What is Distributed Tracing?
Distributed tracing is a method of tracking application requests as they flow from frontend devices to backend services and databases. Developers can use distributed tracing to troubleshoot requests that exhibit high latency or errors.
How Distributed Tracing Works
Applications may be built as monoliths or microservices. A monolithic application is developed as a single functional unit. In microservice architecture, an application is broken down into modular services, each of which handles a core function of the application and is often managed by a dedicated team.
Microservices are used to build many modern applications because they make it easier to test and deploy quick updates and prevent a single point of failure. But it can be challenging to troubleshoot microservices because they often run on a complex, distributed backend, and requests may involve sequences of multiple service calls. By using end-to-end distributed tracing, developers can visualize the full journey of a request—from frontend to backend—and pinpoint any performance failures or bottlenecks that occurred along the way.
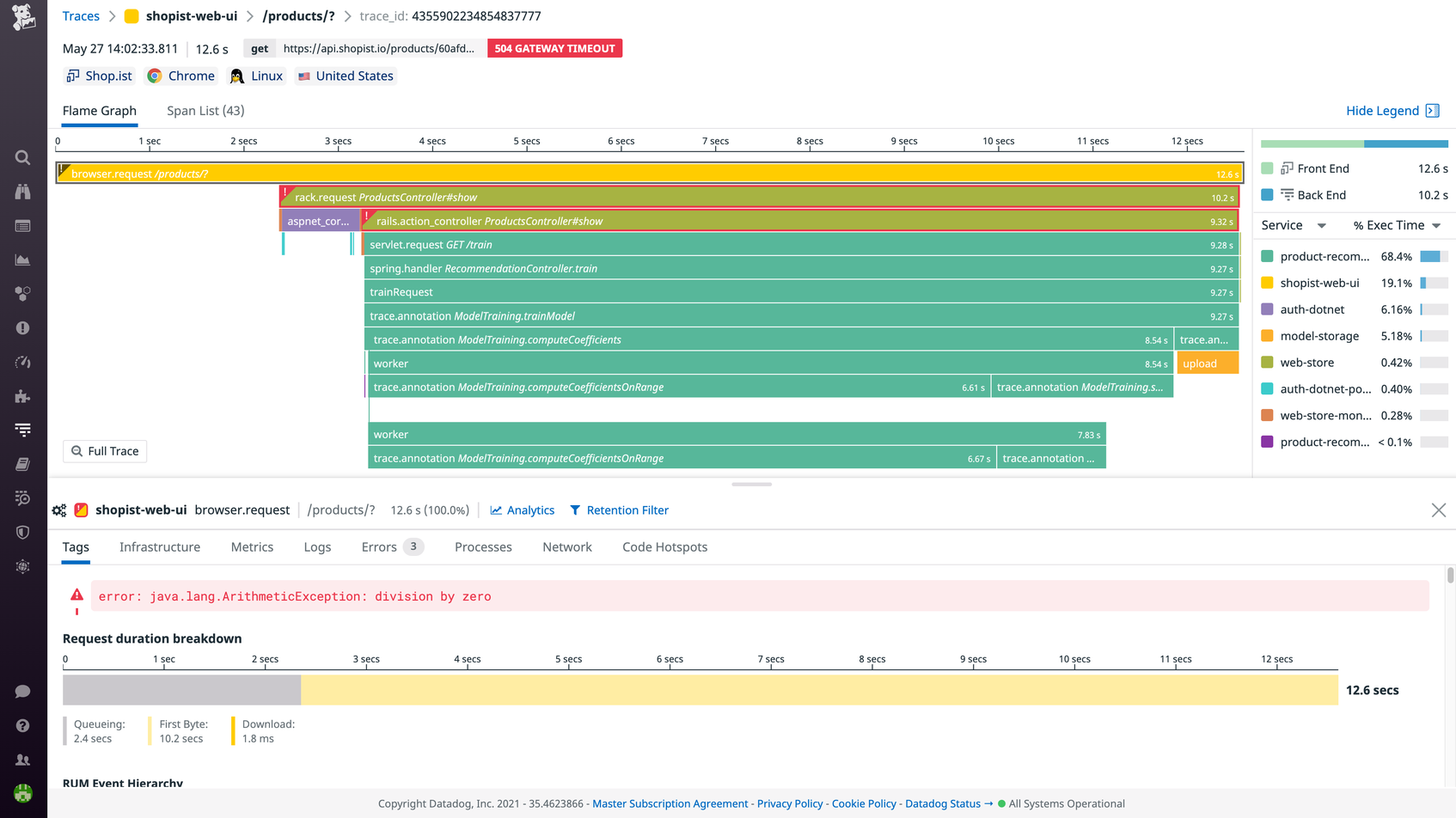
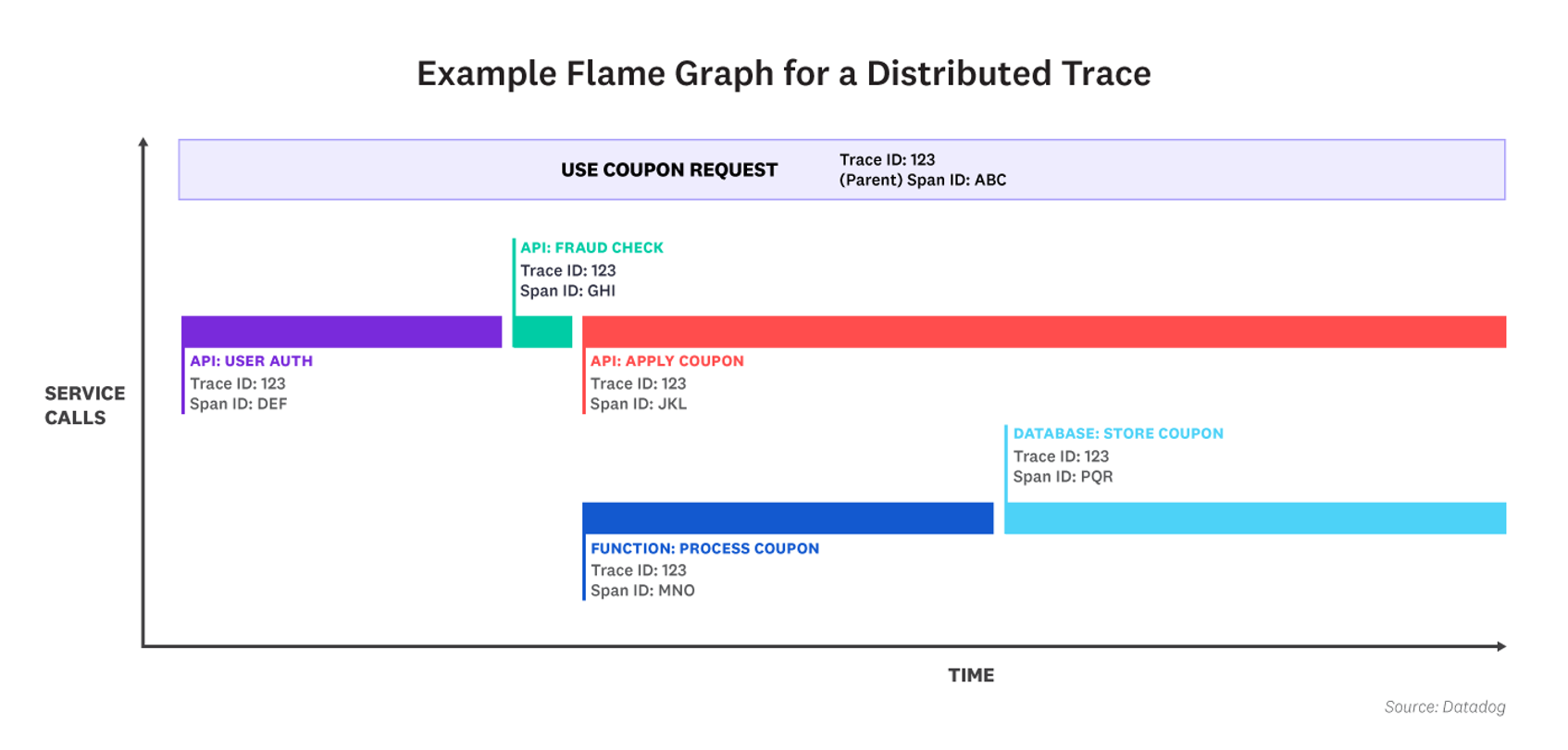
End-to-end distributed tracing platforms begin collecting data the moment that a request is initiated, such as when a user submits a form on a website. This triggers the creation of a unique trace ID and an initial span—called the parent span—in the tracing platform. A trace represents the entire execution path of the request, and each span in the trace represents a single unit of work during that journey, such as an API call or database query. Whenever the request enters a service, a top-level child span is created. If the request made multiple commands or queries within the same service, the top-level child span may act as a parent to additional child spans nested beneath it. The distributed tracing platform encodes each child span with the original trace ID and a unique span ID, duration and error data, and relevant metadata, such as customer ID or location.
Finally, all of the spans are visualized in a flame graph, with the parent span on top and child spans nested below in order of occurrence. Since each span is timed, engineers can see how long the request spent in each service or database, and prioritize their troubleshooting efforts accordingly. Developers can also use the flame graph to determine which calls exhibited errors.
Distributed Tracing vs. Logging
Both distributed tracing and logging help developers monitor and troubleshoot performance issues. Logs can originate from the application, infrastructure, or network layer, and each time stamped log summarizes a specific event in your system. For example, a container may emit a log when it runs out of memory. A distributed trace, on the other hand, occurs only at the application layer and provides visibility into a request as it flows across service boundaries. Using a trace, you can visualize the entire request path and determine exactly where a bottleneck or error occurred. To dig even deeper into the root cause of the latency or error, you may need to examine the logs associated with the request.
Distributed tracing for AWS Lambda with Datadog APM
Benefits and Challenges of Distributed Tracing
According to a survey conducted by O’Reilly in 2020, 61 percent of enterprises use microservice architecture. As that number grows, so does the need for distributed tracing and improved observability. Frontend engineers, backend engineers, and site reliability engineers use distributed tracing to achieve the following benefits:
- Reduce MTTD and MTTR
If a customer reports that a feature in an application is slow or broken, the support team can review distributed traces to determine if this is a backend issue. Engineers can then analyze the traces generated by the affected service to quickly troubleshoot the problem. If you use an end-to-end distributed tracing tool, you would also be able to investigate frontend performance issues from the same platform.
- Understand service relationships
By viewing distributed traces, developers can understand cause-and-effect relationships between services and optimize their performance. For example, viewing a span generated by a database call may reveal that adding a new database entry causes latency in an upstream service.
- Measure specific user actions
Distributed tracing helps measure the time it takes to complete key user actions, such as purchasing an item. Traces can help identify backend bottlenecks and errors that are harming the user experience.
- Improve collaboration and productivity
In microservice architectures, different teams may own the services that are involved in completing a request. Distributed tracing makes it clear where an error occurred and which team is responsible for fixing it.
- Maintain Service Level Agreements (SLAs)
Most organizations have SLAs, which are contracts with customers or other internal teams to meet performance goals. Distributed tracing tools aggregate performance data from specific services, so teams can readily evaluate if they’re in compliance with SLAs.
Despite these advantages, there are some challenges associated with the implementation of distributed tracing:
- Manual instrumentation
Some distributed tracing platforms require you to manually instrument or modify your code to start tracing requests. Manual instrumentation consumes valuable engineering time and can introduce bugs in your application, but the need for it is often determined by the language or framework that you want to instrument. Standardizing which parts of your code to instrument may also result in missing traces.
- Backend coverage only
Unless you use an end-to-end distributed tracing platform, a trace ID is generated for a request only when it reaches the first backend service. You won’t have visibility into the corresponding user session on the frontend. This makes it harder to determine the root cause of a problematic request and whether a frontend or backend team should fix the issue.
A high-throughput system may generate millions of spans per minute, which makes it hard to identify and monitor the traces that are most relevant to your applications. Fortunately, there are tools to help you surface the most useful performance data.
Distributed Tracing Tools
Modern distributed tracing tools typically support three phases of request tracing:
- Instrumentation
First, you modify your code so requests can be recorded as they pass through your stack. Modern tracing tools usually support instrumentation in multiple languages and frameworks, and may also offer automatic instrumentation, which does not require you to manually change your code.
- Data collection
Once your code has been instrumented, a distributed tracing tool will begin to collect span data for each request.
- Analysis and visualization
Finally, the spans are unified into a single distributed trace and encoded with business-relevant tags for analysis. Depending on the distributed tracing tool you’re using, traces may be visualized as flame graphs or other types of diagrams.
OpenTelemetry is the industry-standard open source platform for instrumentation and data collection. It offers vendor-neutral auto-instrumentation libraries and APIs that allow you to trace the end-to-end pathway and duration of requests. However, OpenTelemetry does not have any built-in analysis or visualization tools.
Zipkin and Jaeger are other open source tools with UIs that visualize distributed traces, but their main limitation is sampling. Since they sample traces, you may end up missing problems that are affecting your users.
Datadog offers complete Application Performance Monitoring (APM) and distributed tracing for organizations operating at any scale. You can use Datadog’s auto-instrumentation libraries to collect performance data or integrate Datadog with open source instrumentation and tracing tools.
Datadog Distributed Tracing allows you easily ingest traces via the Datadog libraries and agent or via OpenTelemetry, search and analyze them in real time, and use UI-based retention filters to keep all of your business-critical traces while controlling costs. Tail-based decisions ensure that you get continuous visibility into traces that show errors or high latency. And with Datadog’s unified platform, you can easily correlate traces with logs, infrastructure metrics, code profiles, and other telemetry data to quickly resolve issues without any context switching.