---
title: "Key metrics for monitoring Pivotal Platform"
description: "Keep your cluster running smoothly by tracking these key Pivotal Platform metrics."
author: "Maxim Brown"
date: 2018-10-10
tags: ["infrastructure monitoring", "pivotal", "vmware", "cloud foundry"]
blog_type_id: the-monitor
locale: ja
---
*This post is part two of a four-part series about monitoring the health and performance of Pivotal Platform (formerly known as Pivotal Cloud Foundry), focusing specifically on the Pivotal Application Service runtime. Pivotal Platform is now part of *[*VMware Tanzu*](https://cloud.vmware.com/tanzu)* following VMware's acquisition of Pivotal in late 2019.*
In the first part of this series, we outlined the [different components](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md) of a Pivotal Platform deployment and how they work together to host and run applications. In this article we will look at some of the most important metrics that Pivotal Platform operators should monitor. These metrics provide information that can help you ensure that the deployment is running smoothly, that it has [enough capacity to meet demand](https://content.pivotal.io/blog/keep-your-app-platform-in-a-happy-state-an-operators-guide-to-capacity-management-on-pivotal-cloud-foundry), and that the applications hosted on it are healthy.
Pivotal Platform operators have access to hundreds of metrics. We will break down a selection of key indicators that give you an overview of your deployment’s health and help determine if you need to scale up to accommodate users’ needs. Keeping an eye on these important metrics will help operators avoid performance issues for the developers deploying apps and the end users accessing them. They can also help identify potential scaling bottlenecks ahead of time.
Note that this post focuses specifically on deployment metrics that describe the performance, availability, and resource usage of the various components that make up a Pivotal Platform cluster. We will cover additional data types, such as logs and custom application metrics, in more detail in [part three](https://www.datadoghq.com/blog/collecting-pcf-logs.md) of this series.
## Key Pivotal Platform metrics
In this post, we will cover some of the most important metrics for monitoring several important components of Pivotal Platform using Pivotal Application Service (PAS):
- [BOSH](#bosh)
- [The User Account and Authentication (UAA) server](#the-user-account-and-authentication-server)
- [The Gorouter](#gorouter)
- [Diego](#diego)
- [Loggregator](#loggregator)
The majority of these metrics are available by default via the Loggregator Firehose. Recall that PAS's [Loggregator](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#loggregator) aggregates (“log” + “aggregator”) and streams out through the [Firehose](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#firehose) all available application logs, VM system metrics, and component metrics from a Pivotal Platform cluster. One key data source not available through Loggregator are system logs, or logs that internal system processes generate. These are available instead via syslog drains reading from rsyslog.
Pivotal also provides [Pivotal Healthwatch](http://docs.pivotal.io/pcf-healthwatch/index.html), an add-on service that reports additional metrics, many of which are derived from the metrics covered below. These metrics are only available for deployments that have Healthwatch installed and are designed to give operators a more immediately useful selection of metrics to gauge the health and utilization of their deployment (for example, by computing percentages and per-minute rates from the raw data). Healthwatch will be discussed in more detail in the [next part](https://www.datadoghq.com/blog/collecting-pcf-logs.md) of this series.
This article refers to metric terminology from our [Monitoring 101 series](https://www.datadoghq.com/blog/monitoring-101-collecting-data.md), which provides a framework for metric collection and alerting.
## BOSH
BOSH is a Cloud Foundry tool that provisions and manages the necessary resources to create your deployment’s infrastructure based on the configuration blueprints you provide. BOSH metrics provide insight into the system-level health of the various VMs running your deployment. These metrics can also be high-level indicators of resource problems depending on the job running on that VM. For example, for VMs running [Diego cells](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#diego-cells), insufficient memory or disk space can cause problems with running or starting new containers.
| Name | Description | Metric type |
| --- | --- | --- |
| system.healthy | Health check for the VM; returns 1 if VM is up and all processes are running, 0 if not | Resource: Availability |
| system.cpu.user | Percent of CPU utilization at the user level | Resource: Utilization |
| system.load.1m | Average system load over the previous minute | Resource: Utilization |
| system.mem.percent | Percent of the VM's memory used | Resource: Utilization |
| system.disk.\.percent | Percent of system, persistent, or ephemeral disk space used | Resource: Utilization |
#### Metric to alert on: system.healthy
This metric is the simplest and highest-level indicator of VM health; it tells you if the VM is up and if its processes are running properly. The failure of multiple VMs likely indicates problems with the deployment.
#### Metric to alert on: system.cpu.user
User CPU utilization can be an excellent indicator of performance issues as processes begin to throttle due to limited CPU resources. This is particularly true with VMs running the [Gorouter](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#gorouter) and the [UAA server](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#user-account-and-authentication), as reduced request throughput in those components can create a performance bottleneck for the entire deployment.
If you notice higher-than-normal CPU utilization, you can scale your available resources by increasing the capacity of the VM or by spinning up additional instances of whatever job the VM is running. Elevated CPU could also point to issues with the application or job running on that VM that warrant investigation. Pivotal recommends setting a warning threshold of 85 percent and a critical alert threshold of 95 percent CPU utilization on critical components.
#### Metric to watch: system.load.1m
This metric represents the overall system load over the previous one-minute period. As with CPU utilization, this can be a quick indicator that a VM might need to be scaled up if the overall load levels are consistently higher than expected.
#### Metric to watch: system.mem.percent
If the level of available memory on the VM is too low, process performance might suffer. Keeping an eye on this metric can help determine if a VM’s instance needs to be scaled up, or if additional instances of that VM should be created. Pivotal recommends setting a warning threshold of 80 percent and a critical alert threshold of 90 percent for memory usage.

#### Metrics to alert on: system.disk.system.percent, system.disk.ephemeral.percent, system.disk.persistent.percent
BOSH VMs can have either ephemeral storage—disk storage that is destroyed when the VM is terminated or stopped—or [persistent disk storage](https://bosh.io/docs/persistent-disks/). These metrics track the percent of disk usage for each disk type.
Keeping an eye on disk utilization will let you know if you need to add more storage or remove data before any jobs might be affected (e.g., a VM running a database server). If disks are filling up unexpectedly, you should investigate the cause to make sure that your storage resources are being used appropriately. BOSH generally shouldn’t write to system, or root, disk, so if you see high system disk usage you should check what is filling the partition. For each disk type, Pivotal recommends a warning threshold of 80 percent and a critical alert threshold of 90 percent.
## The User Account and Authentication server
The [User Account and Authentication server](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#user-account-and-authentication), or UAA, is PAS's identity management system. It stores user credentials and provides authorization tokens for applications when a user needs them. Metrics to watch for the UAA generally have to do with overall request throughput. You can also track UAA latency by using the Gorouter metric `latency.uaa`, covered [in the Gorouter section below](#gorouter).
These metrics are emitted per UAA server instance.
| Name | Description | Metric type |
| --- | --- | --- |
| requests.global.completed.count | Lifetime number of requests completed by the UAA | Work: Throughput |
| server.inflight.count | Number of requests that the UAA is currently processing | Work: Throughput |
#### Metric to watch: requests.global.completed.count
This metric is a good measure of overall UAA workload. Displaying completed requests as a per-second or per-minute rate helps identify unexpected spikes or drops. Monitoring UAA total requests completed also helps in planning deployment scaling, particularly when correlating it with UAA request latency and CPU utilization on UAA VMs.
#### Metric to watch: server.inflight.count
This metric also measures UAA server request throughput, but it measures how many requests the UAA server is handling *at that moment* rather than a lifetime total. Too many concurrent requests can affect UAA latency and throughput. Correlating this metric with UAA latency and CPU usage on UAA VMs can help determine if your UAA servers need to be scaled up.
## Gorouter
The [Gorouter](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#gorouter) is the entrypoint to your deployment, whether for operators and developers sending requests to the Cloud Controller API or for end users accessing applications. The Gorouter maintains dynamic routing tables tracking which containers on which cells are running which applications so it can send incoming HTTP requests appropriately. Router metrics will help you track the overall volume of incoming traffic and the kind of responses users are getting. These metrics also provide information on the latency of requests made by various components of your deployment.
These metrics are emitted per Gorouter instance.
| Name | Description | Metric type |
| --- | --- | --- |
| total_requests | Lifetime number of requests completed by the Gorouter | Work: Throughput |
| requests.\ | Lifetime number of requests received by the Gorouter for the specified component (e.g., the UAA server or the Cloud Controller) | Work: Throughput |
| latency | Average round-trip time (in milliseconds) for requests to go from the Gorouter to their endpoint (an application or a component API) and back again | Work: Performance |
| latency.\ | Maximum time (in milliseconds) that the specified component took to process a request from the Gorouter | Work: Performance |
| total_routes | Total number of routes currently registered with the Gorouter | Other |
| responses.5xx | Lifetime number of specified HTTP server error responses (e.g., 500, 503) received by the Gorouter from a backend application | Work: Error |
| bad_gateways | Lifetime number of 502 responses emitted by the Gorouter | Work: Error |
| responses.4xx | Lifetime number of specified HTTP client error responses (e.g., 403, 404) received by the Gorouter from a backend application | Work: Error |
| file_descriptors | Number of file descriptors the Gorouter instance is currently using | Resource: Utilization |
| backendexhaustedconns | Lifetime number of requests rejected by the Gorouter because of the maximum connections per backend limit being reached | Work: Errors |
| registry_message.route-emitter | Lifetime number of route registration messages received by the Gorouter | Other |
| mssincelastregistryupdate | Amount of time (in milliseconds) since last route register was received and emitted by the Gorouter | Other |

#### Metric to alert on: total_requests
Monitoring the total number of requests completed by Gorouter VMs can help you understand traffic flow through your deployment. Pivotal recommends scaling your Gorouters to maintain a rate of around 2,500 requests per second per Gorouter in order to keep request latency down. Correlating this metric with request latency and CPU utilization of the Gorouter VMs can provide insight into whether you need to scale your Gorouters. Significant drops in the request rate can alert you to major problems accessing the deployment.
You can also monitor the number of requests that are bound for specific components, such as the Cloud Controller, via `requests.`. This provides a more detailed view of traffic flow to particular parts of your deployment.
#### Metric to alert on: latency
Increases in the time it takes for a request to make its way from the Gorouter to the requested backend and back again can result from several different issues, including network connectivity problems, poor application health, or simply traffic congestion and an overutilized Gorouter instance. Correlating latency with CPU utilization of the Gorouter and total request throughput can help zero in on the cause of request slowdowns. Pivotal recommends starting with an alert on Gorouter latency of 100 ms and then tuning your alert thresholds to your deployment’s specific configuration.
It’s also possible to monitor a specific component’s maximum latency in handling a request from the Gorouter with `latency.` (e.g., the UAA server).
#### Metric to watch: total_routes
Diego cells send constant updates to the Gorouter to register new and changed routes to application instances. Keeping an eye on the total number of registered routes can help inform decisions about scaling your deployment to match growing usage. Alerting on significant variations in the number of registered routes can also be valuable in identifying app outages or problems with the Gorouter and overall route registration. If you notice a severe drop in this metric, it may be useful to correlate it with [`ms_since_last_registry_update`](#metric-to-alert-on-ms_since_last_registry_update) to see if there may be a problem with registering routes.
It’s also worth tracking whether the number of total registered routes is the same across all Gorouter instances. Discrepancies can be a result of problems with the route registration process or with an individual Gorouter instance.
#### Metric to alert on: responses.5xx
A spike in server-side errors can indicate a range of problems, including applications crashing or application VMs that don’t have the resources to handle the volume of incoming requests. Checking the Gorouter logs can help pinpoint the cause of the errors.
#### Metric to watch: bad_gateways
This metric tracks the number of 502 responses that the Gorouter emits. PAS emits this specific metric in addition to the number of 5xx responses because an increase in bad gateway responses can indicate that the Gorouter’s routing tables are not being updated properly, causing connections to applications to fail.
#### Metric to watch: responses.4xx
It’s worth keeping an eye out for high levels of specific client-side errors. They can alert you to incorrect URLs or possible misconfigurations that are blocking incoming traffic. Check the Gorouter logs for more details about the cause of the errors if you notice an unexpected uptick.
#### Metric to alert on: file_descriptors
In Unix-like OSes, [file descriptors](https://en.wikipedia.org/wiki/File_descriptor) are unique records for each file and network connection opened by a process. Each Gorouter instance is limited to 100,000 file descriptors. If an application exhausts the available Gorouter file descriptors, other applications will not be able to establish routes with the Gorouter and, in extreme cases, the Gorouter can lose its connection to the rest of PAS and lose its routing table.
Alerting on a Gorouter’s file descriptor count when it approaches 60,000 per Gorouter can give you time to investigate whether a specific application is causing issues or if you simply need to add more Gorouter VMs to increase the number of available file descriptors.
#### Metric to watch: backend_exhausted_conns
Setting the maximum connections per backend limits the number of connections a Gorouter can make with any one application instance. By correlating how many requests have been rejected due to hitting this limit with other throughput metrics, like the total number of requests coming through the Gorouter, you can determine if the Gorouter is experiencing consistently higher levels of usage (in which case you might scale up your deployment) or if requests are being rejected due to unresponsive or problematic applications.
#### Metric to alert on: registry_message.route-emitter
The Gorouter periodically receives route registration messages to update routing tables from the Route-Emitter sitting on each [Diego cell](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#diego-cells). By itself, this metric reports the total number of registry messages the Gorouter instance has received. Correlating it with the metric [`route_emitter.HTTPRouteNATSMessagesEmitted`](#metric-to-alert-on-httproutenatsmessagesemitted), which measures the lifetime number of route registration messages *sent* by a Route-Emitter, can reveal communication problems between Diego and the Gorouter.
Each Gorouter instance should receive identical updates from all Route-Emitters, so the number of messages received by each Gorouter instance should equal the total number of messages sent across all Route-Emitters. Pivotal recommends alerting if the average number of messages received falls below the total messages sent.
#### Metric to alert on: ms_since_last_registry_update
Routing maps on the Gorouters are set to expire after 120 seconds. By default, Diego cells send messages every 20 seconds to all Gorouters to reset the 120-second timer and maintain routing consistency. If you notice a significant delay since the last time the Gorouter received a registry update, it might indicate connectivity problems or issues with the Gorouter, NATS (internal network communication between components), or Route-Emitter VMs.
Pivotal recommends setting an alert to trigger after 30 seconds since the Gorouter last received route registration updates.
## Diego
Diego makes up the container orchestration and runtime environment components of Pivotal Platform. It runs the tasks and LRPs, or application instances, that are pushed up to the deployment. So Diego component metrics to watch primarily relate to the deployment’s ability to assign incoming requests correctly, whether the resources are available to run all required work, and whether Diego is correctly monitoring and balancing the number of instances it should be running.
The sub-components of Diego that we will cover metrics for are:
- [The Auctioneer](#auctioneer)
- [The BBS](#bbs)
- [Locket](#locket)
- [Diego cells (specifically the Rep)](#cellsrep)
- [The Route-Emitter](#route-emitter)
### Auctioneer
The [Auctioneer](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#diego-brain) receives workloads from the Cloud Controller in the form of [tasks and LRPs](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#tasks-and-lrps) and distributes them across Diego cells based on its auction algorithm. Tasks are one-off, terminating processes while LRPs, or long-running processes, are continuous and meant to always have at least one instance running. Most often, LRPs can be thought of as application instances.
Important metrics from the Auctioneer provide information on the number of auctions started and how many have failed, as well as how long it takes the Auctioneer to get the state of all Diego cells before initiating an auction.
Note that these metrics are reported per Auctioneer instance.
| Name | Description | Metric type |
| --- | --- | --- |
| AuctioneerLRPAuctionsStarted | Lifetime number of LRP instances that the Auctioneer has successfully placed on cells | Work: Success |
| AuctioneerLRPAuctionsFailed | Lifetime number of LRP instances that the Auctioneer has failed to place on cells | Work: Error |
| AuctioneerTaskAuctionsStarted | Lifetime number of tasks that the Auctioneer has successfully placed on cells | Work: Success |
| AuctioneerTaskAuctionsFailed | Lifetime number of tasks that the Auctioneer has failed to place on cells | Work: Error |
| AuctioneerFetchStatesDuration | Total amount of time (in nanoseconds) that the Auctioneer takes to fetch the state of all cells during an auction | Work: Performance |
#### Metrics to watch: AuctioneerLRPAuctionsStarted and AuctioneerTaskAuctionsStarted
Note that these metrics do not track the number of auctions that the Auctioneer has *initiated* but rather the number of LRPs or tasks the Auctioneer has placed on cells. In the case of LRP auctions, the metric is essentially a measure of how many application instances have been created.
Significant and unexpected increases in Auctioneer activity can mean that your deployment is seeing more utilization and should be scaled up, or that there might be some problem that is causing instances or tasks to fail. Because PAS will automatically attempt to restart crashed processes, high numbers of LRP auctions might indicate container churn if Diego is constantly restarting application instances.
These metrics are not emitted regularly but rather when an auction event occurs, so there will be gaps in this metric during periods when no tasks or LRPs are scheduled.
#### Metrics to alert on: AuctioneerLRPAuctionsFailed and AuctioneerTaskAuctionsFailed
Failure of the Auctioneer to place work on Diego cells is often a result of resource constraints, indicating that existing cells are already operating at their full capacity. If you notice an increase in the value of one of these metrics, dive into your [cell resource metrics](#cellsrep) to see if you need to scale them up or add additional cell VMs to the deployment.
Particularly for LRP auctions, Pivotal recommends measuring the average of this metric over a five-minute period. Using this measurement, Pivotal suggests setting a critical alert threshold of one failed LRP auction per minute on average, as any future auctions might also fail if there is a shortage of resources.
These metrics are not emitted regularly but rather when an auction event occurs, so there will be gaps in this metric during periods when no tasks or LRPs are scheduled.
#### Metric to alert on: AuctioneerFetchStatesDuration
In order to place work, the Auctioneer needs an accurate record of the current state of the Diego cells, as well as the tasks and LRPs already placed. When beginning an auction, the Auctioneer will query all Diego cells for their state. An inability to record what work the cells are doing can lead to staging tasks failing. Extended latency in the time it takes to fetch the state can indicate connectivity issues or that your Diego cells are unhealthy.
Pivotal recommends setting a warning threshold of two seconds and a critical alert threshold of five seconds when measuring how long it takes for the Auctioneer to fetch the state of Diego cells.
These metrics are not emitted regularly but rather when an auction event occurs, so there will be gaps in this metric during periods when no tasks or LRPs are scheduled.
### BBS
All work that is done by Diego comes through the BBS. The BBS receives requests from the Cloud Controller and schedules tasks and LRPs on Diego cells. It also plays an important part in synchronizing the number of application instances that *should* be running, as reported by the Cloud Controller, with how many application instances the cells are *actually* running. When a developer updates the number of instances, by scaling or pushing an application, the Cloud Controller updates the BBS's recorded `DesiredLRPs`. The BBS periodically runs convergence passes that compare the desired state of the Diego cells as forwarded by the Cloud Controller with the actual state, or `ActualLRPs`, reported by the cells.
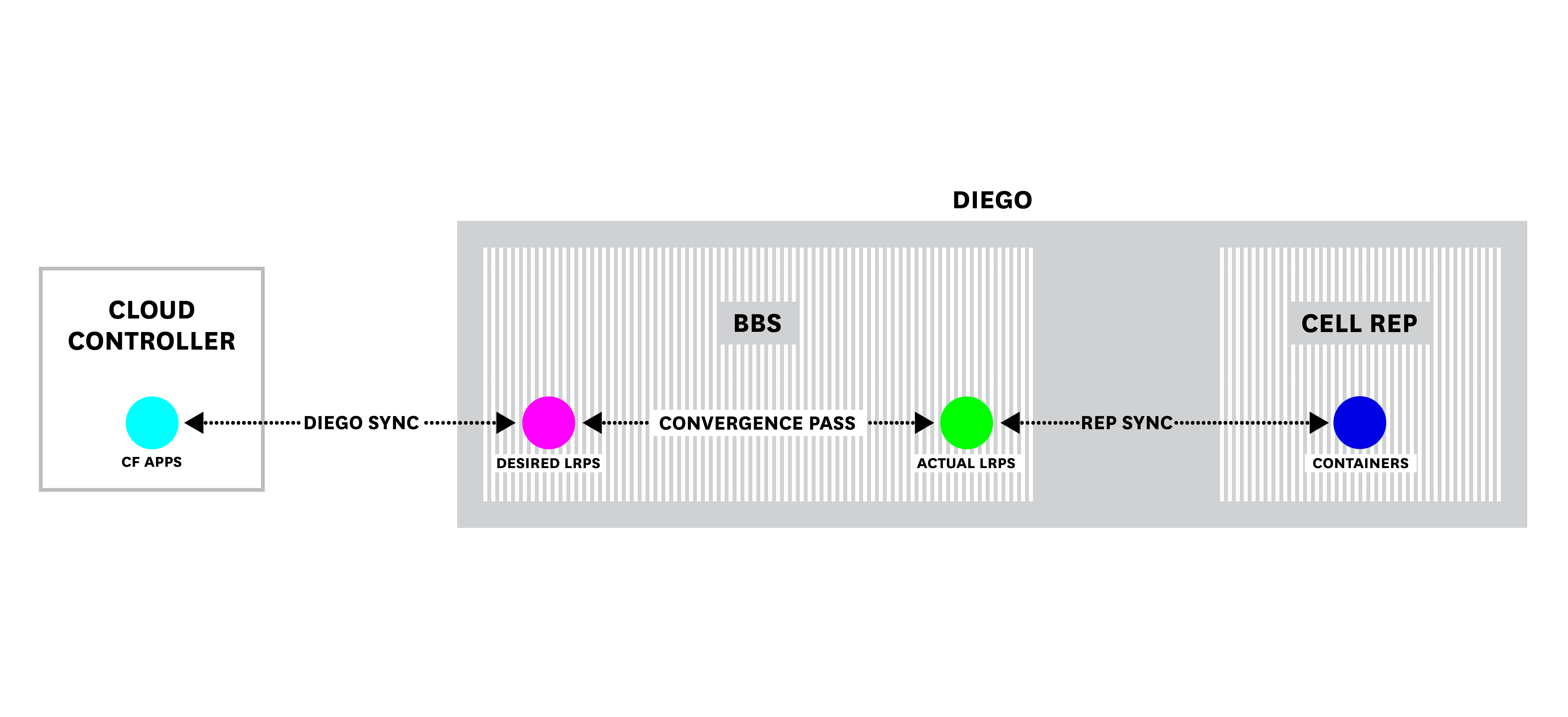
*The stages to synchronize how many LRPs should be running with how many the cells are running.*
Metrics to watch here pertain to possible differences between `DesiredLRPs` and `ActualLRPs` due to, for example, a break in communication between the Cloud Controller and Diego. Another key BBS metric to watch is how long these convergence passes are taking to complete. Finally, BBS metrics allow you to track how long the BBS takes to process new requests.
Note that each of these metrics are reported per BBS instance.
| Name | Description | Metric type |
| --- | --- | --- |
| convergenceLRPDuration | Total time (in nanoseconds) that the BBS takes to run a convergence pass | Other |
| domain.cf-apps | Indicates whether the cf-apps domain is up to date and thus apps from the CC are synchronized with DesiredLRPs in Diego; 1 if domain is up to date, no data if not | Other |
| domain.cf-tasks | Indicates whether the cf-tasks domain is up to date and thus tasks from the CC are synchronized with tasks in Diego; 1 if domain is up to date, no data if not | Other |
| LRPsRunning | Total number of LRP instances running on cells | Resource: Availability |
| LRPsExtra | Total number of LRP instances recorded by the BBS that are no longer desired | Resource: Availability |
| LRPsMissing | Total number of LRP instances that are desired but are not recorded by the BBS | Resource: Availability |
| crashedActualLRPs | Total number of LRP instances that have crashed | Resource: Error |
| RequestLatency | Maximum time (in nanoseconds) it took for the BBS to process a request | Work: Performance |
#### Metric to alert on: convergenceLRPDuration
The BBS’s convergence passes check `DesiredLRPs` as reported by the Cloud Controller against `ActualLRPs` running as stated by the Diego cells. Confirming that these numbers are the same is necessary to keep Diego’s state up to date and ensure that applications are running the way developers intend. Delays in the convergence pass might mean that instances or tasks that crash are not restarted by Diego. If this metric's value begins to climb, it could also indicate problems with the BBS communicating with other components. Pivotal recommends that a convergence pass duration of more than 10 seconds is worth alerting on, while more than 20 seconds is critical.
#### Metrics to alert on: domain.cf-apps and domain.cf-tasks
These metrics indicate whether the Cloud Controller’s record of current applications (`cf-apps`) and current tasks running for a specific application (`cf-tasks`) is synchronized with the `bbs.LRPsDesired` metric. A disparity between the Cloud Controller and Diego can affect whether requests coming in through the Cloud Controller—for example, a user trying to scale up the number of instances for an application—will be recorded and handled correctly.
#### Metric to watch: LRPsRunning
The number of running LRPs is not necessarily useful as a snapshot, but it’s worth tracking this metric’s rate of change to keep an eye on overall deployment growth and plan for scaling capacity.
#### Metrics to alert on: LRPsExtra and LRPsMissing
These metrics report differences between the record of desired LRPs and the BBS’s record of running LRPs. Pushing or deleting an application that has many instances can cause brief spikes in the number of missing or extra LRPs, respectively, but any extended high levels of either can indicate a problem with the BBS. In both cases, Pivotal suggests setting a warning threshold of around five and a critical alert threshold of around 10.
#### Metric to alert on: crashedActualLRPs
Crashing LRPs can be a result of either application or platform problems. This metric provides a high-level indication of potential issues—if you see a large number of instances beginning to crash, you will want to investigate the cause.
Alerting thresholds for this metric will vary depending on your deployment’s size and utilization. Monitoring crashed LRPs and investigating their cause (a troublesome application or a problem with the deployment itself) can help determine what levels to set for alerts.
#### Metric to alert on: RequestLatency
This metric tracks the maximum observed time the BBS took to handle a request to all its API endpoints over the previous 60 seconds. In other words, it reports the slowest measured request time. Increases in BBS request latency will manifest as slow responses to commands from the [cf CLI](https://docs.cloudfoundry.org/cf-cli/), the Cloud Foundry command line tool. Pivotal recommends a warning threshold of five seconds and a critical alert threshold of 10 seconds for this metric.
### Locket
PAS uses the Locket service to register distributed locks to ensure that the correct component processes a request and that the same work isn’t assigned to multiple cells. Particularly, the four components that use Locket are the BBS, the Auctioneer, the Route-Emitter, and the TPS Watcher, which sits on the Diego Brain and monitors for crashed LRPs. Missing locks can indicate problems with these components. Locket also records the presence of Diego cells and therefore can provide a quick overview of Diego health.
Note that these metrics are reported per Locket instance.
| Name | Description | Metric type |
| --- | --- | --- |
| ActiveLocks | Total count of system component locks | Other |
| \.LockHeld | Presence of component lock (e.g., Auctioneer or BBS); returns 1 if held, 0 if not | Other |
| ActivePresences | Total count of active cells with a registered presence | Resource: Availability |
#### Metric to alert on: ActiveLocks
When Diego is healthy, this metric should consistently report four active locks: one each for the Auctioneer, the BBS, the Route-Emitter, and the TPS Watcher. If this metric shows fewer than four active locks for several minutes, you can check the `.LockHeld` metrics. However, note that only the Auctioneer and BBS register a LockHeld.
Regardless of how many instances there are of each component that reports a lock—Auctioneer, BBS, Route-Emitter, and TPS Watcher—there will only be one lock reported for that component.
#### Metric to alert on: \.LockHeld
These metrics complement `ActiveLocks` by providing individual status reports for component locks, albeit only for the Auctioneer and the BBS. Note that a component might report a lost lock briefly if the instances perform a leader transition.
#### Metric to watch: ActivePresences
Presences are records of Diego cells, required to let the rest of PAS know that they exist and are able to be assigned work. This metric will of course vary depending on the size of the deployment, but keeping an eye on `ActivePresences` and any significant, unexpected changes can alert you to problems with Diego.
### Cells/Rep
Many of the most important metrics for monitoring your Diego cells come from the cell Rep. The Rep reports the state of the Diego cell and of Garden, which creates and manages the actual containers. The Rep's report includes statistics on available resources, so these metrics will help determine if the deployment has adequate capacity for applications or if it needs to be scaled.
Note that these metrics are reported per Diego cell.
| Name | Description | Metric type |
| --- | --- | --- |
| UnhealthyCell | Diego cell health check; returns 0 for healthy, 1 for unhealthy | Resource: Availability |
| ContainerCount | Number of containers on the cell | Resource: Utilization |
| CapacityTotalContainers | Total number of containers the cell can host | Resource: Utilization |
| CapacityRemainingContainers | Number of additional containers the cell can host | Resource: Utilization |
| CapacityTotalMemory | Total memory (MiB) available to cell for containers | Resource: Utilization |
| CapacityRemainingMemory | Remaining memory (MiB) available to cell for containers | Resource: Utilization |
| CapacityTotalDisk | Total disk space (MiB) available to cell for containers | Resource: Utilization |
| CapacityRemainingDisk | Remaining disk space (MiB) available to cell for containers | Resource: Utilization |
| RepBulkSyncDuration | Total time (in nanoseconds) the cell Rep took to synchronize ActualLRP count from the BBS with LRP reports from the Garden containers | Work: Performance |
#### Metric to alert on: UnhealthyCell
This metric indicates whether a cell has passed a Diego health check. Several cells failing within a short time period can have a negative effect on end-user experience. Triggering an alert when multiple cells fail can call your attention quickly to potential performance or availability problems.
#### Metrics to watch: ContainerCount, CapacityTotalContainers, and CapacityRemainingContainers
Use these metrics to track cell capacity and utilization in terms of the number of containers running on a given cell. By default, the maximum containers one cell may host is 250. This can be changed by modifying a [BOSH property](https://github.com/cloudfoundry/garden-runc-release/blob/v1.16.4/jobs/garden/spec#L146-L148), however Pivotal does not recommend increasing it beyond 250.
Monitoring the number of currently running containers on your cells is important for understanding overall deployment usage. Checking how many additional containers the cell can run can help indicate whether or not you need to scale out your deployment.
Note that [Pivotal Healthwatch](http://docs.pivotal.io/pcf-healthwatch/index.html) provides the additional metric `healthwatch.Diego.TotalPercentageAvailableContainerCapacity.5M`, which expresses `CapacityRemainingContainers` divided by `CapacityTotalContainers` over the previous five minutes to calculate a percentage of remaining container capacity for the cell.
#### Metrics to alert on: CapacityTotalMemory and CapacityRemainingMemory
Insufficient cell memory can make it impossible to scale existing applications or push new ones. Monitoring these metrics will help you understand if your deployment has sufficient resources. When monitoring remaining memory aggregated across all cells, Pivotal recommends setting a warning threshold of around 64 GB and a critical alert threshold of 32 GB.
One important thing to note is that when a user assigns resources to an application, Diego allocates those resources assuming the workload will require all of them at some point. In other words, the remaining memory metric will reflect what Diego has allocated as *potentially* needed, rather than the amount of memory that is actually in use at the moment the metric is reported.
Note that [Pivotal Healthwatch](http://docs.pivotal.io/pcf-healthwatch/index.html) generates two additional metrics to help monitor cell memory. By default, Healthwatch uses 4 GB as a standard “chunk” of memory for safely staging applications, though this can be changed using the [Healthwatch API](https://docs.pivotal.io/platform/healthwatch/1-8/api/free-chunks.html). The Healthwatch metric `healthwatch.Diego.AvailableFreeChunks` reports the number of available chunks of memory remaining across all cells, providing a quick understanding of remaining capacity. This metric is most useful after determining the footprint of a standard application on your deployment.
Healthwatch also reports the metric `healthwatch.Diego.TotalPercentageAvailableMemoryCapacity.5M`, which expresses `CapacityRemainingMemory` divided by `CapacityTotalMemory` over the previous five minutes to provide a percentage of remaining memory for the cell.
#### Metrics to alert on: CapacityTotalDisk and CapacityRemainingDisk
Monitoring how much disk space cells have available can provide insight into whether staging tasks are likely to start failing, as well as whether the deployment needs larger or more cells. The standard amount of disk capacity needed to ensure staging tasks do not fail is 6 GB, so Pivotal recommends setting a warning threshold of 12 GB and a critical alert threshold of 6 GB.
As with memory, Diego reports remaining disk space based on the resources that have been assigned to currently running tasks, rather than the resources that are actually in use at the moment that the metric is reported.
Note that [Pivotal Healthwatch](http://docs.pivotal.io/pcf-healthwatch/index.html) generates the additional metric `healthwatch.Diego.TotalPercentageAvailableDiskCapacity.5M`, which expresses `CapacityRemainingDisk` divided by `CapacityTotalDisk` over the previous five minutes to provide a percentage of remaining disk capacity for the cell. Pivotal recommends alerting if this metric falls below about 35 percent.
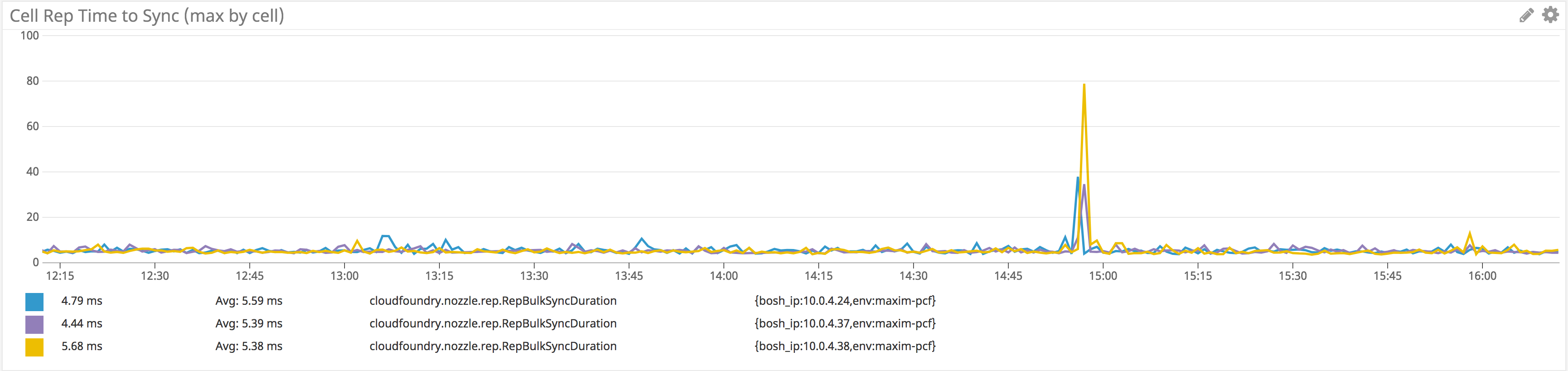
#### Metric to watch: RepBulkSyncDuration
As with other syncing processes, like the BBS’s convergence passes and the Cloud Controller’s Diego sync, the Rep performs a periodic check to sync the number of `ActualLRPs` it has on record from the BBS—LRPs that the BBS has recorded as assigned to cells—with reports directly from the containers about the work they are doing. If the Rep begins to report high sync duration times, the slowdown might point to problems with the BBS. Pivotal recommends setting a warning threshold of five seconds and a critical alert threshold of around 10 seconds for this metric.
### Route-Emitter
Correct routing tables are necessary for the Gorouter to monitor which application instances are available so it can route traffic appropriately. The Route-Emitter on each cell sends an update to the BBS whenever there are any changes in registered routes, and it also periodically sends an up-to-date image of the full routing table.
Note that these metrics are reported per Route-Emitter instance.
| Name | Description | Metric type |
| --- | --- | --- |
| RoutesTotal | Total number of routes in the routing table | Other |
| RouteEmitterSyncDuration | Average time (in nanoseconds) for the Route-Emitter to complete a synchronization pass | Work: Performance |
| HTTPRouteNATSMessagesEmitted | Lifetime number of route registration messages sent by the Route-Emitter to the Gorouter | Work: Throughput |
#### Metric to watch: RoutesTotal
Monitoring the total number of routes in the routing table can give you a sense of deployment scale and can also alert you to significant and rapid changes, such as many routes suddenly becoming unregistered. The Gorouter depends on the routing tables sent by the Route-Emitter, so discrepancies or dropped routes would leave the Gorouter unable to shuttle traffic correctly.
#### Metric to alert on: RouteEmitterSyncDuration
The time it takes for the Route-Emitter to complete its synchronization will differ depending on the deployment, so it’s important to choose an alerting threshold appropriately. As an example, Pivotal uses a threshold of 10 seconds for their Pivotal Web Services team. In any case, if the Route-Emitter seems to have difficulty syncing its routing table, it could be an indication that the BBS is failing and isn’t sending its periodic updates.
#### Metric to alert on: HTTPRouteNATSMessagesEmitted
As discussed [above](#metric-to-alert-on-registry_messageroute-emitter), when correlated with `registry_message.route-emitter`, or the number of route registration messages the Gorouters are receiving, this metric can help surface connectivity problems between Diego and the Gorouter. Pivotal recommends alerting if the average number of registration messages received by the Gorouters falls below the total number of messages sent across all Route-Emitters.
## Loggregator
[Loggregator](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#loggregator) is a system of components that aggregates and streams application logs and deployment metrics. As part of this process, Loggregator standardizes and packages these messages as [envelopes](https://github.com/cloudfoundry/loggregator-api) based on their type to make it easier for downstream components to sort and parse them.
The primary components of Loggregator to monitor are the Metron Agents, which sit on both infrastructure and host VMs and forward messages; the Doppler servers, which aggregate messages from all Metrons and store them in buffers based on envelope type; and Traffic Controllers, which consume messages from Dopplers and stream them via the Firehose.
Alternatively, operators can choose to bind a syslog drain to applications, in which case messages go from the Dopplers to a Reverse Log Proxy and then on to a Syslog Adapter. From there, the logs are streamed via rsyslog to the specified drain endpoint.
The volume of messages that the Loggregator system can process depends on how quickly each downstream component can consume the information. If consumers cannot keep up with the data being sent from sources, messages will simply be dropped to make room for the next batch. This means that each individual step in the Loggregator chain provides a possible breaking point. In particular, message loss can result if the message buffer gets backed up at the Doppler layer, as the Dopplers receive messages from multiple Metron Agents.
Individual components within Loggregator emit metrics tracking the volume of messages sent and received. For example, the Doppler metric `doppler.dropped` indicates the number of messages not delivered before being replaced by incoming messages. The following component metrics provide information about how many messages are being received or dropped by various components within the Loggregator chain:
| Component | Metric Name | Description | Metric type |
| --- | --- | --- | --- |
| Loggregator | doppler.ingress | The lifetime number of messages being ingested by the Doppler to send downstream | Work: Throughput |
| Loggregator | doppler.dropped | The lifetime number of messages dropped by the Doppler without being delivered to a downstream component | Resource: Saturation |
| CF syslog drain | adapter.ingress | The lifetime number of messages being ingested by the Syslog Adapter (only relevant for applications with a syslog drain) | Work: Throughput |
| CF syslog drain | adapter.dropped | The lifetime number of messages being dropped by the Syslog Adapter without being delivered to a downstream component (only relevant for applications with a syslog drain) | Resource: Saturation |
| CF syslog drain | scheduler.drains | The total number of syslog drain bindings | Other |
| Loggregator | rlp.ingress | The lifetime number of messages being ingested by the Reverse Log Proxy to send downstream (only relevant for applications with a syslog drain) | Work: Throughput |
| Loggregator | rlp.dropped | The lifetime number of messages dropped by the Reverse Log Proxy without being delivered to a downstream component (only relevant for applications with a syslog drain) | Resource: Saturation |
The number of messages sent through Loggregator, and even the number that are dropped without delivery, can be largely dependent on the size of the deployment. In order to get a clearer, more at-a-glance indicator of Firehose performance, it is helpful to use these metrics to calculate rates of message throughput and loss. Pivotal Healthwatch derives several metrics that give operators insight into the performance and capacity of their Loggregator system.
The following are Healthwatch metrics that use raw component metrics to derive rates of message loss across various Loggregator layers, making it easier to observe changes in Loggregator throughput and performance.
| Name | Description | Metric type |
| --- | --- | --- |
| healthwatch.Firehose.LossRate.1M | The rate of message loss from the Metron Agents to the Firehose endpoints, as a percentage over the previous minute | Work: Error |
| healthwatch.Doppler.MessagesAverage.1M | The average rate of messages processed per Doppler server instance | Work: Throughput |
| healthwatch.SyslogDrain.Adapter.BindingsAverage.5M | The average number of syslog drain bindings per Syslog Adapter | Other |
| healthwatch.SyslogDrain.Adapter.LossRate.1M | The loss rate of messages going through the Syslog Adapter on their way to a syslog drain | Work: Error |
| healthwatch.SyslogDrain.RLP.LossRate.1M | The loss rate of messages going through the Reverse Log Proxy on their way to a syslog drain | Work: Error |
#### Metric to alert on: healthwatch.Firehose.LossRate.1M
This metric reports the rate of message loss as messages pass through the Doppler servers by comparing the number of messages the Dopplers receive with the number of messages that the Dopplers drop without forwarding. (In other words, the metric is derived from `loggregator.doppler.dropped` / `loggregator.doppler.ingress`.) Pivotal suggests setting a warning threshold of 0.005, or 0.5 percent, and a critical alert threshold of 0.01, or 1 percent.
Increases in the rate of message loss can indicate that you need to scale up your Doppler or Traffic Controller instances to process the messages effectively.
#### Metric to alert on: healthwatch.Doppler.MessagesAverage.1M
This metric provides the average number of messages that each Doppler instance is processing per minute. It is derived by dividing the sum of all messages ingested by all Dopplers by the number of Doppler servers. This metric indicates whether your deployment needs more Doppler servers to handle the number of log messages being processed. Correlating this with `healthwatch.Firehose.LossRate.1M` can reveal whether your Dopplers are becoming saturated and are dropping data.
Pivotal recommends setting an alert threshold of 16,000 messages per second, or one million messages per minute. At this point, you will likely need to scale the number of Doppler instances to avoid message loss.
#### Metric to watch: healthwatch.SyslogDrain.Adapter.BindingsAverage.5M
This metric represents the number of syslog drains divided by the number of Syslog Adapters (i.e., `cf-syslog-drain.scheduler.drains` / `cf-syslog-drain.scheduler.adapters`).
Each Syslog Adapter can support around 250 drain bindings. The metric `cf-syslog-drain.scheduler.drains` provides the aggregate number of drain bindings across all Syslog Adapters. Dividing that across the number of available Syslog Adapters clearly indicates whether the deployment needs more adapters to support the number of drain bindings.
#### Metrics to alert on: healthwatch.SyslogDrain.RLP.LossRate.1M and healthwatch.SyslogDrain.Adapter.LossRate.1M
These metrics are derived by `loggregator.rlp.dropped` / `loggregator.rlp.ingress` and `cf-syslog-drain.adapter.dropped` / `cf-syslog-drain.adapter.ingress`, respectively.
This pair of metrics are applicable only to application logs generated by applications that have a syslog drain bound to them and do not reflect the status of the Firehose. These derived metrics provide insight into the percentage of message loss per minute at the Reverse Log Proxy layer and at the Syslog Adapter layer. In both cases, Pivotal suggests setting a warning threshold at a rate of 0.01, or 1 percent, and a critical alert threshold of 0.1, or 10 percent.
The Reverse Log Proxy is colocated with the Traffic Controller, so increasing levels of log loss at the RLP might point to a need to scale up Traffic Controller instances.
High rates of syslog drain log loss can indicate performance problems with your syslog server or endpoint.
### Additional Pivotal Healthwatch metrics
Aside from the metrics mentioned above, there are several additional Pivotal Healthwatch metrics that can be helpful for monitoring overall deployment health.
| Name | Description | Metric type |
| --- | --- | --- |
| healthwatch.health.check.cliCommand.\ | Status of Pivotal Cloud Foundry CLI command health tests; returns 1 for pass, 0 for fail, -1 for did not run when applicable | Resource: Availability |
| healthwatch.health.check.OpsMan.available | Status of Ops Manager availability test; returns 1 for pass, 0 for fail | Resource: Availability |
| healthwatch.health.check.CanaryApp.available | Status of Apps Manager health check; returns 1 for pass, 0 for fail | Resource: Availability |
| healthwatch.health.check.bosh.director.success | Status of BOSH Director health check; returns 1 for pass, 0 for fail | Resource: Availability |
#### Metrics to alert on: healthwatch.health.check.cliCommand.\
The most important available health checks for cf CLI commands are for `login`, `push`, `start`, `logs`, `stop`, and `delete`. These status checks perform smoke tests to confirm whether these fundamental commands are working so that developers can push and manage applications. Any failed health checks for these commands indicate that your platform is missing key functionality that is needed for normal operations.
#### Metrics to alert on: healthwatch.health.check.OpsMan.available, healthwatch.health.check.CanaryApp.available, healthwatch.health.check.bosh.director.success
These checks test the health and availability of different PAS components: the [Ops Manager](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#ops-manager), the [Apps Manager](https://docs.pivotal.io/platform/application-service/2-8/console/index.html) (or a different application if the operator has changed the default canary application setting), and the [BOSH Director](https://www.datadoghq.com/blog/pivotal-cloud-foundry-architecture.md#bosh-and-the-ops-manager).
By default, the Apps Manager acts as a canary app. That is, Healthwatch queries whether it is up and running as a test of overall application health. Its failure can be an indicator that other staged applications might be encountering performance or availability problems.
## Getting started with Pivotal Platform monitoring
Pivotal Platform is a complex, distributed system that abstracts underlying infrastructure so that developers can focus on code. It provides a scalable and highly available platform for developers to simply push an application and have it be available within minutes.
In this post, we have taken a look at several key metrics that can give Pivotal Platform operators insight into the utilization and health of their overall deployment, as well as the status of the components that make up that deployment. These metrics are invaluable for tracking not only current performance but also for determining whether it is necessary to scale your deployment to ensure sufficient resources are available for developers and end users.
In [part three](https://www.datadoghq.com/blog/collecting-pcf-logs.md) of this series, we will demonstrate several methods of collecting Pivotal Platform metrics and logs. We will cover both how to tap the Firehose stream of deployment metrics and application logs, and how to utilize a syslog drain to view component system logs.
## Acknowledgments
We wish to thank Amber Alston, Katrina Bakas, Matt Cholick, Jared Ruckle, and the rest of the Pivotal team for their technical review and feedback for this series.