What Is a Flame Graph?
A flame graph visualizes a distributed request trace and represents each service call that occurred during the request’s execution path with a timed, color-coded, horizontal bar. Flame graphs for distributed traces include error and latency data to help developers identify and fix bottlenecks in their applications. In this article, we’ll explain how to interpret a flame graph, walk through an example, and describe some other ways to visualize distributed traces.
Why Are Flame Graphs Important?
In microservice architectures, applications are composed of multiple, independently deployable services. Developers use distributed tracing to track a request as it flows through disparate services. A tracing tool collects latency and error data for the full request, as well as for each service call along the request’s pathway. A monitoring tool receives this data and displays it in the form of a flame graph.
Flame graphs allow developers to see the relationships between service calls and which parts of a request’s journey exhibited unusually high latency or errors. Sometimes, errors or high latency in one service can impact other, dependent services, so analyzing a flame graph can help you keep tabs on the performance of your application.
How to Interpret a Flame Graph (with Example)
Application monitoring tools use flame graphs to visualize a request’s execution path and unify its distinct service calls into a single distributed trace. Each span, or bar, shown on the flame graph represents an individual unit of work, such as an API call or database query, that occurred as the request was being executed. The spans are arranged in a particular order in the flame graph.
When a request is first initiated, a parent span is created, along with a trace ID. The parent span appears at the very top of the flame graph because it represents the first service call in the request’s execution path. The parent span triggers the creation of one or more child spans, which represent subsequent service calls that occurred to fulfill the request. Some child spans—called top-level spans—are entry points to new services. A child span may trigger the creation of and act as the parent for subsequent spans.
The x-axis of a flame graph measures the duration of each span in the request, so wider spans took more time to complete. The y-axis measures the depth of the call stack (i.e., the number of service calls). Clicking a span on the flame graph typically brings up duration and error data for that service call. Depending on the monitoring tool you’re using, you may also be able to navigate from the flame graph to related metrics, logs, and other contextual telemetry data.
Here’s an example of a flame graph:
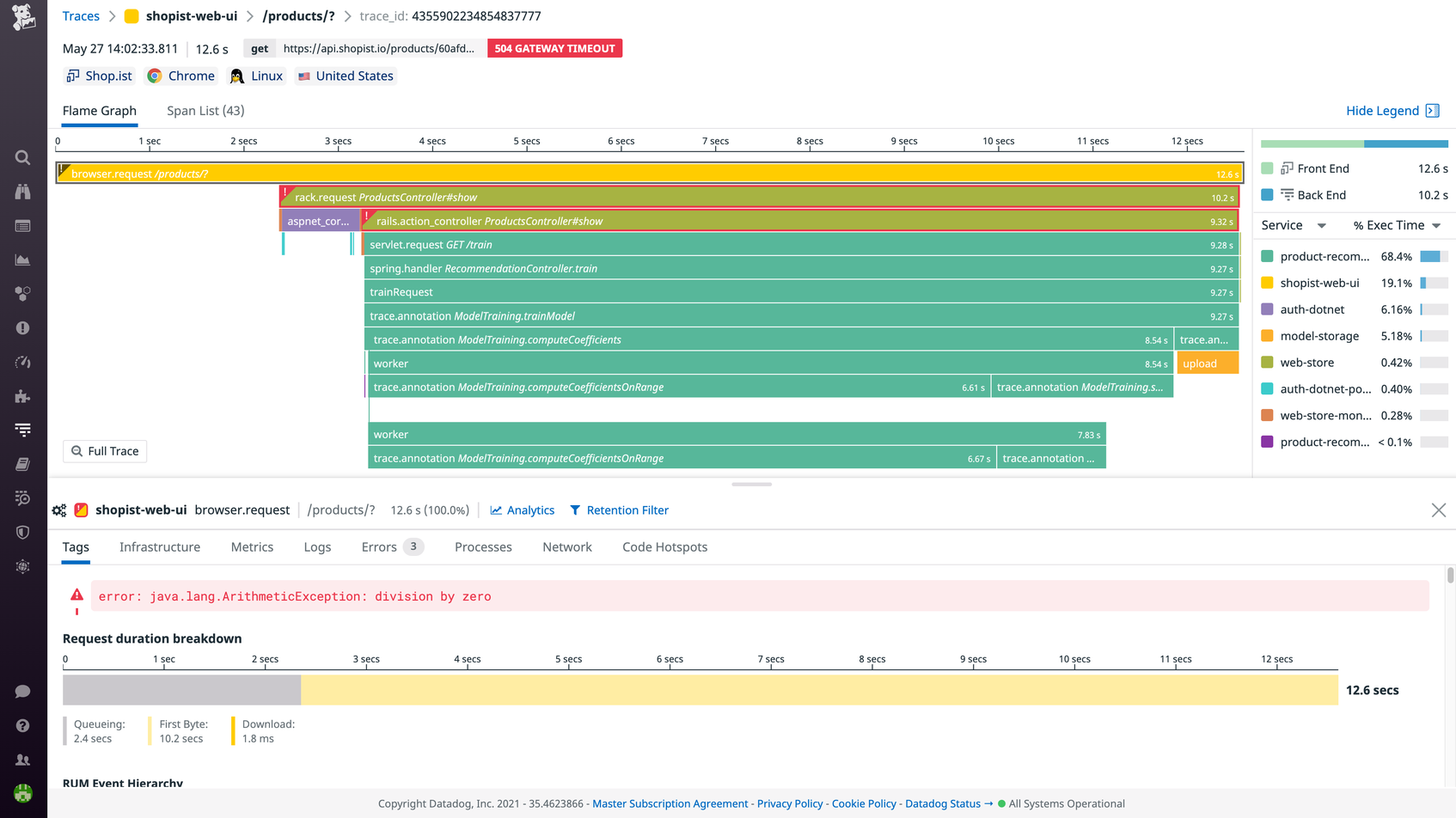
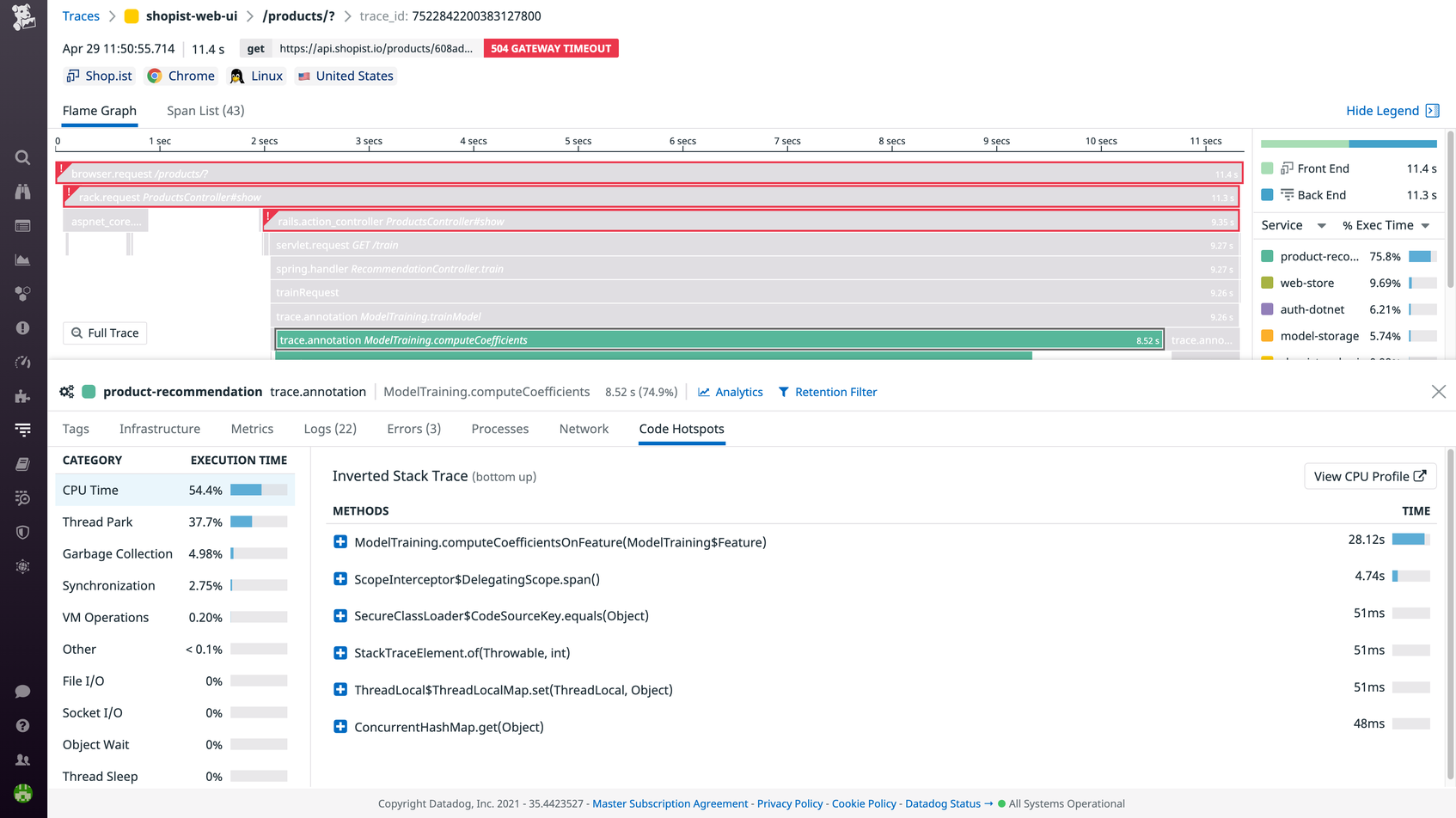
This flame graph visualizes the execution path of a request that was generated when a user of an e-commerce web application clicked a button to browse a specific product category. It took 12.6 seconds for the requested web page to return a response to the user. Of that time, 10.2 seconds were spent in the backend, indicating that the high latency was clearly related to a backend issue. Each color in the flame graph represents a different service involved in fulfilling this request.
Here’s a more detailed interpretation of the flame graph:
The top span (yellow) is the parent span and represents the user session that initiated the frontend request from the browser.
The second span from the top (light green) is a top-level child span. It represents a call to a backend service that was involved in rendering the requested product information and images for the user. Below that, additional child spans show other backend service calls involved in fulfilling the request. For example, the purple span is a user authentication service.
The bright green spans indicate that the request spent a lot of time on backend computations. Several division by zero errors occurred, forcing the service to repeat certain calculations that increased the time spent in that service and the overall latency of the request. The errors propagated through the services that are marked in red. Eventually, the request timed out, returning a 504 Gateway Timeout error.
By clicking the tabs beneath the flame graph, you can find related metrics, logs, network performance data, code hotspots, and other contextual information to debug the error. When analyzing a flame graph, it’s worth investigating any spans that have a long duration or that contain errors. In some monitoring platforms, you can see the percentage of execution time that the request spent in each service and focus your troubleshooting efforts on services that took up the bulk of time.
Other Ways to Visualize Distributed Traces
Flame graphs are the most common way to visualize distributed traces, but other methods include the following:
- Span list
A span list is a sequential list of each service call, API call, or database call that occurred as the request was being executed.
- Trace waterfall
Each span in a trace waterfall is collapsible and expandable, so you can get even more detail than a flame graph and see exactly which commands or queries took the longest.
- Trace map
A trace map uses arrows to show the connections between all spans in a distributed trace. Each span is labeled with duration, errors, and other relevant data from the service. This method of visualization allows you to quickly understand the causal relationships between the services involved in executing the request.
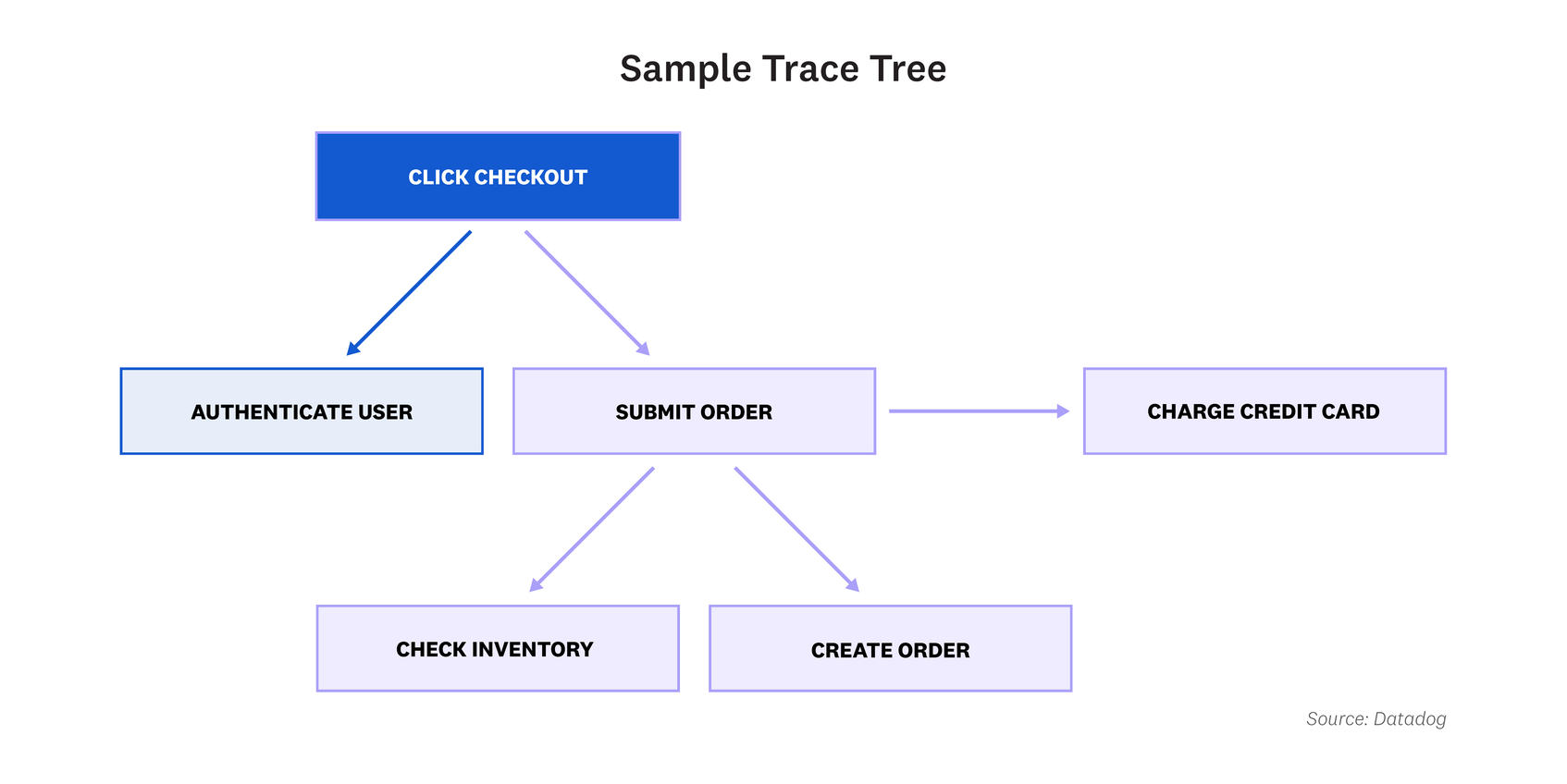
- Trace tree
A trace tree is similar to a trace map, but the journey is visualized vertically instead of horizontally. The top branch of the tree is the parent span, and the other branches are child spans. The lines connecting the branches show the causal relationship between services.
- Sunburst diagram
A sunburst diagram consists of a set of rings surrounding a center circle. The circle is the parent span, and the rings are spans that represent service calls. The layering of the rings demonstrates the service relationships. Inner rings are parent spans to outer rings. The extent to which each ring wraps around its parent corresponds to the duration of that service call.
Ultimately, any of these methods can be used to visualize a distributed request trace, and the choice depends on a team’s preferences and the specific use case involved.
Profiling Flame Graphs vs. Tracing Flame Graphs
In addition to visualizing distributed traces, flame graphs can also visualize code profiling data. A code profiler analyzes how much time your application code spent on garbage collection, CPU utilization, memory allocation, locks, input/output operations, and other tasks. When coupled with distributed tracing, code profiling provides additional detail on what may have caused a request to slow down or experience an error. Profiling flame graphs, such as the example shown below, take data from the profiler and visualize the code paths and methods involved in fulfilling a request. The flame graph makes it clear whether specific parts of your codebase need to be optimized.
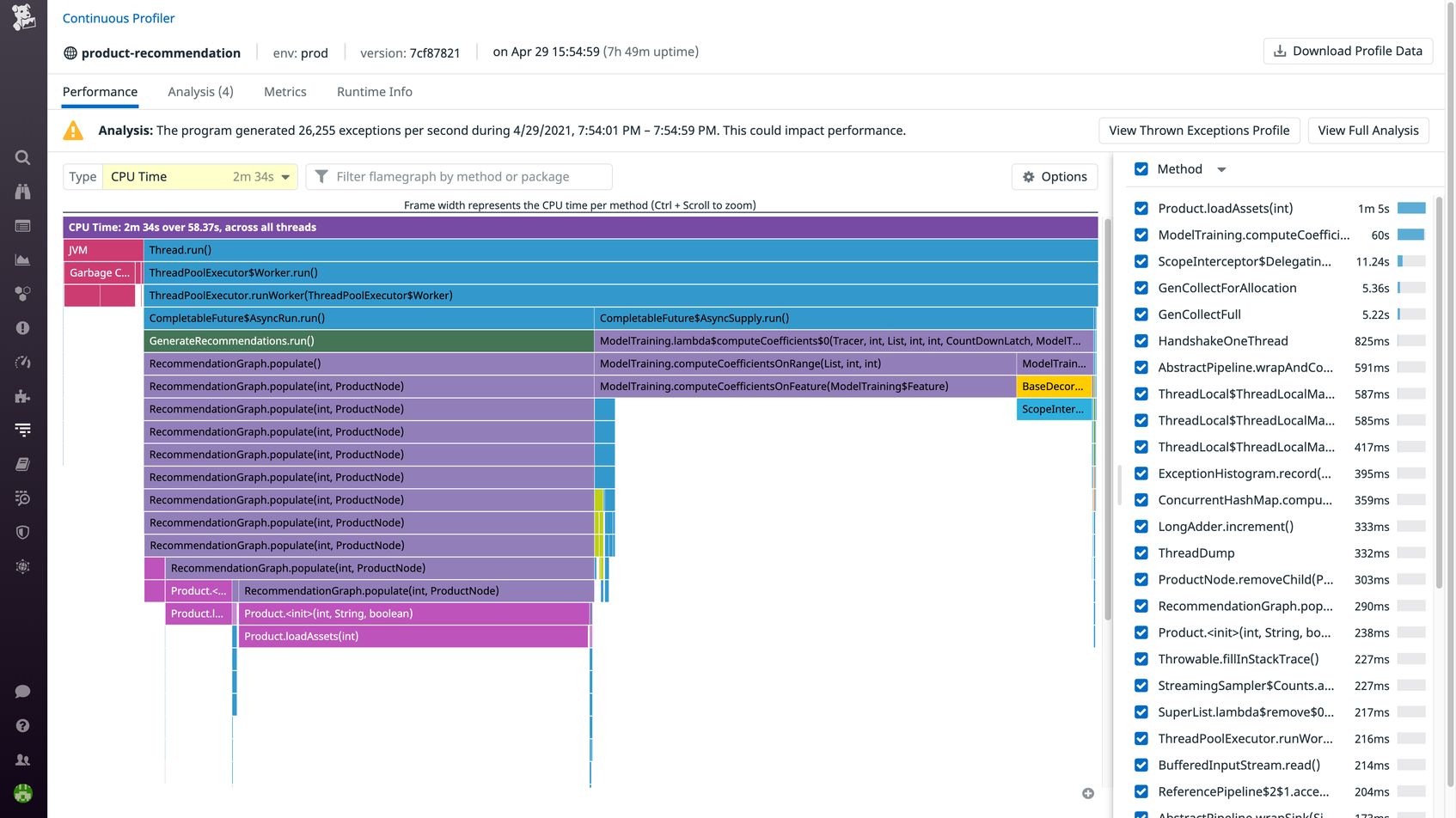
With Datadog Application Performance Monitoring and distributing tracing, you can track the path of requests across all of your services and identify the primary bottlenecks and errors. When you need to dig even deeper, you can correlate distributed traces with code profiles from Datadog Continuous Profiler. With color-coded flame graphs and easy access to contextual data, teams can quickly identify the root cause of performance problems and fix them.