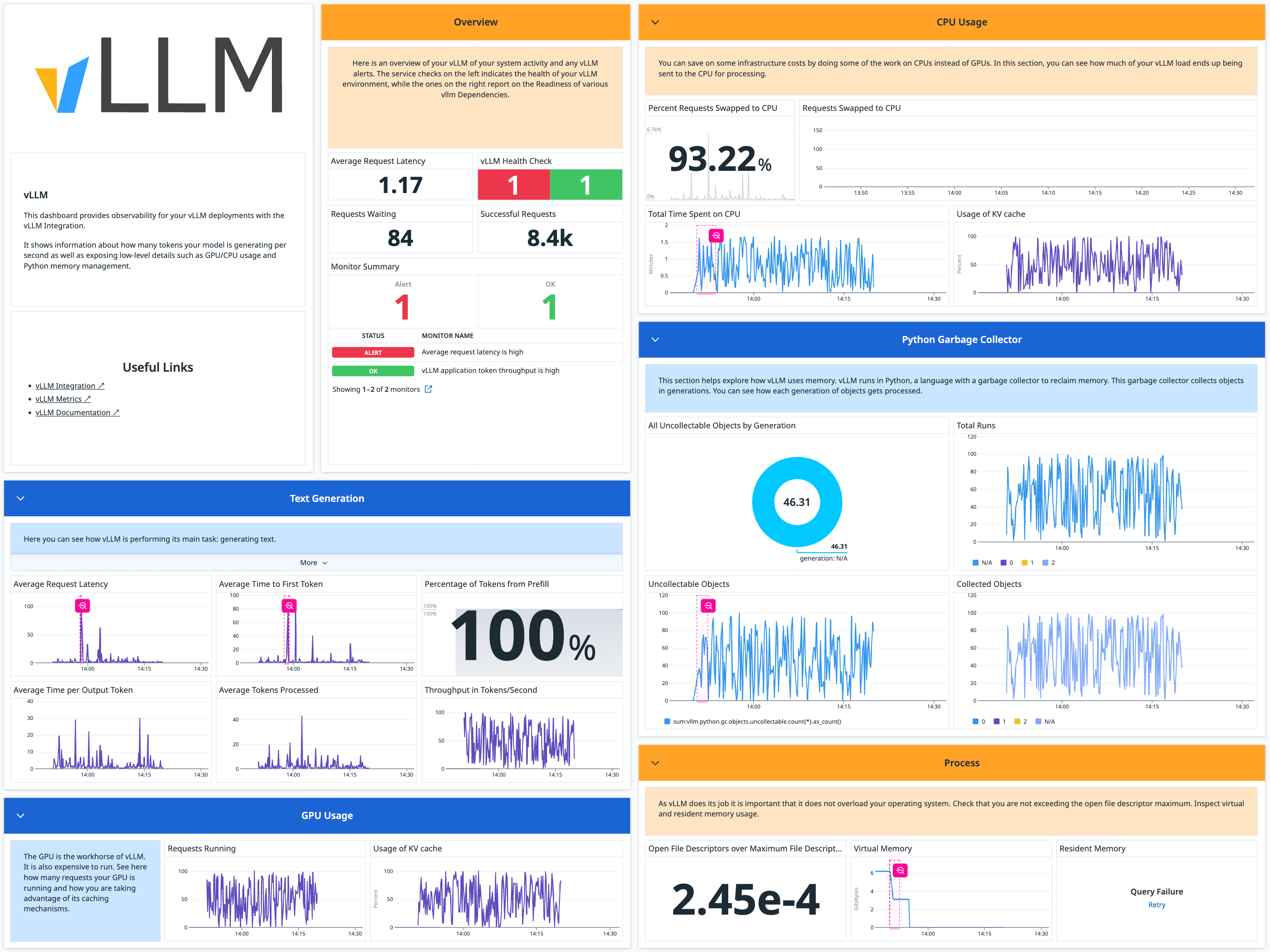
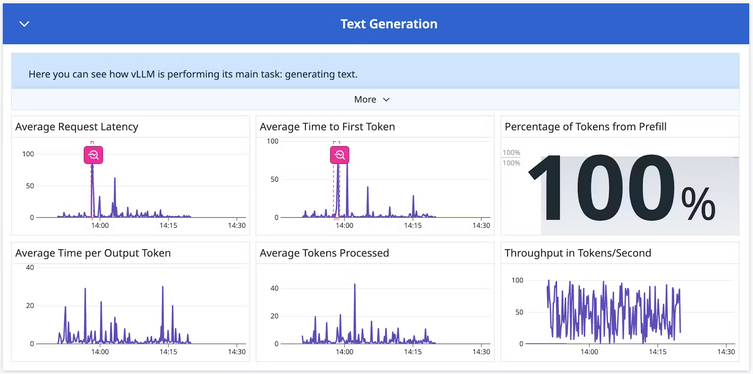
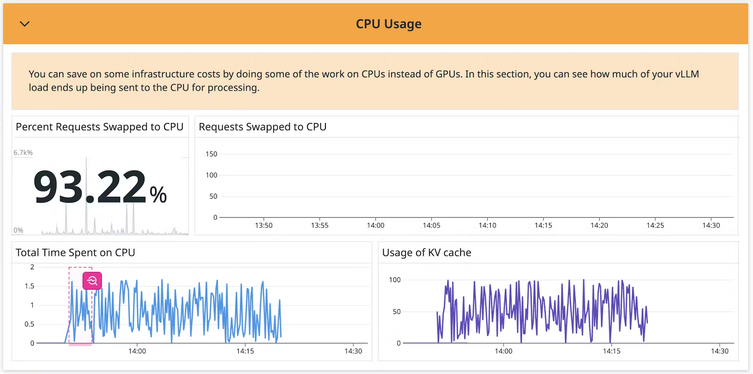
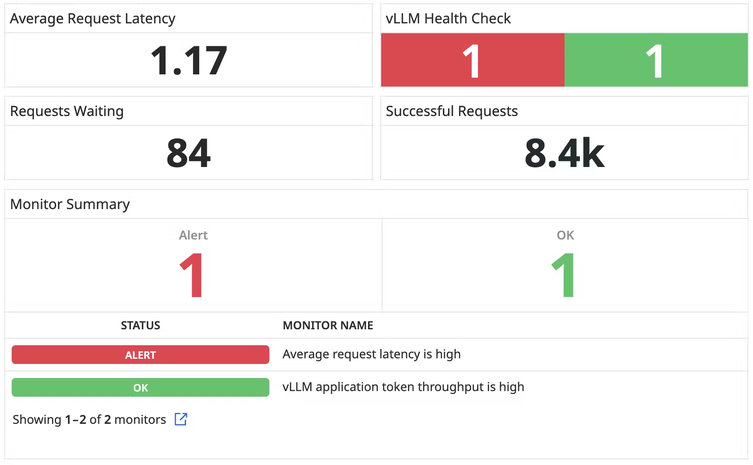
Generative AI Monitoring
Monitor your Foundation Model usage, API performance, and error rate with runtime metrics and logs.
Next-generation ML Monitoring
Monitor and your entire machine learning stack with Datadog.
AWS Trainium & Inferentia
Monitor and optimize deep learning workloads running on AWS AI chips
OpenAI
Monitor token consumption, API performance, and more.
NVIDIA DCGM Exporter
Gather metrics from NVIDIA’s discrete GPUs, essential to parallel computing.
Thousands of Customers Love & Trust the Datadog Platform
ML Monitoring Resources
Learn about how Datadog can help you monitor your entire AI stack.