- 제품
인프라
애플리케이션
데이터
로그
보안
- 개요
- Code Security
- Software Composition Analysis
- Static Code Analysis (SAST)
- Runtime Code Analysis (IAST)
- IaC Security
- Cloud Security
- Cloud Security Posture Management
- Cloud Infrastructure Entitlement Management
- Vulnerability Management
- Compliance
- Cloud SIEM
- Workload Protection
- App and API Protection
- Sensitive Data Scanner
- Security Labs Research
- Open Source Projects
- Secret Scanning
Digital Experience
Software Delivery
Service Management
AI
플랫폼 기능
- Bits AI Agents
- Metrics
- Watchdog
- Alerts
- Dashboards
- Notebooks
- Mobile App
- Fleet Automation
- Governance Console
- Access Control
- Incident Response
- Case Management
- Event Management
- Workflow Automation
- App Builder
- Cloudcraft
- CoScreen
- Teams
- OpenTelemetry
- Integrations
- IDE Plugins
- MCP Server
- Pup CLI
- Agent Directory
- API
- Marketplace
- DORA Metrics
- 고객
- 요금
- 솔루션
- 금융 서비스
- 제조 및 물류
- 헬스케어/생명과학
- 리테일/e커머스
- 정부
- 교육
- 미디어 & 엔터테인먼트
- 기술
- 게임
- Amazon Web Services Monitoring
- Azure Monitoring
- Google Cloud Monitoring
- Oracle Cloud Monitoring
- Kubernetes Monitoring
- Red Hat OpenShift
- Pivotal Platform
- OpenAI
- SAP Monitoring
- OpenTelemetry
- Application Security
- 클라우드 마이그레이션
- 모니터링 통합
- 통합 커머스 모니터링
- SOAR
- DevOps
- FinOps
- Shift-Left Testing
- Digital Experience Monitoring
- Security Analytics
- Compliance for CIS Benchmarks
- Hybrid Cloud Monitoring
- Edge Device Monitoring
- Real-Time BI
- On-Premises Monitoring
- Log Analysis & Correlation
- CNAPP
산업
기술
사용 사례
- 소개
- 블로그
- 문서
- 로그인
- 시작하기
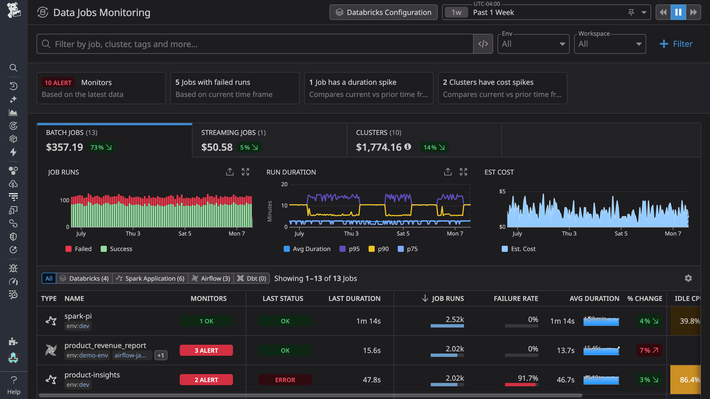
Data Observability
Jobs Monitoring
데이터 파이프라인의 작업을 모니터링, 트러블슈팅, 비용 최적화