
As your business evolves to serve more users, your applications and infrastructure will generate an increasing volume of logs, which may contain sensitive data such as credit card numbers, IP addresses, and tokens. When you collect sensitive data, you may be subject to laws such as GDPR—which provides heightened obligations pertaining to data protection. Solutions that allow you to redact this information from your logs in an on-prem service, or even at the edge, can be costly to implement and complex to operate.
Datadog Observability Pipelines provides an on-prem solution to automatically redact sensitive information within your infrastructure, helping to enable you to protect confidentiality and comply with applicable data protection laws. In this post, we’ll look at how Observability Pipelines enables you to efficiently detect and redact sensitive data from your logs at scale before you ship them to your preferred destinations. We’ll show you how you can use built-in scanning rules and create custom rules to help preserve confidentiality of customer data as you ship logs to destinations outside of your infrastructure.

Automatically redact sensitive log data with out-of-the-box scanning rules
Datadog Observability Pipelines’ Sensitive Data Scanner integration provides 70 out-of-the-box (OOTB) scanning rules to help you easily maintain legal compliance and customer confidentiality. Sensitive Data Scanner detects and redacts sensitive data from your logs in Datadog—and now, by combining it with Observability Pipelines, you can redact sensitive data before it even leaves your infrastructure.
Datadog provides OOTB rules that automatically recognize standard patterns, enabling you to detect and redact sensitive data such as:
- Credit card numbers
- Email addresses
- IP addresses
- API keys, SSH keys, and access tokens
When you create a pipeline, you’ll specify a log source (e.g., Splunk HEC or Sumo Logic) and one or more scanning rules. Datadog will automatically apply those rules to scan your logs in real time. By redacting sensitive data from logs in your infrastructure—before they are forwarded to your preferred destinations—Sensitive Data Scanner allows you to safely ship and store logs without risk of exposing personally identifiable information (PII) and other sensitive data.
Consider the example of a global e-commerce company that collects and stores payment information from customers all over the world. If the company were to store unredacted sensitive information—such as credit card numbers and email addresses—they could risk legal consequences if log data were exposed, possibly breaching data privacy laws. Using Observability Pipelines’ Sensitive Data Scanner integration, the company applies the out-of-the-box credit card and email address rules to the pipelines that route their Sumo Logic log data to Datadog Log Management. The Observability Pipelines Worker running within the company’s infrastructure scrubs the sensitive data as the logs are aggregated and processed, preventing card numbers and email addresses from leaving the environment or being viewed by malicious actors.
You can also specify tags that should be added to logs. If you ship your logs to Datadog, you can use these tags throughout the Datadog platform, for example, grouping similar logs for analysis or applying role-based access control (RBAC) to ensure that only authorized users have access to view the logs.
The pipeline in the screenshot below applies an OOTB rule to detect and redact GitHub access tokens from logs collected by the Datadog Agent. That rule uses a regular expression to identify strings that match the tokens’ format. It specifies Redact as its action, and it replaces the matched text with the string github_access_token_redacted, removing the risk of storing and transmitting this sensitive data.

Additional OOTB rules let you easily detect SSH keys, IP addresses, and other sensitive data.
You can configure any rule to redact all of the matched text—as shown above—or partially redact it, for example, to leave the top-level domain of an email address or the last four digits of a card number unchanged. Alternatively, you can hash the matched value to mask it with a unique identifier.
Rapidly create custom scanning rules
Observability Pipelines’ Sensitive Data Scanner integration also gives you the flexibility to automatically identify and redact sensitive data that’s not based on a widely recognizable pattern. If your data includes unique patterns not covered by any of the OOTB rules—for example, account IDs that use a format specific to your organization—you can create custom rules and apply them to your pipelines.
To create a custom rule, specify a regular expression that describes the pattern of the data you want to redact. In the screenshot below, the rule detects account UUIDs under the user attribute. If any strings under the user attribute match this pattern, they’ll be replaced with the string account_uuid_redacted.
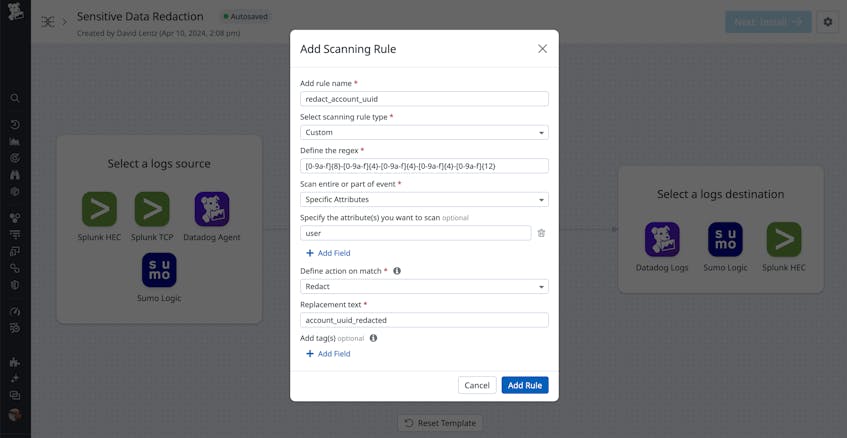
If you’re operating in a highly regulated industry, you can use custom scanning rules to ensure compliance with data privacy laws, such as the Payment Card Industry Data Security Standard (PCI DSS), HIPAA, and the California Consumer Privacy Act (CCPA). These laws may require you to redact sensitive data as you aggregate and process your logs. And if your business operates in countries where data residency requirements apply, you may need to sanitize your logs before routing them outside of your infrastructure. For example, if you’re doing business with sensitive health or financial data in the United States, you can apply custom scanning rules to redact this data in the event that you suspect that you may be transferring it and you seek added protection.
The Observability Pipelines Worker runs inside your infrastructure, sanitizing your logs in real time. This allows you to safely ship redacted logs to external destinations, avoiding substantial fines and damage to your organization’s reputation as a responsible steward of your customers’ data.
Redact sensitive data on-prem with Observability Pipelines
Observability Pipelines’ sensitive data redaction helps you efficiently navigate the complexities of data privacy laws and maintain customer trust in a global landscape. To enable automatic redaction of sensitive data, start by setting up the Observability Pipelines Worker. Then, configure your pipelines to use OOTB or custom rules to sanitize your logs before they leave your infrastructure.
To learn how you can automatically identify and redact sensitive data from your logs in Datadog, check out our blog post on Sensitive Data Scanner. See our related blog posts to learn how Observability Pipelines can help you manage your log volume, ship logs to more than one destination, and archive logs in Datadog. And if you’re new to Datadog, sign up for a free 14-day trial