

This post is part 1 of a 3-part series on monitoring the health and performance of the Windows operating system. Part 2 details how to monitor Windows Server 2012 natively with a variety of tools, and Part 3 explains how to monitor Windows with Datadog. For an in-depth webinar and Q&A session based on this series, check out this slide deck and video.
A window into Windows performance
Operating systems monitor resources continuously in order to effectively schedule processes. However, surfacing that data for your own monitoring or analytics is not always easy. Fortunately, the Windows Server family of operating systems offer a wealth of operational data that you can access through a number of channels. To help make your Windows infrastructure observable, you need to track several types of data from Windows Server 2012:
A few notes about terminology: In this series, we use the term “Windows” to reference Windows Server 2012 R2 specifically, though many of the performance counters and events discussed in this series are available in other Windows Server versions. And we’ll characterize metrics as “work” or “resource” metrics—for background on this distinction, refer to our Monitoring 101 posts on metric collection and alerting.
Performance counters/metrics
Windows exposes a huge number of metrics (more than 15,000 on a fresh install) as so-called performance counters. Key performance counters can be divided into four groups:
The lists provided below provide a good foundation to get started monitoring Windows Server, no matter if your box is a file server, DNS server, Active Directory Domain Controller, or otherwise. Though many of these metrics are not immediately actionable, taken in aggregate, they provide a clear view of the state of the system at a point in time, which is invaluable when performing root cause analysis or troubleshooting. Of course, depending on your use case, there may be additional performance counters to monitor.
CPU metrics
| WMI Class | Property name | Description | Metric Type |
|---|---|---|---|
| Win32_PerfFormattedData_PerfOS_Processor | PercentProcessorTime | Percentage of time CPU is performing work | Resource: Utilization |
| Win32_PerfFormattedData_PerfProc_Thread | ContextSwitchesPersec | Number of times the processor switched to a new thread | Other |
| Win32_PerfFormattedData_PerfOS_System | ProcessorQueueLength | Number of threads waiting on a processor | Resource: Saturation |
| Win32_PerfFormattedData_PerfOS_Processor | DPCsQueuedPersec | Number of lower-priority tasks deferred due to interrupts | Resource: Saturation |
| Win32_PerfFormattedData_PerfOS_Processor | PercentPrivilegedTime PercentDPCTime PercentInterruptTime | Percentage of time CPU spent in privileged mode/deferred procedure calls/interrupts | Resource: Utilization |
PercentProcessorTime
Prolonged periods of 100 percent CPU usage indicates a resource bottleneck. Correlating CPU usage with the length of the processor queue can help you determine if your workload is too much for the machine. High CPU usage alongside spikes in processor queue length imply a lack of adequate compute resources for the operating system to complete the work it’s tasked with.
ContextSwitchesPersec
A context switch occurs when a processor has completed the execution of a task (or is interrupted before completion) and switches to a new one. A context switch is an expensive operation that involves the following steps, as outlined in Microsoft’s reference guide:
- Save the context of the just-completed thread
- Push the completed thread down to the end of the queue associated with its priority level
- Find the highest-priority queue containing executable threads
- Pop the thread at the head of that queue, load its context, and execute it
A high rate of context switching typically indicates resource contention and points to a CPU bottleneck. Though if the context switches are occurring due to some demanding hardware device (with a corresponding increase in the rate of interrupts), the problem could lie in its driver.
Microsoft offers a few tips here on optimizing workloads to minimize context switching, among other useful tidbits.
ProcessorQueueLength
Threads in the processor queue are ready to run but can’t, due to another thread running on the processor. Queues with sustained element counts greater than 2 are indicative of a bottleneck.
Keep in mind that queues are likely to increase in size during periods of high processor activity, but queues can also develop when utilization is well below 90 percent.
DPCsQueuedPersec
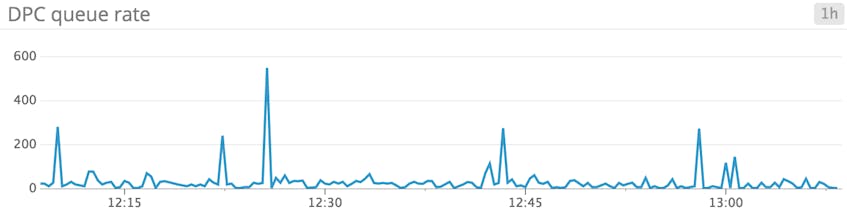
Deferred procedure calls (DPCs) provide a low-priority interrupt mechanism on Windows systems. Understanding deferred procedure calls requires a brief explanation of system interrupts in an operating system context.
Hardware requirements demand real-time, unfettered access to the CPU in order to ensure that high-priority work (like accepting keyboard input) is performed when it is needed. Interrupts provide a means by which devices can interrupt the processor and force it to perform the requested operation (triggering the processor to perform a context switch). Some work from devices may be put off until later, but still must be accomplished in a timely manner. Enter DPCs.
Through DPCs, real-time processes like device drivers can schedule lower-priority tasks to be completed after higher-priority interrupts are handled. DPCs are created by the kernel, and can only be called by kernel mode programs.
A high or near-constant number of DPCs could point to issues with low-level system software. An unused but buggy sound driver could be the culprit, for example. For more information on finding the offending service or program, check out part two of this series.
PercentPrivilegedTime, PercentDPCTime, and PercentInterruptTime
This trio of percentages offers insight into high CPU usage. PrivilegedTime is the time the CPU spends processing instructions from kernel-mode programs, DPCTime is the time the CPU spends processing deferred procedure calls, and InterruptTime is the time the CPU spends handling interrupts. It should be noted that the processor regularly issues interrupts to switch context to a new thread, so you should expect some level of background noise for this metric.
Systems that are spending 30 percent or more of their time processing privileged instructions should be inspected. First, examine DPCTime and InterruptTime; if either value exceeds 20 percent, a hardware issue is likely to be the culprit. You can use a tool like xperf (bundled with Windows) to dig deeper into the offending process.
Memory metrics
| WMI Class | Property name | Description | Metric Type |
|---|---|---|---|
| Win32_PerfFormattedData_PerfOS_Memory | AvailableMBytes | Amount of physical memory available (MB) | Resource: Utilization |
| Win32_PerfFormattedData_PerfOS_Memory | CommittedBytes | Amount of virtual memory (in bytes) committed | Resource: Utilization |
| Win32_PerfFormattedData_PerfOS_Memory | PoolNonpagedBytes | Amount of memory (in bytes) excluded from the paging pool | Resource: Utilization |
| Win32_PerfFormattedData_PerfOS_Memory | PageFaultsPersec | Page faults per second | Resource: Saturation |
| Win32_PerfFormattedData_PerfOS_Memory | PagesInputPersec | Number of pages retrieved from disk (per second) | Other |
| Win32_PerfFormattedData_PerfOS_PagingFile | PercentUsage | Percent of paging file used | Resource: Utilization |
AvailableMBytes
It is important to keep an eye on the amount of available memory, as contention for RAM will inevitably lead to paging and performance degradation. To keep your machine humming along, make sure it has an ample amount of RAM for your workloads. Consistently low memory availability can lead to segmentation faults and other serious issues. Possible remedies include increasing the amount of physical memory in the system and, if appropriate, enabling memory page combining.
CommittedBytes
CommittedBytes represents the actual demand for virtual memory. Memory that has been allocated, whether in physical RAM or the page file, counts towards the CommittedBytes total. When the number of CommittedBytes approaches or exceeds the physical memory of the system, paging to disk (and its associated performance impacts) is unavoidable.
If the value of CommittedBytes converges on the maximum memory of the system, then you are running out of available memory and must either increase the size of the page file or increase the amount of physical memory available.
In general, if this metric is trending upward increasing without leveling off, you should investigate.
PageFaultsPersec
Page faults occur when a process requests a page in memory that can’t be found. There are two types of page faults: soft and hard. A soft page fault indicates that the page was found elsewhere in memory. A hard page fault indicates that the page had to be retrieved from disk. Systems can tolerate a fairly high number of soft page faults, though hard page faults often result in delays.
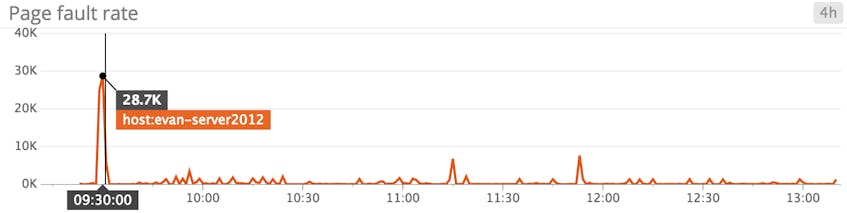
The PageFaultsPersec metric tracks the number of page faults, both soft and hard. To focus on hard page faults, look for high values of pages input per second (outlined below). If you identify a surge in hard page faults, you should either increase system memory, or else decrease the system cache size to free up memory for paging.
Monitoring the working set of process memory allows you to correlate a specific process’s memory usage with page faulting. Under heavy load, the operating system will continuously trim processes’ working memory, resulting in frequent page faults. To narrow down the offending process, you can also correlate with page fault frequency by process (check the Win32_PerfFormattedData_PerfProc_Process object).
PoolNonpagedBytes
As mentioned above, the Windows kernel and hardware devices require the ability to preempt other threads to execute their time-sensitive work. Because of these strict requirements, devices and the kernel access physical memory directly, and not through virtual memory, as do user-mode processes.
This special pool of memory is not subject to paging to disk, due to the time requirements of its users. Normally, this is not an issue. But the special treatment of this pool means that problems with the components using this memory could be fatal for the system. Memory leaks in drivers that use the non-paged pool, for instance, could lock up the system entirely, as memory for user-mode processes is dumped to disk. Keeping an eye on this metric is useful for debugging memory leaks and other showstopping issues.
Windows Event 2019 (“Nonpaged Memory Pool Empty”) will occur in the event of insufficient allocable memory. (Though the Microsoft reference page lists the cause as a TCP/IP sockets program continuously attempting to open a nonexistent socket, this event will also occur if the non-paged pool address space is exhausted.)
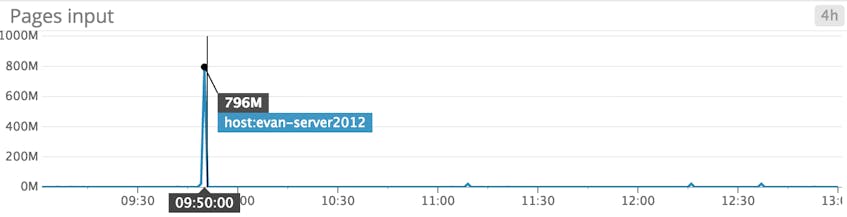
PagesInputPersec
This metric reports the number of pages read from disk (as opposed to the number of read operations) to resolve hard page faults.
Recall that there are two types of page faults, and only hard page faults require fetching the page from disk. Tracking PagesInputPersec alongside PageFaultsPersec gives a clear view into the type of fault occurring. High values of the PagesInputPersec counter indicate hard page faults.
It is worth mentioning that when a hard page fault does occur, Windows attempts to retrieve multiple, contiguous pages into memory, to maximize the work performed by each read. This, in turn, can potentially increase a page fault’s performance impact, as more disk bandwidth is consumed reading in potentially unneeded pages. All of this can potentially be avoided by putting your page file (see next section) on a separate physical (not logical) disk, or increasing the amount of RAM available to your system.
PercentUsage
The paging file is a “hidden” file in the Windows system folder, used to store infrequently accessed memory pages on disk to free up RAM for other things. If you are familiar with Linux, the page file is similar to the swap partition.
Because the paging file is located on disk, not only will reads/writes to it impact overall system performance, but it is also subject to fragmentation, which degrades system performance even further.
By default, Windows manages the page file, which means the size of the file can increase or decrease without any user input. However, some cases may warrant manual tweaking of the file size. For more information on tuning your page file size (and other potential optimizations), check out Microsoft’s documentation on page file tuning.
Disk metrics
| WMI Class | Property name | Description | Metric Type |
|---|---|---|---|
| Win32_PerfFormattedData_PerfDisk_LogicalDisk | PercentFreeSpace | Percentage of disk space remaining | Resource: Utilization |
| Win32_PerfFormattedData_PerfDisk_LogicalDisk | PercentIdleTime | Percentage of time disk was idle | Resource: Availability |
| Win32_PerfFormattedData_PerfDisk_LogicalDisk | AvgDisksecPerRead AvgDisksecPerWrite | Average time of a read/write operation (in seconds) | Work: Performance |
| Win32_PerfFormattedData_PerfDisk_LogicalDisk | AvgDiskQueueLength | Average number of read/write requests (per disk) in queue | Resource: Saturation |
| Win32_PerfFormattedData_PerfDisk_LogicalDisk | DiskTransfersPersec | Rate of read/write operations on disk | Work: Throughput |
| Win32_PerfFormattedData_PerfOS_Memory | CacheBytes | Size of file system cache in memory | Resource: Utilization |
PercentFreeSpace
Maintaining ample free disk space is a necessity for any operating system. Beyond regular processes requiring disk, core system processes store logs and other kinds of data on disk. Windows will issue a warning if your available disk space drops below 15 percent, but you should alert on this metric to catch the smoke before the fire.
PercentIdleTime
This metric reports the percentage of time the disk was idle. If you are hosting your page file on a drive separate from the OS drive, you should definitely track and potentially alert on this metric, on both your primary drive and the page file’s drive. Low values for idle time should be investigated; high I/O on the page file disk will translate to increased memory access times, which will be felt by any application whose memory is mapped to the paging file. Possible solutions include moving the paging file to an unused drive or a faster drive.
Beyond the paging file, performance of applications that make heavy use of the disk (like SQL Server, for example) will certainly suffer during prolonged periods of high I/O.
AvgDisksecPerRead and AvgDisksecPerWrite
This pair of metrics tracks the average amount of time taken for disk read/write operations. In general, values larger than about 30 milliseconds indicate relatively high latency, which can often be reduced by moving to faster disks. Depending on the role of your server, the acceptable threshold could be much lower—as low as 10 milliseconds if you are running Exchange Server or SQL Server.
AvgDiskQueueLength
The average disk queue length gives a running average of the number of read/write requests in the queue. This value is not a direct measurement of the disk queue at any given point in time; it is an estimate derived from (Disk Transfers/sec) * (Disk secs/Transfer).
Generally speaking, if the average disk queue length exceeds 2 * (number of drives) for prolonged periods, a bottleneck is forming.
DiskTransfersPersec
If your server is hosting a demanding application, like SQL Server or Exchange, you will want to monitor your disk I/O rates. The DiskTransfersPersec metric is an aggregate of read (DiskReadsPersec) and write (DiskWritesPersec) activity, tagged by disk (and a total across all disks tagged with _Total). Sustained periods of high disk activity could lead to service degradation and system instability, especially when coupled with high RAM and page file use. Possible remedies include increasing the number of disks in use (especially if you’re seeing a large number of ops in queue), using faster disks, increasing RAM reserved for file system cache (see below), and distributing the offending workload across more machines, if possible.
CacheBytes
The CacheBytes counter tracks the size, in bytes, of the portion of memory reserved as a file system cache. Whereas the paging file is used to store memory contents on disk, the file cache stores disk contents in RAM, for faster access.
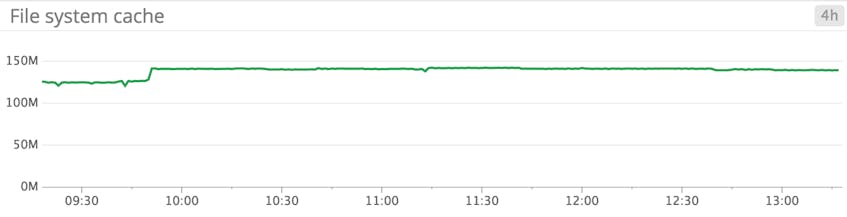
Tuning the file cache size for optimal performance is a balancing act—if the cache is too small, access to files is slower; if the cache is too large, programs may end up with their memory paged to disk, slowing them down. By default, Windows takes care of this for you, allocating free RAM to be used for the file cache. However, your requirements may require manual tweaking of the file cache, for which you can use a tool like CacheSet.
It is worth mentioning that if you are opening many “large” files (larger than about one gigabyte), your issue may be caused by an issue in the accessing process, specifically, calling CreateFile() with the FILE_FLAG_RANDOM_ACCESS flag set. Passing this flag to CreateFile causes the Cache Manager to keep previously viewed memory pages in the cache. When accessing files whose cumulative size exceeds the amount of physical memory, performance will suffer. See KB 2549369 for more information.
Network metrics
| WMI Class | Property name | Description | Metric Type |
|---|---|---|---|
| Win32_PerfFormattedData_Tcpip_NetworkInterface | BytesSentPersec BytesReceivedPersec | Network send/receive rate | Resource: Utilization |
| Win32_PerfFormattedData_Tcpip_TCPv4 | SegmentsRetransmittedPersec | IPv4 TCP retransmissions | Other |
BytesSentPersec and BytesReceivedPersec
Taken together, these two metrics measure the total network throughput of a given network interface. With most consumer hardware shipping with NICs capable of 1 gigabit per second or more, it is unlikely that the network would be a bottleneck in all but the most extreme cases. Microsoft documentation suggests that network saturation occurs when consuming more than 80 percent of the interface’s bandwidth, amounting to 100 megabytes per second for a 1-Gbps link.
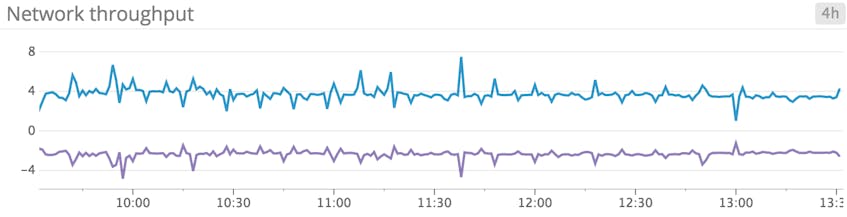
Though unlikely to be the cause of performance issues, correlating network throughput with metrics from applications running on top of Windows (like IIS) could shed light on issues arising in those applications. In the event that you are saturating your network link, you may consider using a web cache for outbound traffic; otherwise you may need to increase your bandwidth (via your provider or through hardware upgrades).
SegmentsRetransmittedPersec
TCP retransmissions occur when a transmitted segment has not been acknowledged within the TCP timeout window, so the segment is re-sent.
TCP retransmissions occur frequently and are not errors, though their presence can be a sign of issues. Retransmissions are usually the result of network congestion, and most often are correlated with high bandwidth consumption. You should monitor this metric because excessive retransmissions could cause extensive delays in your applications. If the sender of the retransmits does not receive an acknowledgment of packets sent, it holds off on sending more packets (usually for about 1 second), adding delays that can compound congestion-related slowdowns.
If not caused by network congestion, the source of retransmits could be faulty network hardware. A low number of discarded packets in conjunction with a high rate of retransmissions could point to excessive buffering as the culprit. Whatever the cause, you should track this metric to shed light on seemingly-random fluctuations in network application response times.
Events
While performance counters provide a high-level overview of resource usage and performance, troubleshooting complex issues requires additional information on the sequence of events that occurred before or during the observed issue. By correlating performance counters with events from the Windows Event Log, metrics can be put in context with events across a network of hosts.
Windows Server 2012 has many event sources and, subsequently, many different event logs. (Our test environment, a fresh Windows Server 2012 installation on Microsoft Azure, had 245 separate event logs.) You can see the full list available on your system by navigating to the %SystemRoot%\System32\Winevt\Logs directory. The event logs that are pertinent to you will depend on what you are using your server for (Active Directory Domain Controller, DNS server, etc.).
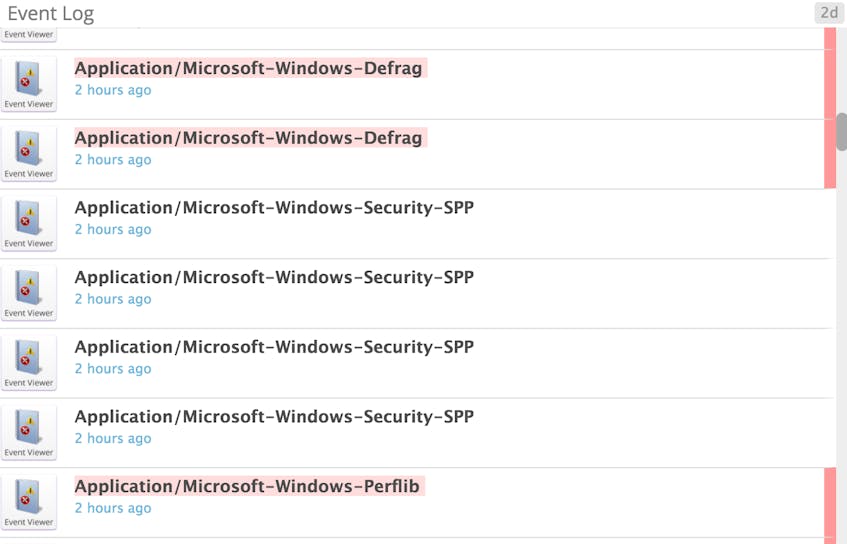
In addition to monitoring those event logs important to your use case, the Application (Application.evtx), System (System.evtx) and Security (Security.evtx) logs will provide useful information to most Windows administrators. Below we will break down several important events, categorized by event log, and classified by log level. See this reference for a list of all event properties.
System events
| Event Log | Level | ID | Event Description | Source |
|---|---|---|---|---|
| System | Critical | 41 | Unexpected reboot | Kernel-Power |
| System | Error | 1001 | Server rebooting from BugCheck | BugCheck |
System EventID: 41
This system event is logged when a system fails to cleanly shut down before rebooting. Power loss, a crash, or hung operating system are all common causes. Unless otherwise configured, Windows will reboot when it blue screens, so you probably want to alert on this event. If you see this event occur along with System event 1001 (see below), you can be sure the reboot was caused by a blue screen.
System EventID: 1001
When a system blue screens, an event is written to the System log with more information on the cause of failure (returned as a hex value), as well as the location of the memory dump generated at the time of the failure. By default, Windows will reboot when it blue screens, which means you may not notice an error occurred without peering into the event logs.
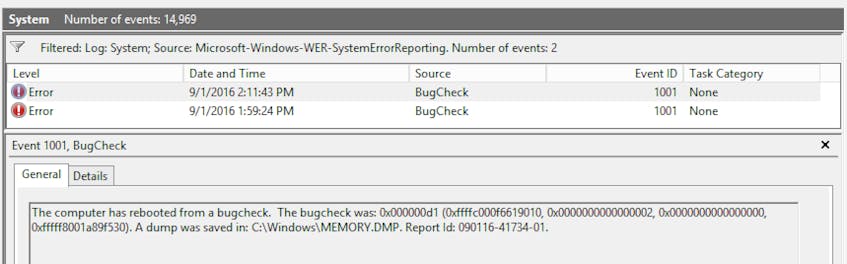
Pinpointing the root cause of blue screens is very important—once one occurs, it is generally a sign of things to come. You definitely want to be aware of these events and should set an alert on their occurrence.
Application events
Application events give additional details on application failures and started services.
| Event Log | Level | ID | Event Description | Source |
|---|---|---|---|---|
| Application | Error | 1000 | App Error | Application Error |
| Application | Error | 1002 | App Hang | Application Hang |
Application EventID: 1000
Events in the Application event log with EventID 1000 indicate that an application error has occurred, which resulted in a crash. From time to time, core Windows applications and services may encounter errors and crash. This is not usually an issue; in most cases, Windows can restart the service and resume operation.
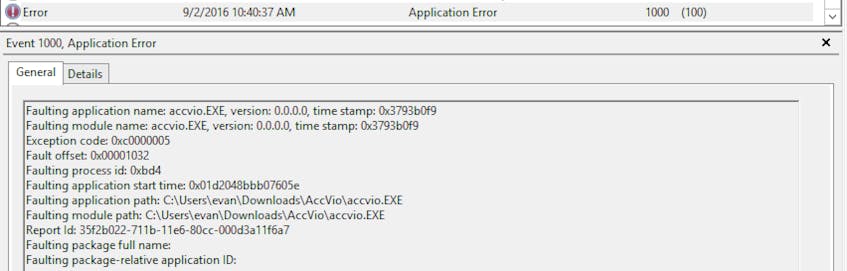
Because automatic restart is not always possible, however, you may want to alert on this event, depending on the application that crashed. If an application is continuously crashing, further investigation may be warranted.
Application EventID:1002
Hung applications occur when a user attempts to give input to a GUI, and the GUI does not update with the new input. Applications that repeatedly hang should be investigated; there could be an underlying issue causing the hang. An application suddenly and repeatedly hanging when it was previously working correctly can oftentimes be attributed to system changes, like a driver or firmware update. Correlating system changes with this event can shed light on the underlying causes of hung applications. Note that applications can only enter the hung state upon attempts at user interaction; Windows only becomes aware of a hung application when a user attempts to interact with it.
Security-related events
Important changes to users, groups, and other important features are logged to the Security Audit event log. Some of the more important events can be found below; for an exhaustive list of security audit events, see Microsoft’s documentation.
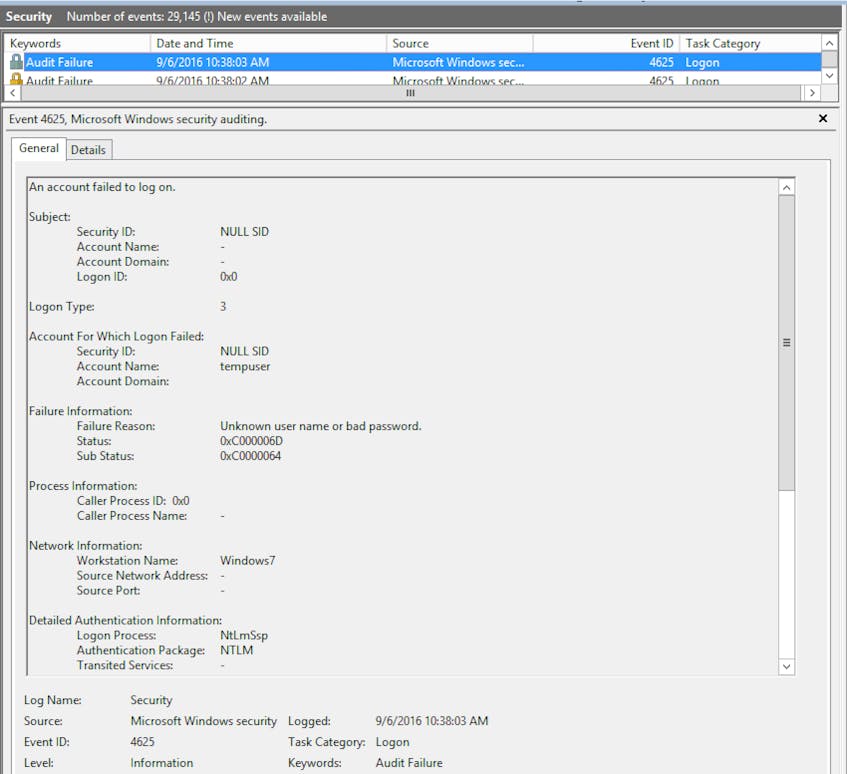
Should any of these events unexpectedly arise in the event log, swift action should be taken to verify the source of the changes and their legitimacy.
| Event Log | Level | ID | Event Description | Source |
|---|---|---|---|---|
| System | Information | 104 | Event log cleared | Microsoft-Windows-EventLog |
| Security | Information | 1102 | Audit log cleared | Microsoft-Windows-EventLog |
| System | Information | 4719 | System audit policy modified | Microsoft-Windows-EventLog |
| Security | Information | 4740 | User account locked | Microsoft-Windows-Security-Auditing |
| Security | Information | 4728, 4732, 4756 | User added to a security-enabled group | Microsoft-Windows-Security-Auditing |
| Security | Information | 4735 | Security-enabled group was modified | Microsoft-Windows-Security-Auditing |
| Security | Information | 4724 | Password reset attempt | Microsoft-Windows-Security-Auditing |
| Security | Information | 4625 | An account failed to logon | Microsoft-Windows-Security-Auditing |
| Security | Information | 4648 | A logon was attempted using explicit credentials | Microsoft-Windows-Security-Auditing |
Services
Monitoring Windows services serves two purposes: ensuring that essential services remain up, and enabling the discovery and disabling of non-essential services.
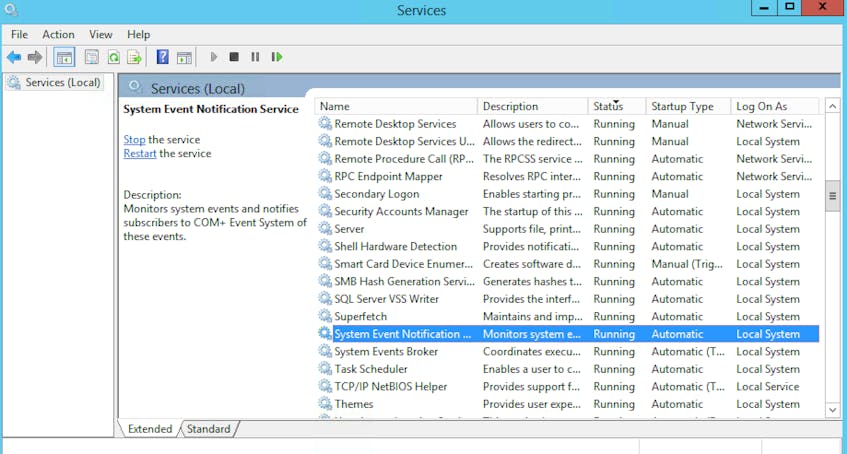
Windows services are long-running, (typically) background processes, similar to Unix-like daemons. The services you monitor depend on your use case and the specific role of the server in question. The list below provides a good starting point, containing a mix of essential and common services that are relatively role-neutral.
Most of the following services are essential to core Windows functionality. In part 2 of this series, we will explain how to use Windows-native tools to ensure that key services are up and running,
| Display Name | Service Name | Description (source) |
|---|---|---|
| Base Filtering Engine | BFE | Manages firewall and Internet Protocol security policies |
| Background Tasks Infrastructure Service | BrokerInfrastructure | Provides access control for background task execution |
| Cryptographic Services | CryptSvc | Provides three management services: Catalog Database Service, which verifies signatures of system files and new software; Protected Root Service, which controls Trusted Root Certification Authority certificates; and Automatic Root Certificate Update Service, which retrieves root certificates from Windows Update |
| DCOM Server Process Launcher | DcomLaunch | Launches Component Object Model (COM) and Distrbuted Component Object Model (DCOM) servers |
| Diagnostic Policy Service | DPS | Enables system diagnostics and issue resolution for Windows components |
| Windows Event Log | EventLog | Manages events and event logging. Supports logging, querying, subscribing to, and archiving of events |
| COM+ Event System | EventSystem | Supports System Event Notification Service (SENS), which provides automatic distribution of events to subscribing COM components |
| Group Policy Client | gpsvc | Applies settings configured by Group Policy |
| Windows Firewall | MpsSvc | Native firewall to prevent unauthorized network access |
| Performance Logs & Alerts | pla | Collects, logs, and alerts on performance data from local or remote computers |
| Task Scheduler | Schedule | Hosts system-critical scheduled tasks and enables user-configurable scheduled tasks |
| System Events Broker | SystemEventsBroker | Coordinates background work execution for WinRT applications |
| Remote Desktop Services | TermService | Allows remote users to connect interactively to the local machine |
| Windows Management Instrumentation | Winmgmt | Provides a standard interface for accessing management information from the operating system, devices, applications and services |
| Windows Remote Management (WS-Management) | WinRM | Provides remote access to Windows Management Instrumentation (WMI) data and enables event collection |
| WMI Performance Adapter | wmiApSrv | Provides performance library information from WMI providers |
Time to collect
In this post we’ve explored many of the key metrics and events you should monitor to keep tabs on the health and performance of your Windows 2012 servers.
Most of the metrics and events covered in this post should be relevant to general use. Given the number of roles a Windows server can perform, however, over time you will likely identify additional metrics that are particularly relevant to your workloads and users.
Read on for a comprehensive guide to collecting all of the metrics described in this article, using standard tools bundled with Windows Server 2012.
