
What is log aggregation?
Log aggregation is the process of collecting, standardizing, and consolidating log data from across an IT environment in order to facilitate streamlined log analysis. Without log aggregation, developers would have to manually organize, prepare, and search through log data from numerous sources in order to extract useful information from it. In this article, we’ll discuss how log aggregation works, why it’s important, and what you should consider when choosing a log aggregation solution.
How does log aggregation work?
Logs include a wealth of information that can help developers monitor activity and troubleshoot issues within their system, but they must be systematically collected and standardized in order to provide the most value. Log aggregation is one of the early stages in the log management process, and it can be accomplished through several different methods:
- File replication
Log files can be copied to a central location using tools like rsync or cron. While these commands can relocate log files, they do not support real-time monitoring.
- Syslog
Logs can be directed to a central location using a syslog daemon (also known as a log shipper), which can work with various syslog message formats. This is a relatively simple method of aggregating logs, but it can be difficult to scale.
- Automated pipelines
Log processing pipelines incorporate syslog daemons or agents to systematically ship, parse, and index logs on a continuous basis. Some pipeline tools are also coupled with additional log aggregation features, such as analysis or alerting.
Automated pipelines have become the preferred choice for log aggregation due to their flexibility, scalability, and compatibility with modern monitoring solutions. Pipelines perform many tasks, including:
- Parsing key:value pairs
Processing pipelines allow you to apply dynamic parsing rules to more easily coerce log data into key:value pairs. This allows you to view your log data in a standardized format, making it easier to search and analyze.
- Extracting and standardizing key attributes
Logs enter the pipeline from many sources and in many different formats, but they often contain similar fields, such as date, time, or status. With log aggregation, you can ensure that these fields appear consistently across your entire ingested log stream.
- Performing more complex transformations such as multi-line log aggregation, scrubbing, or masking sensitive data
Pipelines can be configured to treat multi-line logs as single events, which makes them easier to interpret and reduces logging overhead. Pipelines can also automatically anonymize sensitive data, such as a user’s login credentials.
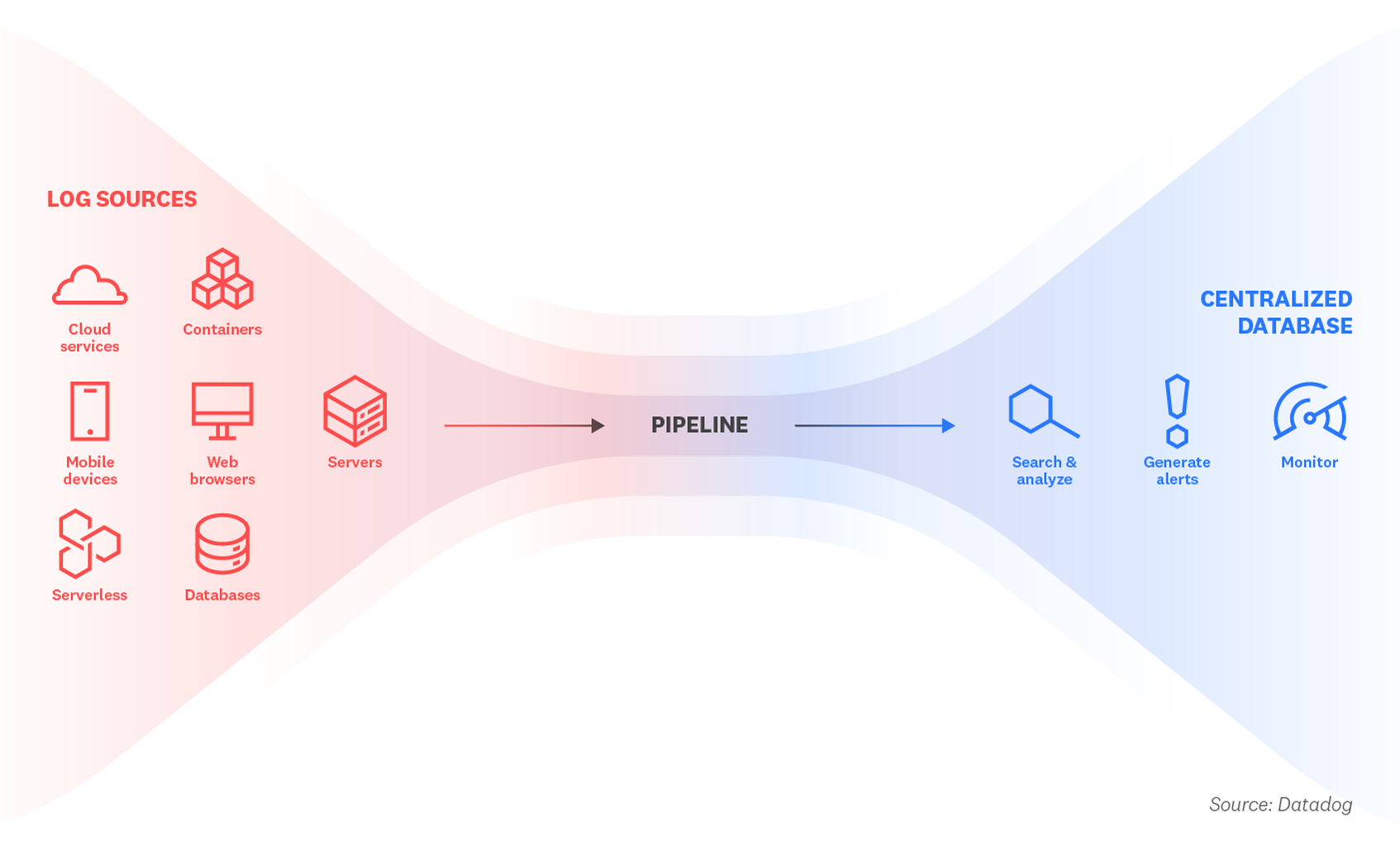
After logs have been processed, they are indexed and stored in a centralized database. This makes it easier for end users to search, group, and analyze them in order to identify patterns or issues.
Why is log aggregation important?
An effective log aggregation strategy enables developers to save precious time during outages and proactively identify patterns in system activity. After logs have been aggregated, teams can:
- Search, filter, and group logs
Log aggregation enables teams to use standardized facets in order to zero in on specific subsets of activity, which streamlines the log analysis process.
- Troubleshoot in response to production incidents
Logs capture important information about system health that is crucial during outages or issues. An effective log aggregation strategy reduces manual work in these time-sensitive situations so developers can identify root causes faster.
- Collaborate with others across the organization
Log aggregation breaks down organizational silos and improves visibility by enabling multiple teams to access the same data in a centralized platform.
- Perform real-time monitoring
Once logs have been aggregated, teams can generate metrics from log attributes in order to visualize long-term trends and alert on log data.
Unify logs across data sources with Datadog’s customizable naming convention
What to look for when choosing a log aggregation tool
When deciding on a log aggregation strategy, consider choosing a solution that is coupled with log aggregation and includes the following features:
- A robust pipeline library
Some tools come equipped with out-of-the-box pipelines for each log source, which can be customized to fit your organization’s needs.
- Correlation with other telemetry
Some log aggregation tools automatically enrich your logs with metadata, such as tags or trace IDs, which can help you correlate your logs with other telemetry from across your stack.
- Security monitoring
Tools that include security monitoring allow you to apply threat detection rules to your entire ingested log stream, which can alert you to concerning activity anywhere in your system.
- Granular control over indexing and storage
Certain platforms allow you to ingest all of your logs while only indexing and storing the ones that matter most. This helps you avoid the tradeoffs between cost and visibility that are typically associated with log aggregation.
- Live tailing
Tools that provide live tailing enable you to monitor your entire ingested log stream in real time, so you can observe crucial system activity such as deployments without having to index everything.
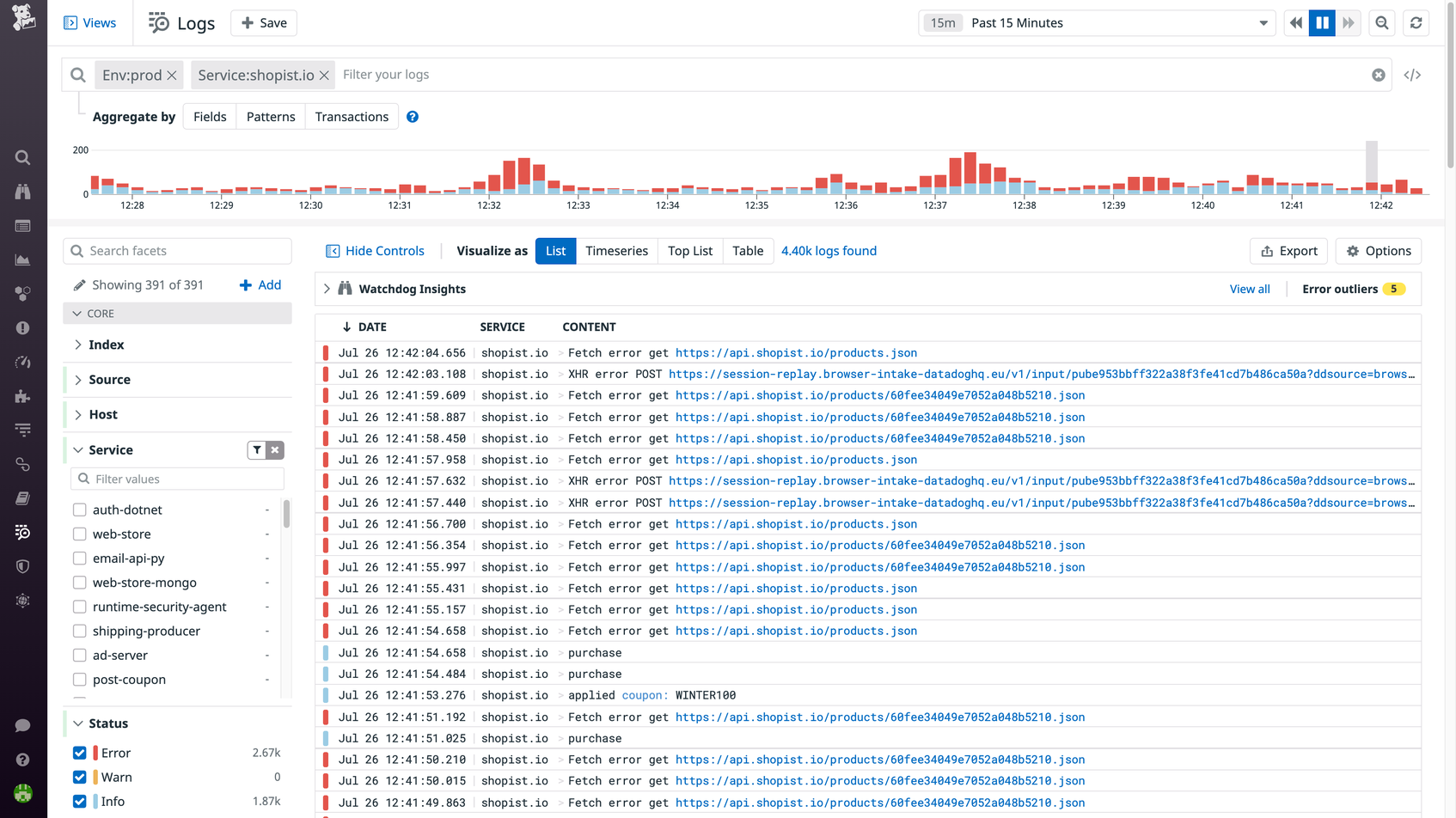
Datadog Log Management includes all of these features, allowing teams to transform disparate streams of raw log data into centralized, structured assets. Datadog’s out-of-the-box processing pipelines standardize key attributes across multiple log streams in order to facilitate sophisticated analysis, and customers can leverage Live Tail and Logging without Limits™ to choose which logs are indexed and stored—without losing visibility. Finally, Datadog’s unified platform enables teams to correlate logs with other telemetry from more than 1,000 integrations, so they can optimize performance, troubleshoot effectively, and provide the best possible experience to their users.


