What is eBPF?
Extended Berkeley Packet Filter (eBPF) is a Linux kernel technology enabling engineers to build programs that run securely in kernel space. By providing safe access to the innermost workings of the operating system, eBPF lets developers tackle a wide range of challenges related to networking, observability, and security.
Because a bug or error in a kernel program can lead to crashes, data corruption, or other unexpected behaviors, access to kernel space is typically restricted to the operating system and specialized processes. User applications are blocked from directly accessing kernel space to protect the system and hardware from potential harm.
But this tight security also prevents user applications from detecting many low-level networking and security events that are visible only at the kernel level, potentially leaving teams without tools to detect or take action on these events.
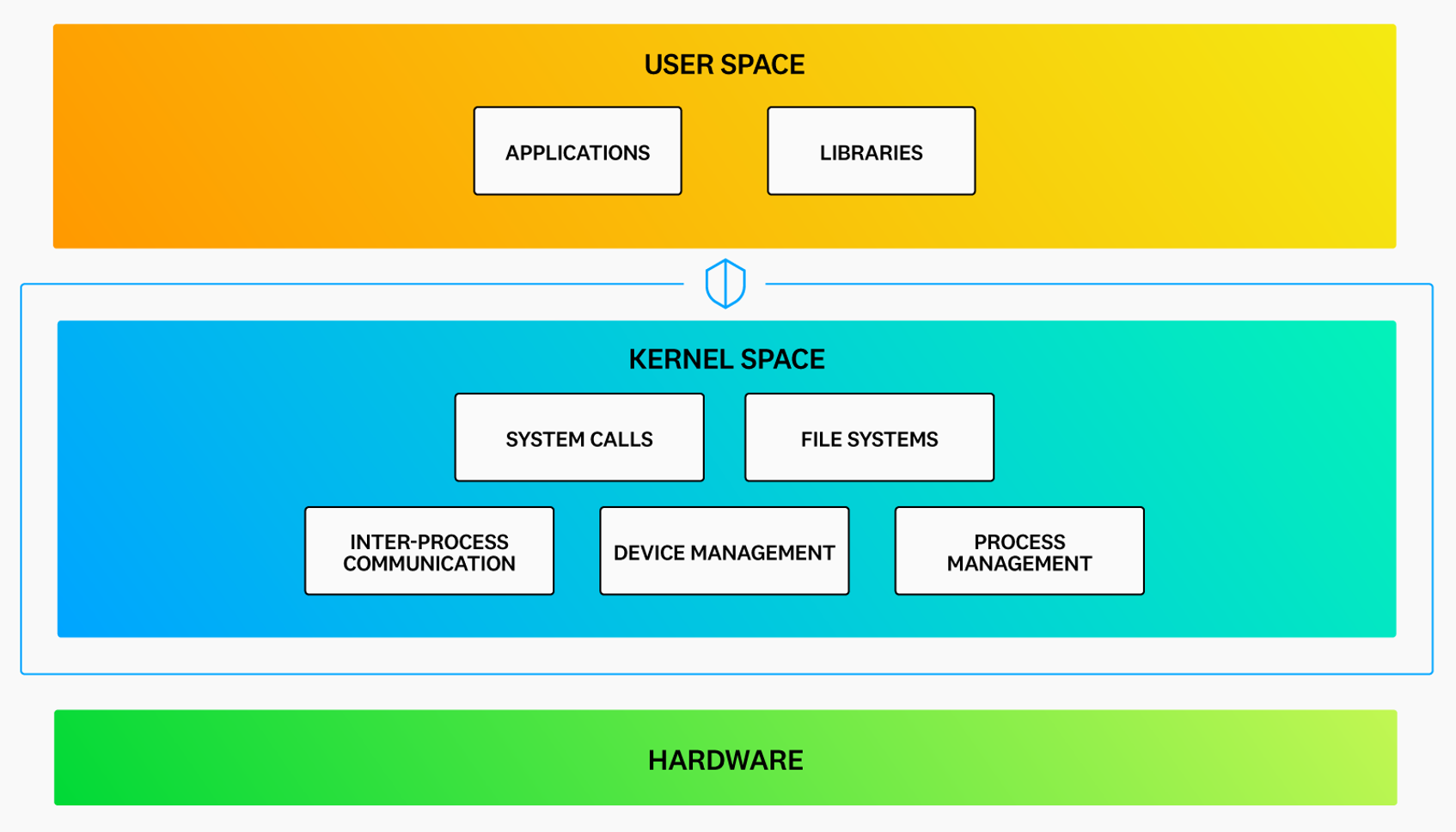
eBPF resolves this dilemma by allowing users to run programs in a protected environment, within kernel space, that verifies the safety of the code before allowing it to execute. This “sandbox” approach allows programs deeper levels of access into kernel operations without increasing the risk of harm to the system. With this privileged level of access, eBPF programs are often used for tasks such as detecting malware, debugging applications, and inspecting traffic in a more granular way than is possible with traditional user-space applications.
What problems does eBPF solve?
To better answer this question, it helps to know a little bit about the origins of eBPF, and how it developed from the original Berkeley Packet Filter, or BPF.
BPF was introduced in 1993 as a way to control and filter traffic. Before BPF, packet filtering tools were restricted to user space, which made these applications CPU-intensive and limited their capabilities. BPF offered a unique alternative because it operated as an in-kernel virtual machine (VM) that allowed packet filtering within normally isolated kernel space.
Despite its innovations, the original BPF was adopted in a limited way—mainly as the underlying technology for a popular utility called tcpdump. Then, the BPF project gained new life when it needed to be updated for modern 64-bit processors. As part of this update, BPF was also extended by removing important limitations to its original functionality, enabling it to solve new problems outside of packet filtering that engineers were beginning to face.
Security challenges
For example, organizations needed more effective strategies to combat threats that were increasingly evading anti-malware software and firewalls. What’s more, whereas many organizations had once considered security strategy mainly in the context of a strong perimeter defense around the corporate network, the new reality of mixed cloud environments made it clear that there was no longer a clear perimeter to defend. Alternative security mechanisms were needed that were powerful but efficient enough to run anywhere and everywhere, not just at the network perimeter.
Need to improve applications faster
Other challenges emerged in parallel with security concerns. For example, an increasingly competitive environment was shortening development cycles and putting pressure on engineering teams to find and fix bugs faster. This trend led to the need for more granular application tracing, along with faster debugging. But Linux lacked a global mechanism to perform end-to-end tracing of running applications.
These challenges could be addressed by directly updating the Linux kernel with more powerful features, but doing so was (and still is) difficult to achieve in practice. To gain new types of access to kernel-level functions, one has the option of waiting for the Linux community to build and approve those new capabilities in the kernel, but this process normally takes many years. Alternatively, one has the option of modifying the kernel source code in one’s own Linux fork, but this solution is complicated and risky to implement because kernel modifications can pose a serious risk to the stability of a system. Yet another option would be to write loadable kernel modules (LKMs) to provide the desired functionality. But LKMs are also complex, risky, and typically require fairly large teams to develop. Additionally, LKMs require constant maintenance because any Linux kernel version upgrade can inadvertently break the module.
How eBPF solves these problems
BPF’s capabilities were updated and radically expanded in 2014 to solve these problems.
The result of this BPF expansion—extended BPF or eBPF—allows programs broad access to kernel functions and system memory, but in a protected way. eBPF lets you gather detailed information about low-level networking, security, and other system-level activities within the kernel. Better yet, it works without requiring direct modifications to kernel code.
Unlike programs that run in user space, eBPF programs are inherently more efficient and potentially more powerful because they can see and respond to nearly all operations performed by the operating system. This means that, for the purposes of application tracing, eBPF programs also provide the advantage of not requiring any code instrumentation. And because eBPF supports event-driven functions, it allows tracing to be performed efficiently because CPU cycles are used only when needed.
In summary, eBPF programs allow safe and efficient access into kernel operations by:
Providing built-in hooks for programs based on system calls, kernel functions, network events, and other triggers.
Providing a mechanism for compiling and verifying code prior to running, which helps ensure security and stability of the system.
Offering a more straightforward way to enhance kernel functionality than is possible through LKMs, thereby allowing even small teams to efficiently develop safe programs that run in kernel space.
Where is eBPF used?
eBPF is great for situations needed to resolve challenges—typically related to networking, security, or observability—where traditional tools can’t run with enough efficiency or detect events with enough granularity. Because eBPF programs are event-based, they can be used to enable efficient but complex processing of network traffic or to design detailed but lightweight security and observability features. For example, eBPF has been used to build tools that give access to low-level system events for the purposes of security or forensics, that perform continuous profiling of applications, or that let you run tracing and profiling scripts on a Kubernetes cluster—all in an extremely resource-efficient way.
How does eBPF work?
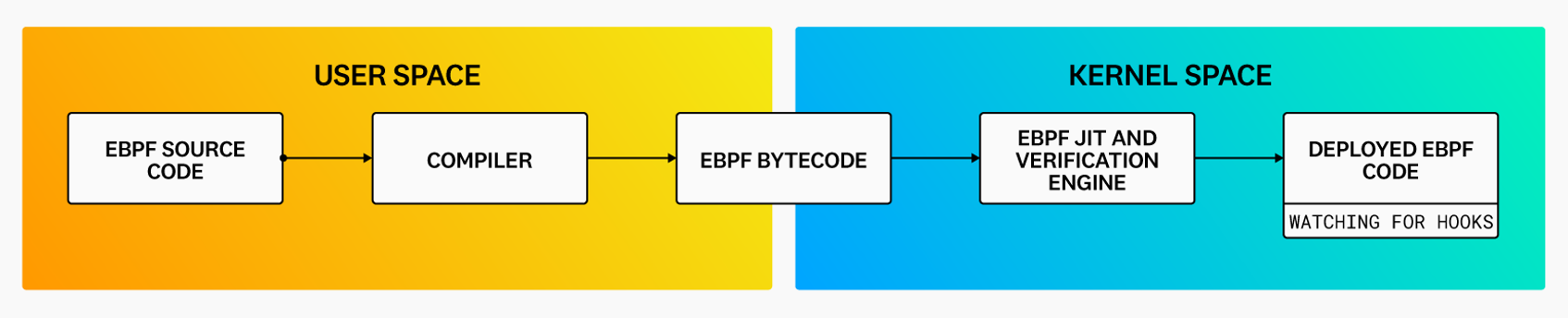
eBPF lets you run programs isolated in an in-kernel execution environment called the eBPF virtual machine (eBPF VM). To prepare an eBPF program to run in this environment, a developer first writes the program, converts the code to intermediary bytecode by using a compiler suite (such as LLVM), identifies a system event (called a “hook”) to attach the program to, and then loads the program into the Linux kernel by using one of the available eBPF libraries.
Once loaded into the kernel, the program is automatically verified through the verification engine, and its bytecode is compiled—via a just-in-time (JIT) compiler—into a machine-specific instruction set. Thanks to this latter step, the eBPF program can run with the same level of efficiency as a natively compiled app.
The eBPF code at this stage is ready to be invoked by the pre-specified hook, such as a system call or network event. After the eBPF code is triggered, it can call special functions called “helpers” that can perform a wide range of tasks, including searching and updating key-value pairs in tables, generating random numbers, redirecting network packets, and more. For security and stability reasons, these helper functions must be pre-defined by the kernel, but the list of helper calls available to eBPF is quite large. As a result, thanks to eBPF, developers can create projects covering a wide array of use cases without having to modify kernel source code—and therefore without risking the security or reliability of the kernel.
How do I get started with eBPF?
There are several websites and tools available to help developers get started with eBPF.
eBPF.io is an excellent open-source community and website for learning more about eBPF. Organizations looking for a jumpstart can find a wide range of open-source and proprietary eBPF-based applications available from ebpf.io/applications or from Github.
The ebpf.io/infrastructure site provides links to infrastructure tools for getting started on creating, compiling, and running eBPF programs, including eBPF Runtime, various compilers, and even an emerging eBPF Runtime for Windows that lets you run existing eBPF projects on top of Microsoft Windows®.
The BCC toolkit and library simplifies writing eBPF applications.
And if you’re ready to build an app for capturing network traffic, see this Datadog tutorial.
How to enjoy the benefits of eBPF today
Teams can use eBPF directly to write applications that are allowed privileged levels of access into kernel operations. However, even if you’re not a developer, you can still benefit from using products, including several Datadog offerings, that draw upon eBPF technology. An example of this type of product is Universal Service Monitoring, which uses eBPF to automatically discover, map, and monitor services and dependencies without requiring you to instrument any code. Another example is Cloud Network Monitoring, which uses eBPF to provide detailed but lightweight visibility into the network traffic that flows across your infrastructure. Finally, Cloud Security uses eBPF to automatically collect data for the purposes of detecting security anomalies—again without requiring any code to be modified and without significantly affecting performance.
In the future, Datadog plans to add more features and capabilities that, through eBPF, help give organizations even better visibility into the health, performance, and security of their services and infrastructure. More broadly, across the information technology sector, eBPF is expected to play a growing role in helping organizations solve some of the most pressing problems related to observability.