
マルチモデル化が加速
Datadog が収集した LLM エージェントのテレメトリデータを分析した結果、多くの組織が複数のプロバイダーを併用していることが明らかになりました。OpenAI は依然として 63% のシェアを占めていますが、この 1 年で Google Gemini と Anthropic Claude がそれぞれ 20 ポイント、23 ポイントと大きくシェアを伸ばしています。
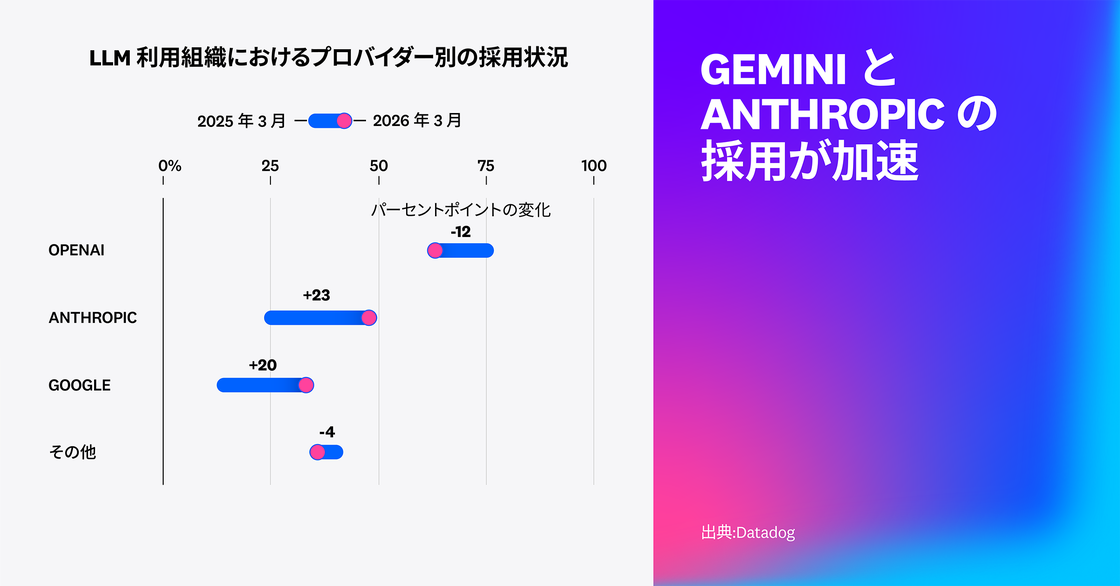
重要なのは、OpenAI のシェア低下(1 年前は75%) が利用減少を意味するわけではない点です。実際には、OpenAI を利用する Datadog 顧客数は 2 倍以上に増加しています。ただし、他のプロバイダーの成長がそれを上回っています。
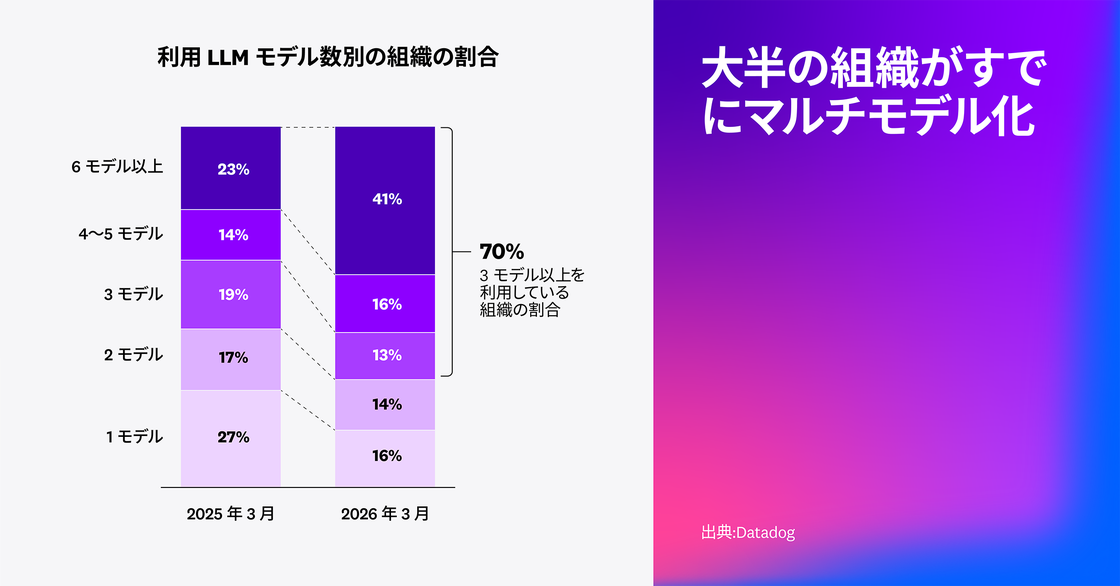
この変化は、組織内部にも表れています。現在、70% 以上の組織が 3 つ以上のモデルを利用しており、6 つ以上のモデルを併用するケースも急増しています。単一のデフォルトモデルに依存するのではなく、各ワークロードのレイテンシ、コスト、運用リスク、タスク要件に応じて最適なモデルを選び分ける。そうした「モデルポートフォリオ」の構築が標準になりつつあります。
ただし、マルチプロバイダー型のプラットフォーム構成は、プラットフォームエンジニアリング、DevX、コンプライアンスの面で新たな課題も生み出します。複数のモデルプロバイダーやサービスにまたがる API 呼び出しを個別に扱う必要があるため、迅速な改善サイクルの実現や、安全性基準とコンプライアンス基準の一貫した適用が難しくなります。また、プロバイダー側でレート制限やパフォーマンス低下が発生した場合のフェイルオーバー対応も複雑になります。そのため、各環境でモデルプロバイダーの API を直接呼び出すのではなく、LLM リクエストを一元管理するためのモジュール化されたルーティング機構 (ゲートウェイサービスや OpenRouter のようなマネージドゲートウェイ) を活用する必要性が高まっています。
先進的なチームは、推論をパイプラインとして扱っています。抽出やタグ付けには軽量モデル、統合にはフロンティアモデルといったように、各ステージに最適なモデルを継続的に評価・ベンチマークしながら切り替え、コスト低下やモデル性能の進化に合わせて最適化を進めています。モデルゲートウェイを運用し、評価フレームワークを本番運用に組み込むことで、チームは出力品質、コスト、レイテンシに基づいて、ユースケースごとに最適なモデルを選択できます。特に、オンライン評価は、本番環境におけるモデルやエージェントの出力品質、安全性、パフォーマンスを把握し、適切なモデル選定を行ううえで不可欠です
“現在、多くのチームが本番環境で複数のモデルを利用しています。約 70% が 3 つ以上のモデルを運用しており、この傾向はエージェントの普及とともにさらに加速しています。そのため、OpenRouter では、スタートアップからグローバル企業までが何百ものモデルに安全にアクセスできるよう、1 つの統合を提供しています。ユーザーが求めているのは、すばやく切り替え、自由にテストし、自分たちのワークフローに最適なモデルを見つけられることです。”
氏 OpenRouter 社 共同創業者兼 CTO
技術的負債として膨らむ LLM モデル運用
組織がマルチモデル環境へ移行するにつれて、その運用の複雑さも引き継ぐことになります。Datadog の分析によると、多くのチームは競争力維持のために新しいモデルを迅速に試す一方、本番環境で稼働している旧モデルの廃止には慎重です。その結果、多くの組織では、モデルの整理が追いつかないまま、新しいモデルが追加され続けている可能性があります。エージェントを本番運用する環境では、モデルが重複するたびに運用負荷が高まり、評価の負担も増加します。そのため、導入済みのすべてのモデルについて、パフォーマンスを継続的に検証し、リグレッションを管理する必要があります。
同じプロンプト、ツール、エージェントワークフローでも、モデルが変われば結果は変わります。つまり、モデルが 1 つ増えるたびに、品質、レイテンシ、コストの特性も増えていきます。実務上は、こうしたモデルの入れ替わりがガバナンス上の課題になります。
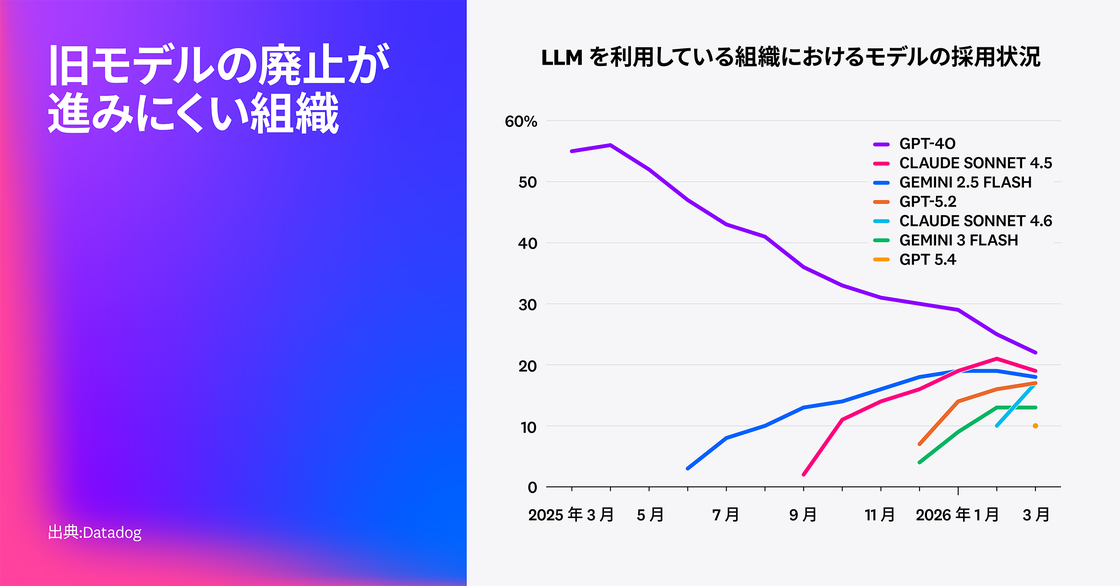
Datadog では、組織が新しいモデルリリースにどう対応しているかを把握するため、7 つの主要モデルの採用率を分析しました。その結果、チームは新しいモデルを比較的短期間で導入していることがわかりました。たとえば、Claude Sonnet 4.6 はリリース初月で採用率 17% に達しています。一方で、Sonnet 4.5 や GPT-4o などの旧モデルも、採用率は低下しているものの、2026 年 3 月時点でそれぞれ 19%、22% と一定の水準を維持しています。これは Sonnet 4.6 や GPT-5.4 と同程度です。2026 年時点では、決定的な「勝者」と言えるモデルは存在せず、多くのチームが複数モデルを並行運用し続けています。
マルチモデル環境は、継続的な評価とガバナンス、ゲートウェイによる効率的なルーティングによって適切に管理できます。ただし、プロバイダーが旧モデルの提供終了を進める中で、チームはそれらのモデルの段階的な廃止にも継続的に対応する必要があります。たとえば、Datadog が 2026 年 3 月に調査したリクエストトレースでは GPT-4o が依然として最も多く使われていましたが、OpenAI はすでに ChatGPT UI でこのモデルの提供を終了しており、API サポートの先行きには不透明さがあります。
エージェントフレームワークの普及とともに高まる、深いテレメトリの必要性
LangChain、Pydantic AI、LangGraph、Vercel AI SDK などのエージェントフレームワークは、一般的なパターンを簡単に追加できるようにし、開発を加速します。Datadog の調査では、フレームワークの採用率は 2026 年に前年比でほぼ倍増し、2025 年初頭の 9% 超から、2026 年初頭には 18% 近くまで増加しました。同じ期間に、エージェント型フレームワークを利用するサービス数も 2 倍以上に増加しています。フレームワークは開発を加速させる一方で、運用の複雑さやコストの増加も招きます。そのため、チームには、エージェントがどのように実行されているかを把握し、非効率なインポートロジックを特定し、必要に応じて専用ワークフローに置き換えるための包括的なエージェントテレメトリが不可欠です。
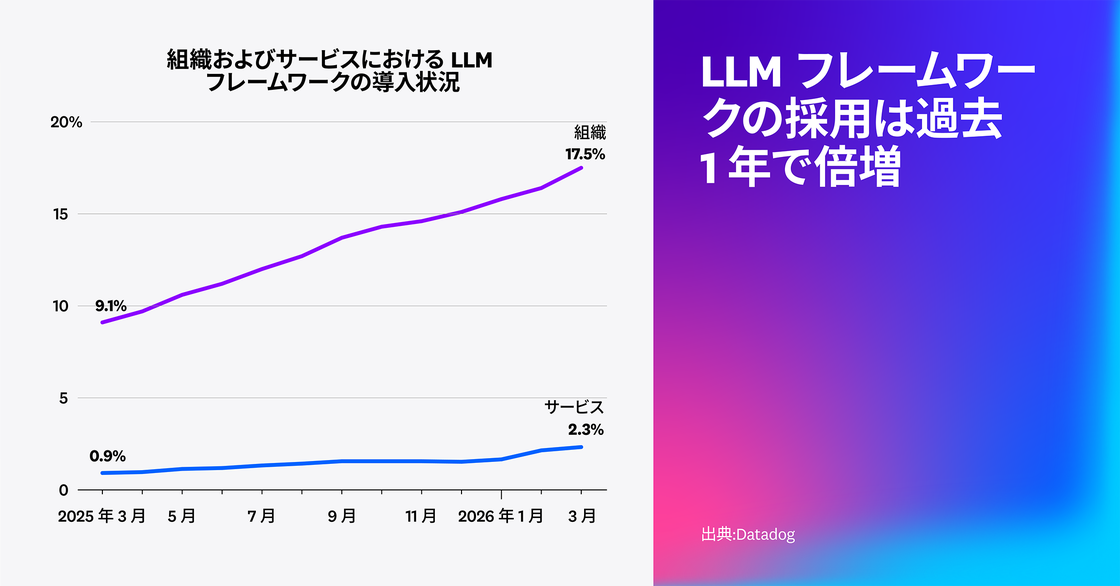
特筆すべき点として、このフレームワーク採用の拡大は、スタートアップ、中堅企業、大企業のいずれにおいても同様に見られました。
チームがフレームワークの定型コードで主要なパターンを実装すると、フレームワークが内部でステップや分岐を増やし、実行時に何が起きているのかをエンジニアが把握しづらくなります。その結果、エージェントのスプロールが起こりやすくなります。フレームワークを活用した AI アプリケーション開発では、ツールのファンアウト、リトライ、分岐を 1 回のインポートで追加できます。これにより、コストやレイテンシが徐々に増加し、障害の再現も難しくなります。そのため、エージェントの実際の実行状況を把握し、想定外の挙動を診断し、ワークフローが意図した結果からどこで逸脱しているかを特定するには、包括的なエージェントテレメトリが重要です。こうしたシグナルは、非効率なインポートロジックを専用ワークフローに置き換える判断にもつながります。
“これからのエージェントの問題は、「エージェントに何ができないか」ではありません。問われるのは、チームが何を観測できていないかです。エージェントにも、優れたソフトウェアに求められてきた本番環境でのフィードバックループが必要です。従来のソフトウェアとは異なり、エージェントは LLM 自体によって制御フローが決まります。そのため、オブザーバビリティは単に有用なものではなく、不可欠な要素になります。”
氏 Vercel 社 創業者兼 CEO
大規模なシステムプロンプトを持つエージェント設計が進む一方で、プロンプトキャッシュは十分に活用されていない
Datadog の調査では、顧客トレースにおける入力トークンの 69% がシステムプロンプトに費やされていました。これには、最初のユーザークエリから連鎖的に実行される内部指示、ポリシー定義、ツールガイダンスなどが含まれます。これは、Datadog 顧客のコンテキストエンジニアリングにおけるコストの多くが、複雑に構成されたエージェントシステムで繰り返し使用されるシステムプロンプトの最適化に向けられていることを示しています。トークン使用量を削減するには、可能な限りシステムプロンプトを短縮し、再利用可能な要素をモジュール化してキャッシュできるようにすることが重要です。
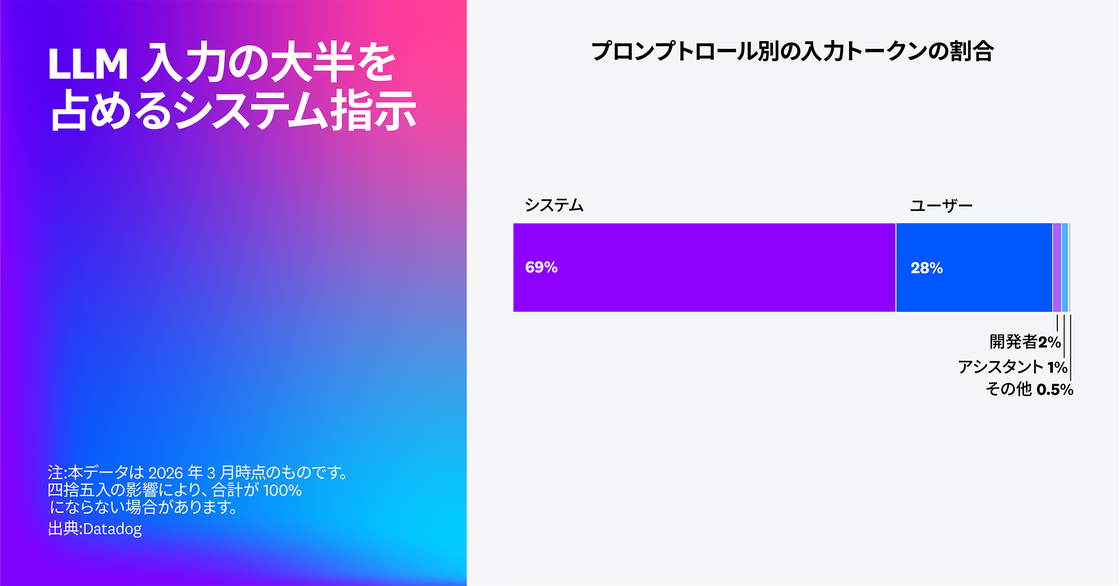
構成があらかじめ組み込まれたシステムでは、ツールの利用が増え、ポリシーや安全性ガードレールによる制約も多くなります。ガードレールやツールガイダンスが呼び出しごとにそのまま繰り返されると、コストとレイテンシの大きなボトルネックになります。
プロンプトキャッシュは、モデルの挙動を変えずにコスト削減と高速化を実現する有効な手段です。特に、システム指示、ポリシー、ツールスキーマといった安定した構成要素を呼び出し間で再利用できる場合に効果を発揮します。しかし、プロンプトキャッシュに対応しているモデルであっても、キャッシュ読み取り入力トークンが確認できた LLM 呼び出しスパンは全体の 28% にとどまりました。つまり、多くの LLM 呼び出しで、依然としてプロンプト全体が毎回処理されているのです。
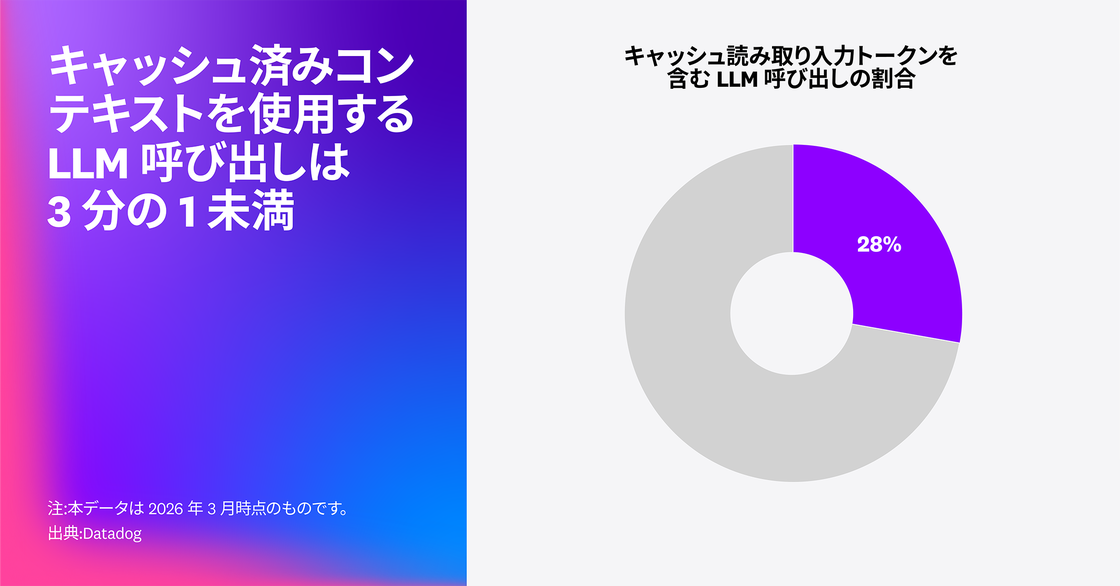
アプリケーションのキャッシュヒット率やキャッシュ済みトークンの割合が低い場合、その主な原因はプロンプトレイアウトにあることが少なくありません。プロンプト構成が非効率だと、動的コンテンツが過度に前方へ挿入されたり、本来は安定しているべき状態ブロックがリクエスト間で並べ替えられたり書き換えられたりします。その結果、キャッシュを成立させるプレフィックスの再利用が妨げられます。
コンテキストウィンドウの拡大により高まる、コンテキストエンジニアリングの可能性
エージェント型 AI が業界標準となりつつある中で、モデルの性能は向上し、大規模なリクエストのコストも低下しています。主要モデルのコンテキストウィンドウは、この 2 年間で桁違いに拡大しました。128,000 トークンから、一部の価格帯では最大 200 万トークンに達しています。これは、コンテキストウィンドウがもはや大多数のユーザーにとってボトルネックではなくなりつつあることを示しています。その結果、チームは会話履歴、取得したドキュメント、ツール出力、ポリシーガードレールなど、より多くの状態情報をプロンプトに組み込むようになっています。こうしたコンテキストは、エージェントの信頼性を高め、複雑なユースケースにより適合させるうえで不可欠です。
Datadog の調査では、顧客の LLM 呼び出しにおけるトレーススパンを分析しました。その結果、リクエストで使用される平均トークン数は、中央値の顧客で前年比 2 倍以上、上位 10% のパワーユーザーでは 4 倍に増加していることがわかりました。
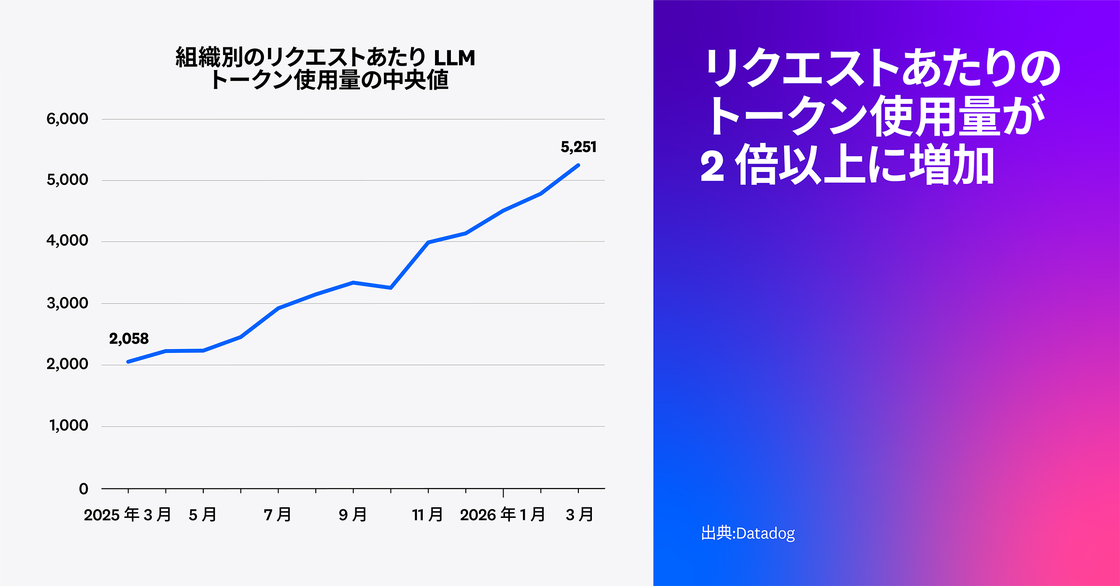
プロンプトが大規模化し、チームがエージェントパイプラインにコンテキストを収集、生成、注入する新たな方法を取り入れるにつれて、レイテンシとコストの課題は自然に生じます。さらに、プロンプトに会話履歴、取得ドキュメント、ツール出力、ガードレールが増えるほど、ノイズや冗長性が重要なシグナルをかき消す可能性があります。特に、重要な詳細が長大な入力の奥に埋もれる場合は注意が必要です。
LLM エージェントにおける新たな制約要因は、コンテキストの量ではなく質です。多くのチームは、モデルが提供するコンテキストサイズを十分に使い切っていません。これにより、中心的な課題はトークン量の管理から、どの情報が実際にモデルの判断に影響を与えるのかを理解することへと移行しています。検索品質、要約、重複排除、明確な情報階層といったコンテキストエンジニアリングに投資する組織は、長大なコンテキストを扱えるモデルの能力と、本番環境のエージェントが安定して扱える範囲とのギャップを埋めることができます。そのためには、モデルが情報を最大限に活用できるよう、意思決定に最も関連する情報を確実に選択、圧縮、構造化する仕組みを整備する必要があります。
エージェントの信頼性が直面するキャパシティの上限: LLM 呼び出しで最も多い失敗要因はレート制限エラー
当社は、Datadog Agent Observability の顧客トレースデータをもとに、LLM 呼び出しの失敗を分析しました。2026 年 2 月の分析では、すべての LLM 呼び出しスパンのうち 5% がエラーを報告しており、そのうち 60% がレート制限の超過によるものでした。さらに 2026 年 3 月には、全体の 2% の LLM スパンがエラーを返し、その約 3 分の 1 がレート制限エラーで、合計で約 840 万件に達しています。こうした結果は、モデル提供側のキャパシティ上限が、エージェントの信頼性に影響を及ぼしていることを示唆しています。レート制限が実質的なキャパシティ上限となる動的な環境において信頼性を確保するためには、予算管理やバックプレッシャー制御といった運用面の工夫に加え、プロンプトの最適化も不可欠となります。
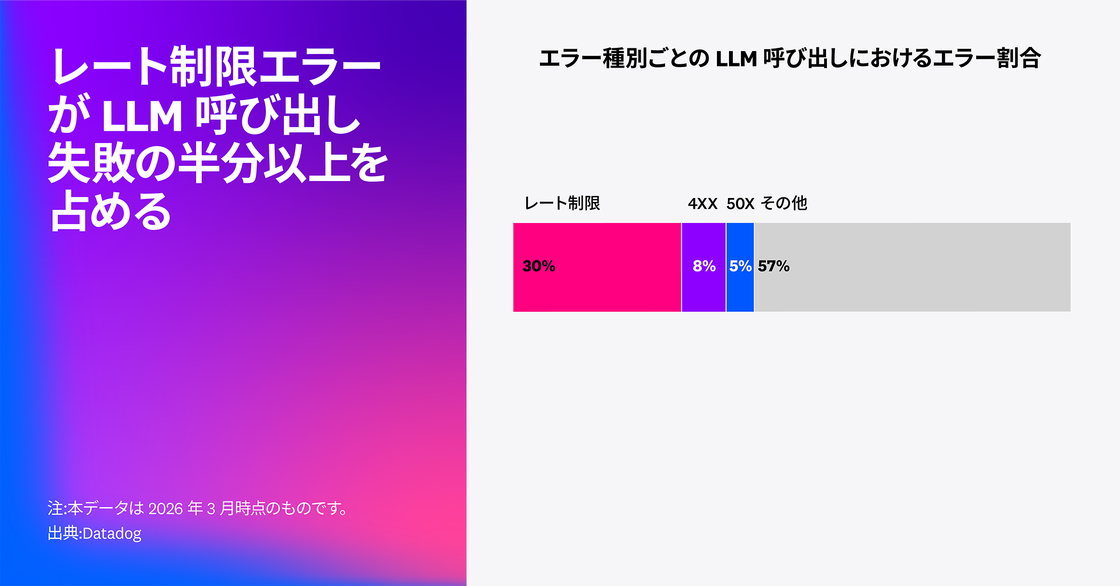
LLM アプリケーションにおける本番環境での主要な失敗要因がキャパシティである場合、チームはキャパシティエンジニアリングへの取り組みを一層強化する必要があります。特に、組織全体で共有されるキャパシティクォータや、同時実行数およびリトライのスパイクが重なると、周期的なリクエスト量の急増によって、割り当てられたキャパシティが予測不能な形で枯渇することがあります。これは、たとえば ReAct 手法を用いた可変ループを実行するシステムや、複数のエージェントが連携する構成で特に顕著です。問題は、長時間稼働するエージェントループがプロバイダーのレート制限や組織固有の同時実行上限に達したときにさらに深刻化します。リトライが連鎖的に発生し、負荷が増え、持続的なシステム障害へと発展する可能性があります。
プロンプトおよびアプリケーションロジックは、ループ長やツールファンアウトのスパイクを避けるよう設計する必要があります。同時に、プラットフォームチームは、キューシステム、バックオフ対策、フォールバックキャパシティを LLM アプリケーションのコアランタイムに組み込む必要があります。さらに、呼び出し回数やトークン使用量が上限に達した時点でエージェントループを終了させる予算を実装することで、暴走ループを防ぎ、キャパシティ枯渇が下流サービスへ波及するリスクを抑制できます。
エージェントは依然としてモノリシックが主流
Datadog の調査では、エージェント型アプリケーションのリクエストのうち 59% が単一のサービス呼び出しのみで構成されており、エンドツーエンドで 3 回以上のサービス呼び出しを伴うものは 18% にとどまりました。これは、多くのエージェントが依然としてモノリシックな構成にとどまっていることを示しています。一方で、マルチエージェントアーキテクチャを検証したり、既存環境とマイクロサービス形式で連携できるようにエージェントを専用サービス上にデプロイしたりする組織もあります。
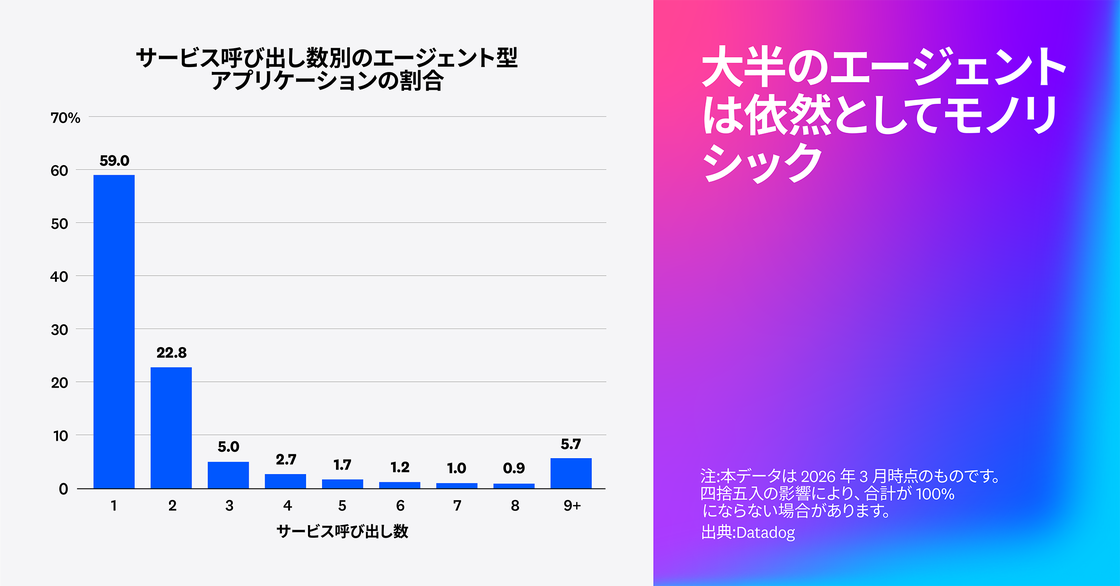
多くのチームは、モノリスがスケールしにくいことを理解し、変化を模索しています。それでも、本番環境のエージェントは依然としてモノリシックな構成が中心です。専用エージェントサービスやマルチエージェントアーキテクチャへの移行は、組織のプラットフォームに新たな要件をもたらします。これらのアプリケーションをデバッグおよびテストするには、サービス境界をまたいでコンテキストやトレースを伝播させる必要があります。さらに、このような分散型プラットフォームを管理するには、ツールも含めたサービスマップが必要です。
今後の展望
今日の AI テクノロジー組織は、マルチモデル化、スキャフォールド化、コンテキストの高度化、そして分散化が進むシステムへと移行しています。その中で成功を左右するのは、エージェントの挙動、性能、コストを継続的に評価する力です。AI エージェントのアーキテクチャは、ますます複雑化しています。コンテキストウィンドウは拡大し、プロンプトは増加し、目に見えないドリフトの影響範囲も広がり続けています。
こうした変化に対応するには、チームに新たなスキルが求められます。信頼性の高い評価ループを運用する力、コンテキストを意図的に設計する力、シグナルの高い入力を構造化する力、そしてモデルやコンテキストのスプロールが技術的負債へと膨らむ前に統制する力です。その中でも、運用の基本が変わるわけではありません。チームには引き続き、予算とバックプレッシャーを適用し、フォールバックを組み込み、適切なタスクを適切なモデルへルーティングすることが求められます。次に優位に立つのは、エージェントを規律ある本番システムへと成熟させられる組織です。継続的に評価し、改善し、より観測可能で、統制しやすく、レジリエントで、コストを意識したシステムへと進化させることが競争力につながります。