
What Is Auto-scaling?
Auto-scaling is a scaling technique you can apply to workloads hosted in a cloud environment. One of the major benefits of cloud-based hosting is that you can readily scale capacity to whatever extent is needed to support the demand for your service. Auto-scaling takes that advantage a step further. With auto-scaling, as the demand for a given workload changes over time, the amount of resources allocated to support that workload adapts automatically to meet your performance requirements.
Before auto-scaling was an option, scaling workloads was often challenging. Allocating resources manually to support a workload is inherently error-prone because it is difficult to precisely predict changes in demand or know how many resources are needed to handle those changes. This ambiguity can lead to costly over-provisioning on the one hand, or potential service disruptions due to under-provisioning on the other. Auto-scaling helps solve these problems by automatically increasing or decreasing the amount of resources assigned to your workload in direct proportion to the amount that demand also increases or decreases.
In this article, we’ll cover how auto-scaling works, why it is important, and when organizations are likely to use it. We’ll also look at the most common offerings for auto-scaling, along with potential challenges that accompany its implementation. Finally, we’ll discuss some important considerations for implementing an auto-scaling architecture effectively.
How Does Auto-scaling Work?
To understand auto-scaling, you should first consider that two types of scaling are possible:
- Scaling out/horizontal scaling
With horizontal scaling, you increase or decrease the number of nodes (or Kubernetes pods) participating in a given workload. An advantage of horizontal scaling is that it allows you to add a virtually unlimited amount of new capacity without affecting existing nodes or creating downtime. Compared to vertical scaling, it’s also a faster method of scaling capacity. However, not every application or workload can be scaled horizontally.
- Scaling up/vertical scaling
This type of scaling increases or decreases the available memory and/or processing power for existing nodes. For example, you can vertically scale two server nodes provisioned with 16 GB of RAM and 4 vCPUs to have 64 GB of RAM and 16 vCPUs apiece. In some cases, such as with relational databases that have been implemented without any sharding, vertical scaling has the advantage of being the only viable way to scale in response to increased demand.
However, a key downside of vertical scaling is that it does not lend itself as well to automation as horizontal scaling does.
This article will generally focus on horizontal auto-scaling, as that is what is typically used in automated scaling scenarios. (Teams are more likely to handle vertical scaling manually.)
When Does Auto-scaling Occur?
With auto-scaling, you typically configure resources to scale automatically in response to an event or metric threshold chosen by your organization. Engineers identify these events and metric thresholds as ones that most closely correlate with degraded performance.
For example, a developer could create a threshold of 70 percent memory usage for greater than four minutes. The developer could then additionally configure a response that would launch two additional instances every time this threshold is met or crossed. The developer could also define a minimum and maximum limit for scaling. What is the minimum acceptable number of nodes that should ever be used to run this workload, and conversely, what is the maximum?
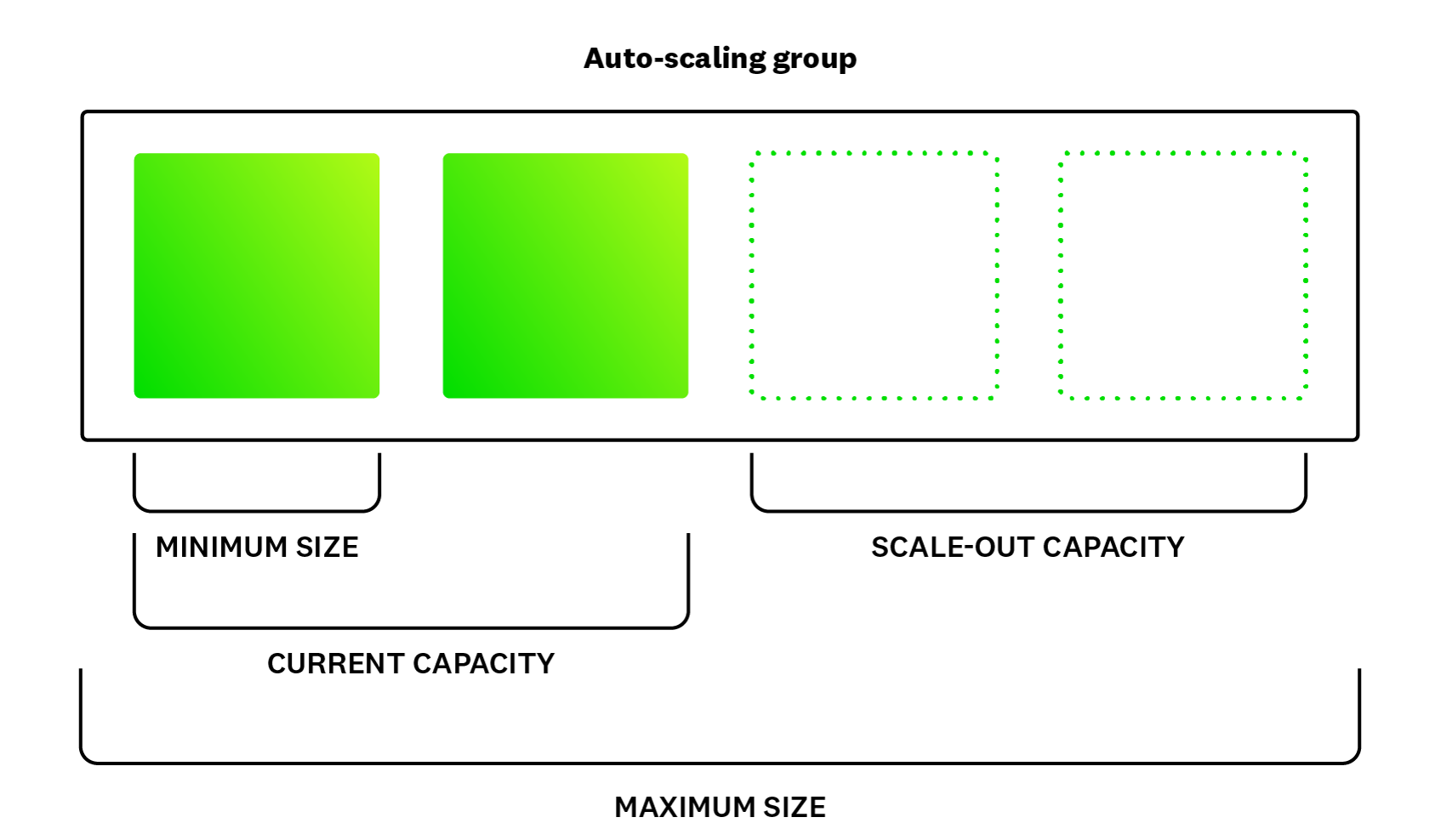
Besides relying on triggering events or metrics, you can also configure auto-scaling to occur according to a predetermined schedule. For companies and services that have cyclical (or otherwise predictable) load demands, this method lets you preemptively scale infrastructure in anticipation of higher demand and then scale back as needed.
Why Is Auto-scaling Important?
Auto-scaling promotes a positive customer experience by helping ensure that a service remains available and responsive, regardless of changes in demand. It also enables organizations to maintain this responsive infrastructure in a cost-efficient way.
First, auto-scaling helps ensure a good experience for customers who use the auto-scaled application. Customer experience is the most important yardstick by which organizations measure application performance, and maintaining a strong customer experience in the face of increased customer demand is a key goal of scaling. Auto-scaling helps organizations achieve this goal by allowing them to scale to changes in demand with quicker responsiveness than they can usually achieve through manual scaling.
Next, auto-scaling allows organizations to keep expenses low even if the stress on their hosted workload might skyrocket without warning. Before auto-scaling was an option, companies needed to pay for extra infrastructure (which would potentially go unused) to prepare for the possibility of a sudden, unforeseen growth in popularity. But with auto-scaling, companies only have to pay for the resources they currently use—while increasing their ability to handle a sudden increase in demand.
When Is Auto-scaling Used?
The following examples illustrate some of the most common use cases for auto-scaling:
- E-Commerce
Since the majority of online shoppers make their purchases during daytime hours, engineers can configure their frontend and ordering systems to scale out automatically during the day and back in at night. Similarly, auto-scaling helps teams prepare for holidays or other times of the year that are associated with an expected demand surge.
- Streaming
When media companies release new content, demand can sometimes exceed even optimistic expectations and go through the roof. For this type of content that “goes viral,” auto-scaling helps by providing crucial resources and bandwidth.
- Startups
For small companies aiming to attract a large number of customers, reducing costs while planning for sudden growth was traditionally a major pain point. Auto-scaling has helped solve this problem by allowing startups to keep costs low while reducing the risk that a demand spike will crash their application servers.
Which Cloud Service Models Allow Auto-scaling?
Cloud providers offer auto-scaling for workloads hosted at varying levels of abstraction. For example, auto-scaling capabilities are available for infrastructure-as-a-service (IaaS) platforms, such as EC2 in AWS, Virtual Machine Scale Sets in Azure, and managed instance groups in GCP. Configuring auto-scaling for these IaaS platforms requires some manual configuration, such as specifying the minimum and maximum capacity limits, along with a dynamic scaling policy that defines scaling triggers. Managed Kubernetes platforms (such as EKS, AKS, and GKE), which draw upon native Kubernetes features to autoscale pods or nodes, also require significant manual configuration—though less than if you build your own Kubernetes infrastructure on top of IaaS.
On the other hand, less configuration is typically required to use auto-scaling for containerized workloads hosted on serverless container-as-a-service (CaaS) platforms, such as ECS with AWS Fargate or Azure Container Apps. And, at the highest levels of abstraction, serverless function-as-a-service (FaaS) platforms such as AWS Lambda and some plans for Azure Functions provide auto-scaling in a completely transparent manner; with these services, capacity is automatically provisioned and deprovisioned in the background to match demand.
What Are Some Challenges Associated with Auto-scaling?
Despite the numerous benefits auto-scaling provides, it isn’t a magic bullet. Auto-scaling isn’t a “fire and forget” guarantee that software will remain performant under load. Engineers need to account for the potential limitations in designing their system, particularly focusing on how cloud IaaS and container workloads react to extreme demand.
Here are some of the potential challenges engineers encounter when implementing auto-scaling:
- Configuring auto-scaling is often complex in practice
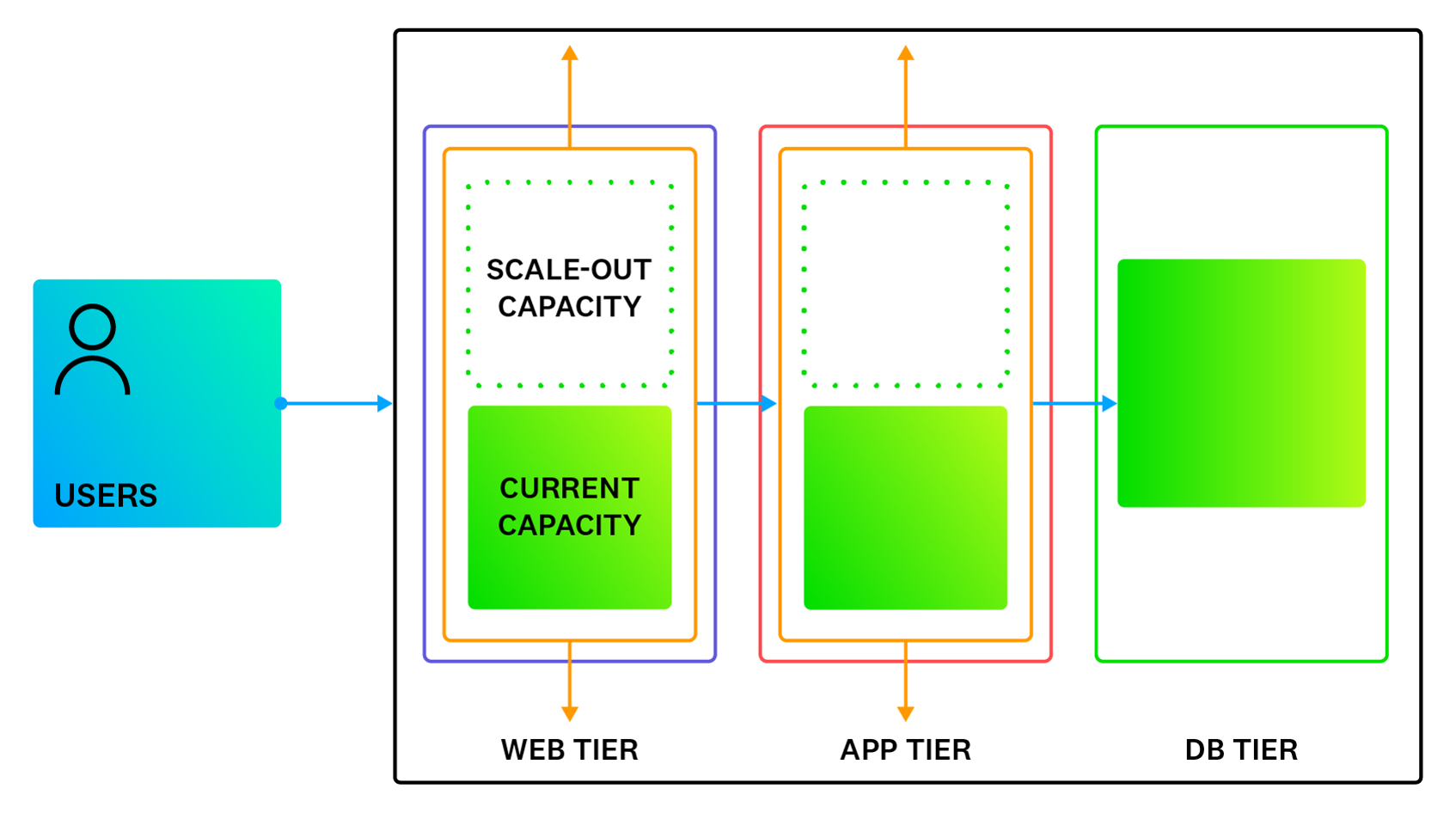
For an application to auto-scale successfully, every component in that application needs to auto-scale, including the frontend, the backend, the database layer, and infrastructure elements such as load balancers.
Similarly, autoscaling can be complex to implement within organizations, and often requires in-depth knowledge of the underlying infrastructure and tools used to manage it. As such, it can be challenging for those new to scaling to adapt such practices within their organizations.
- The underlying application has to be designed with horizontal scaling in mind
To support horizontal scaling, engineers need to develop the application as a set of microservices and not as a monolith. The application should also enforce statelessness wherever possible; in other words, a user request should not depend on a particular node “remembering” it. Additionally, NoSQL and read-only databases lend themselves much better to horizontal scaling than read/write relational databases do. (Read-only databases can be effectively scaled horizontally through replicas. However, for read/write databases, horizontal scaling requires sharding across multiple nodes, and sharding is often a challenge with relational databases.)
- Sudden demand peaks may outpace the auto-scaling response
Even in a best-case scenario, nodes may take minutes to come online while customers are already experiencing poor performance/slowness.
- Identifying and responding to the correct metrics is not an exact science
Effective auto-scaling requires engineers to identify the correct performance metrics to trigger scaling. However, identifying these metrics correctly is not a given. Engineers might auto-scale their infrastructure based on the wrong performance metrics, ultimately resulting in a poor user experience.
Which Tools Help You Build a High-Performance Auto-scaling Architecture?
Ultimately, effective autoscaling depends on a team’s ability to gain accurate knowledge about the events and threshold metric values that will best serve as trigger points. Engineering organizations that haphazardly throw additional resources at load surges tend to discover that they are just compounding existing issues and costs. Making sure engineers are using the right tools to correctly identify these events and metrics will pay dividends down the road.
To simplify and implement auto scaling across all of your cloud infrastructure, you need a tool that is able to continuously monitor resource utilization across workloads and clusters and automatically implement resource scaling, no matter the level of expertise. Datadog Kubernetes Autoscaling continuously monitors and automatically rightsizes Kubernetes resources, bringing significant cost savings to your cloud infrastructure and ensuring optimal application performance for Kubernetes workloads.
Datadog Container Monitoring also enables you not only to monitor autoscaling for these workloads, but also to trigger autoscaling with any metric from your Datadog environment. Our Infrastructure Monitoring platform offers the visualizations, metrics, and alerts you need to set thresholds properly and ensure that your autoscaled workloads are serving your customers with excellent performance.


