

In part 1 of this series, we looked at common design principles and patterns for assembling microservices in serverless environments. But when it comes to building serverless applications, designing your architecture is only part of the challenge. You also have to ensure that each of your individual functions and services are secure, reliable, and highly performant—without incurring enormous costs. In this post, we’ll explore how the six pillars of AWS’s Well-Architected Framework can help you rise to this challenge by adopting best practices for:
Security
Serverless architectures can be assembled in many different ways, but they share a number of characteristics that can leave them vulnerable to attack. For instance, serverless functions can be triggered by many types of events from many different sources, which creates a large attack surface. This means that if a function is over-privileged, bad actors can use a single entry point to gain access to a large portion of your app in what is known as a privilege escalation attack. Additionally, the highly distributed nature of serverless applications puts them at risk of secret sprawl, in which sensitive authentication data like passwords, tokens, and encryption keys are insecurely stored in various locations throughout your infrastructure.
You can strengthen your serverless application’s security posture by following the best practices we discuss below.
Limit Lambda privileges
You can minimize the risk of over-privileged Lambda functions by sticking to the principle of least privilege (POLP), in which a function is given an IAM role that only grants access to the services and resources necessary to execute its task. For example, you may have a function that needs full CRUD permissions for one Amazon DynamoDB table and read-only permission for another. In that case, you can attach policies to that function’s IAM role that scope its permissions to those actions. Assigning separate IAM roles that have their own unique set of permissions to each Lambda function gives you granular control over what a function can access so you can better secure your applications.
Limit access to your application with Virtual Private Clouds
Amazon Virtual Private Clouds (VPCs) enable you to launch AWS resources within a configurable virtual network, and they include a variety of features that can make your serverless applications more secure. For instance, you can configure virtual firewalls with security groups, which control traffic to and from your relational database and EC2 instances, and network access control lists (ACLs), which control access to your subnets. These VPC security features allow you to reduce the number of exploitable entry points to your application and strengthen its overall security posture.
Implement effective policies for managing secrets and credentials
It’s important to ensure that you have not embedded any long-term credentials in your Lambda functions’ code, as doing so puts your authentication data at risk of exposure. Hard-coding credentials also makes it difficult to maintain separate permissions for different regions or environments, which means that a breach in one environment can easily spread to others.
Instead, you should consider using a secret management service such as the AWS Secrets Manager. This approach not only ensures that your sensitive data is centralized and secure, but also enables you to encrypt, rotate, and manage your secrets so you can protect your data while meeting security and compliance requirements.
Reliability
Serverless architectures consist of separate microservices that are managed independently of one another, which can make it difficult to predict how often a particular service will interact with other services within an application. Your service could, for instance, receive more requests than you’ve anticipated in your processing logic, leading to degraded application performance and downtime. The following best practices will help you minimize service interruptions and recover quickly when outages occur.
Ensure high availability
High availability, which refers to an application’s ability to continue running in the event of localized failures, is a hallmark trait of reliable serverless applications. Traditional Lambda functions run in several Availability Zones (AZs) to achieve high availability by default, but if Lambda functions are deployed on your own VPC, you will need to manually configure that VPC to ensure high availability. This can be done by including VPC subnets in multiple AZs to avoid having a single point of failure. If there’s an unforeseen outage in one AZ, subnets still have the resources they need to support Lambda function invocations.
Manage failures
While you should strive for high availability, you still need a contingency plan in case your functions fail to execute. To this end, it’s important to be aware of your functions’ retry behavior, which determines how often functions will be re-invoked if an error occurs. If a function is invoked synchronously, you need to manually build retry logic into the service that invoked it. Additionally, standard Lambda errors don’t automatically map to HTTP status codes. This means functions that are invoked synchronously by API Gateway should have logic in place within their runtime code to return appropriate error messages (e.g., a 4xx status code for client side errors and 5xx errors for server side errors). Otherwise, Lambda errors are returned as 200 OK responses by default, which can prevent users from understanding the issue.
When functions are invoked asynchronously, AWS will trigger retries automatically in the event of an error. This approach to error handling is quick and efficient, but it may have unintended consequences. For example, retrying a Lambda function that handles checkout logic at an e-commerce site could result in multiple charges for the same item. You can prevent this behavior by making your functions idempotent, which will ensure that retries do not trigger repeated tasks.
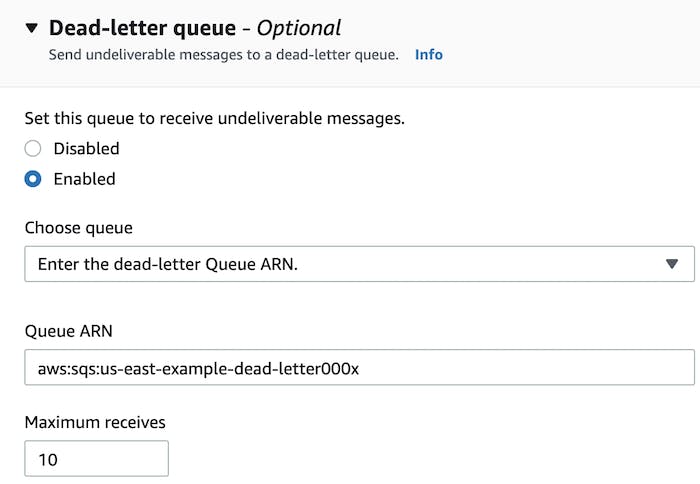
A dead-letter queue is another recovery option for Lambda functions that have been invoked asynchronously. If an event fails to invoke a function after three attempts, a message detailing the issue will be delivered to the queue. You can also implement processes that will parse dead-letter queues after the issue has been resolved and execute any pending tasks.
Performance
The complexity of serverless applications makes it difficult to determine which parts of your application will benefit most from fine-tuning. For instance, you may be unsure whether refactoring your code or allocating more memory to your functions will have a larger impact on overall performance. There are also trade offs to keep in mind. For example, caching can reduce latency, but it may also introduce eventual consistency, which means that cached data may be out of sync with the latest updates.
The following best practices will help you make performance optimization decisions that best suit your needs.
Reduce cold starts
Lambda functions take longer to initiate after periods of inactivity because the execution environment must be re-initialized. This phenomenon, which is called a cold start, leads to elevated latency and a diminished end-user experience, so it’s important to implement a strategy to minimize its occurrence. For example, Lambda distributes CPU in proportion to memory, which means that allocating more memory to Lambda functions can lower their initiation and execution times. You should also consider scheduling jobs to regularly ping your Lambda functions to keep them “warm”. If you elect to take this approach, you can write handler logic yourself or choose between modules and plugins such as the Lambda Warmer for Node.js. Additionally, you can mitigate cold starts by enabling Provisioned Concurrency, an AWS feature that keeps Lambda functions initiated and ready to be invoked.
Implement caching
If your application regularly responds to similar requests—and as a result repeatedly fetches the same data—you can speed up response times by implementing caching throughout your serverless infrastructure. Caches store frequently requested data in-memory so it does not have to be retrieved directly from backend storage. If your service includes a DynamoDB backend, you can enable the cache service DynamoDB Accelerator (DAX) to further improve response times and handle read-heavy workloads. Similarly, API Gateway can be configured to cache responses to common requests, which helps reduce latency by minimizing the number of calls made directly to your endpoints.
It’s important to be aware of your caching solution’s consistency behavior. DAX, for instance, has eventual read consistency, which means the data it stores may not be up to date with the data most recently written to your DynamoDB backend. Caching is therefore best used in applications that can tolerate eventually consistent data, such as streaming services or ecommerce sites with relatively static content.
Reduce initialization times
You can also optimize your serverless functions’ code and dependencies to improve application performance. For instance, functions written in an interpreted language such as Node.js and Python have significantly faster initial invocation times than those written in a compiled language. Additionally, it’s best to keep your function code package as small as possible. Since function code package sizes are the main contributors to the duration of cold starts, limiting package size will help cut down on the time it takes to download dependencies before your function is invoked.
Cost optimization
One of the benefits of serverless architectures is that organizations only need to pay for what they use. AWS Lambda billing, for instance, is based on the number of function invocations and their execution times, but it can also be affected by resource allocation and concurrency configuration. This means that the decisions you make to optimize the performance of your application also impact your costs. For example, allocating more memory to your functions can reduce spending by accelerating execution times, but your savings may be offset by the cost of the memory itself. As you develop and configure your serverless application, the following approaches can help you strike a balance between performance and cost optimization.
Optimize function memory size
As we mentioned above, one of the essential decisions you’ll make when building your serverless application is how much memory should be allocated to your functions. Lambda functions that don’t have enough memory are likely to experience increased latency, but memory allocation has a direct effect on costs. There’s no one-size-fits-all solution when it comes to memory right-sizing, but a good rule of thumb is to only allocate the minimum amount of memory (i.e., 128 MB) for simple, straightforward tasks, such as routing events to other services. You should also monitor your memory usage to ensure you are not paying for memory that is not being used.
Don’t overspend on Provisioned Concurrency
Provisioned Concurrency minimizes cold starts by keeping Lambda functions warm, but it also incurs additional costs. It’s therefore important to ensure you’ve configured it appropriately to avoid overspending.
While doing research for our State of Serverless report, we discovered that serverless functions typically use less than 80 percent of the Provisioned Concurrency that’s available to them. We also saw that over 40 percent of functions use all of the Provisioned Concurrency allocated to them, which means they may still experience cold starts. These figures suggest that manually right-sizing Provisioned Concurrency can be a significant pain point for many teams. To avoid accruing additional costs, you should consider Application Auto Scaling, which enables you to automatically scale Provisioned Concurrency based on usage. You can also schedule jobs to keep your functions warm, which we discussed above.
Sustainability
It’s important to understand how your design decisions can impact the environment. AWS and other cloud providers are responsible for minimizing the environmental impact of their shared infrastructure, but customers can reduce their own carbon footprint by building serverless applications that are optimized for energy and resource efficiency. The Well-Architected Framework’s sustainability pillar lays out several best practices that support this goal, such as defining and enforcing sustainability SLAs, running your workloads in Availability Zones that use renewable energy, removing unused components of your application, and scheduling jobs to prevent resource contention and load spikes.
Operational excellence
The Well-Architected Framework defines operational excellence as the ability to meet business objectives while using telemetry data to optimize your application’s health and performance. But because serverless applications are often made up of countless independent services, it can be difficult to achieve operational excellence without a robust monitoring tool that centralizes and correlates data from across your serverless stack.
In this section, we’ll take a look at how you can use Datadog to gain a full, centralized view of your serverless architecture in order to maximize its performance and reliability.
Monitor key AWS Lambda metrics in context
Datadog integrates with AWS Lambda along with dozens of other AWS services. When enabled, our AWS Lambda integration will automatically collect real-time performance metrics, such as invocation counts, errors, and duration, from all of your Lambda functions. This data is visualized in the Serverless view, alongside telemetry from the other services in your serverless stack, so you can get a single, unified view of your entire serverless architecture. This enables you to quickly spot, for instance, whether an increase in latency for a particular function is the result of throttling or an error with the service that invokes it.
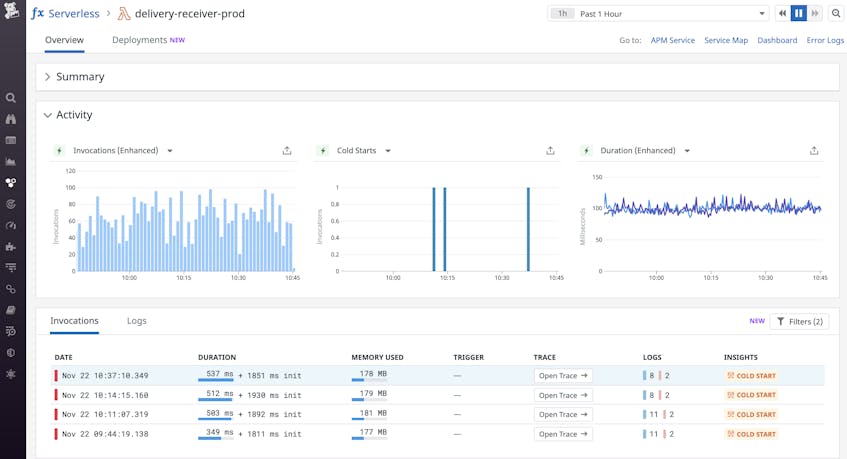
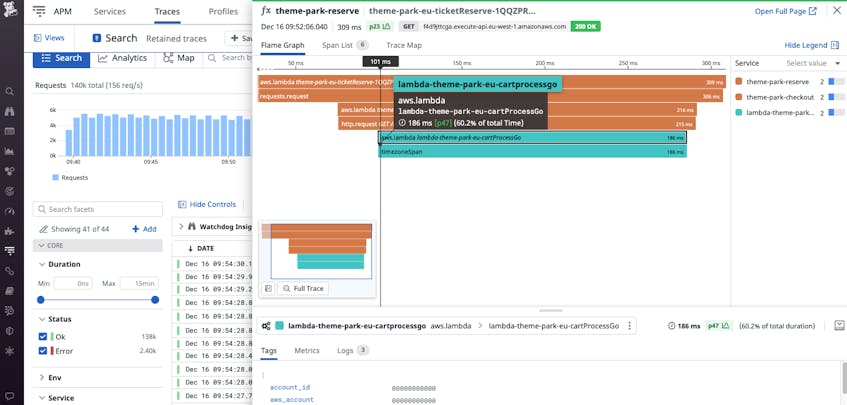
Monitor performance across your stack with Datadog distributed tracing
Datadog APM supports native AWS Lambda tracing, and all Lambda trace spans are connected to those from the other AWS-managed services in your stack. This enables you to easily see which components of your application are involved in a particular request in order to pinpoint issues and start troubleshooting quickly. Datadog also tags trace spans with data from Lambda function request and response payloads, so you can search, filter, and aggregate your function invocations even as your serverless application scales.
Standardize your serverless logs and centralize them in Datadog
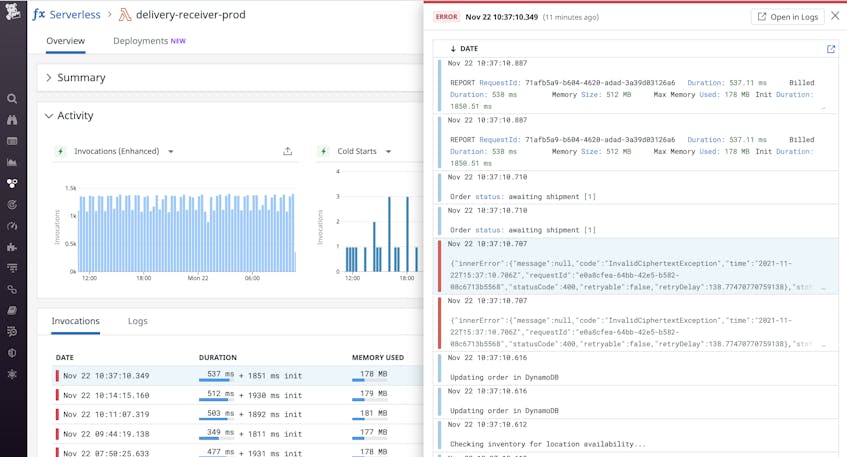
Serverless environments do not give developers access to the underlying infrastructure, which makes logs from individual AWS services crucial to achieving and maintaining operational excellence. Since serverless applications produce many types of logs, AWS recommends standardizing them in a format like JSON so that they’re easier to process. You can also centralize your serverless logs in Datadog, where you can correlate them with monitoring data from across your stack. For example, if a trace captures an AWS Lambda error, you can pivot to its corresponding logs to investigate the issue further.
Six pillars, one Datadog
In this post, we looked at how to apply best practices from AWS’s Well-Architected Framework to building serverless applications. We also discussed how a centralized monitoring platform like Datadog can provide full visibility into your serverless application to ensure it is secure, reliable, and highly performant. If you are an existing Datadog customer, you can start monitoring your serverless application today. Otherwise, sign up for a 14-day free trial.
