monitoring
- Security Analytics
- Compliance for CIS Benchmarks
- Hybrid Cloud Monitoring
- Edge Device Monitoring
- Real-Time BI
- On-Premises Monitoring
- Log Analysis & Correlation
- CNAPP
Industry
Technology
Use Case
- About
- Blog
- Docs
- Login
- Get Started
Observability
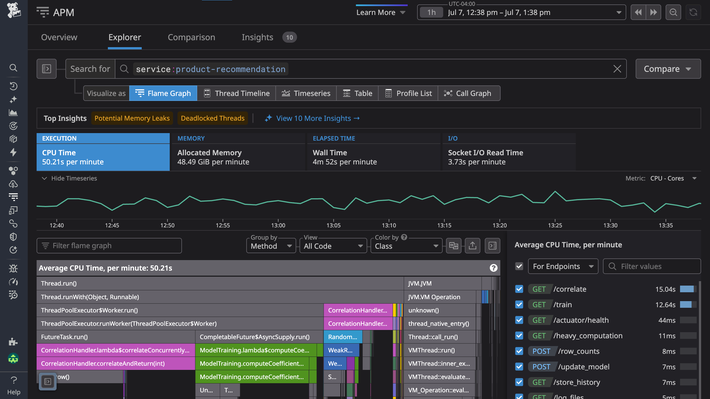
Continuous Profiler
Make your production code lean and cost-effective with always-on profiling