
Log management solutions can make it easy to filter, aggregate, and analyze your log data. Whether you leverage JSON format or process your logs in order to extract attributes, you can slice, dice, and categorize your logs using the information they provide such as timestamp, HTTP status code, or database user. But different technologies and data sources often label similar information differently, making it difficult to aggregate data across multiple sources. For example, NGINX might name an attribute status while HAProxy uses statusCode. This means you need to use two different attributes to view status code information across all your logs.
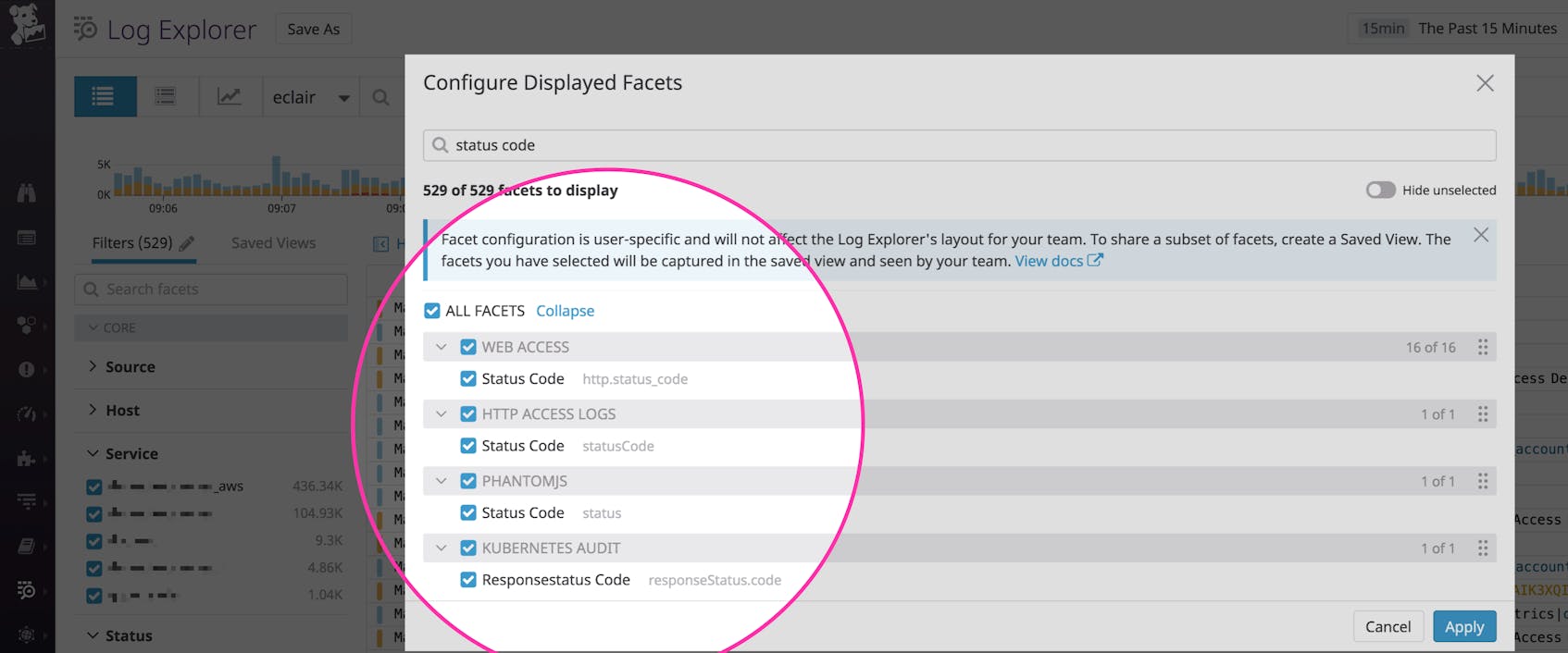
In addition to variations across third-party technologies, different teams within your organization might use different attribute names for the same underlying object. For example, one team might name a user ID user_id while another uses user-id. A naming convention can unify logs across all of these different sources, letting you easily analyze and search for data from your entire environment.
Some organizations try to implement a naming convention manually by asking their teams to change how they log in order to standardize their attributes across all sources of data. But this can require significant changes to your code as you need to reconfigure your loggers and modify each line of code that generates a log. A better option is to implement an automatic, centralized common schema across all your attributes, without having to make any changes to your code or logging strategies.
Why use a common schema?
In a complex environment, you might have several different components emitting web access logs. If they name attributes differently, it becomes much more difficult to analyze HTTP traffic across your entire infrastructure. For example, ELB and NGINX both generate web access logs that include similar information, such as method, status code, etc. But, if we render these into JSON, using default naming conventions for both ELB and NGINX, we can see variations in their naming of similar attributes.

Both logs contain, for example, a client IP address, but ELB labels it client.ip while NGINX uses remote_addr. This makes it more difficult to track a specific client’s activities across your application.
Instead, a common schema uses the same term across both these log sources. For example, Datadog uses the prefix network to automatically identify information related to network communication from any of its log integrations. So the attributes in our example both become network.client.ip. Similarly, data about HTTP requests, such as response status code or request method, are prefixed with http. So now our JSON-formatted logs look like this:

Now you can filter and aggregate logs by network.client.ip or http.status_code and see data across all sources that include that attribute.
Looking across technologies
A common schema enables you to analyze similar information not just from different technologies but from different types of technologies as well. For example, if you want to analyze performance across each part of your system to find the source of user-facing latency, you need a way to unify latency data from across your stack. That means analyzing HTTP response times, database query times, or the duration of Lambda functions, all in one place.
Having a single attribute that covers all log sources that report performance or latency data means you can easily visualize and correlate all of them in a single view. Datadog’s common schema uses the attribute duration and automatically implements it for all of its log integrations, giving you greater insight into your systems without any manual configuration or changes to your loggers.

Integrations automatically adhere to the naming convention
All of Datadog’s built-in log integrations adhere to the common schema by default. For instance, the queries from your database logs will share the attribute db.statement, whether the logs originate from MySQL, Cassandra, MongoDB, or another datastore. Datadog’s processing pipelines automatically enforce the naming convention in one centralized platform, so your teams can easily standardize their logs without modifying their logging strategies or making any changes to their code.
Datadog’s common schema is also extensible. You can use Datadog’s centralized log processing to easily enforce standard attributes across any custom log data by customizing the built-in attributes or creating your own.
Create your own standard attributes
Customizing or adding standard attributes to a naming convention is important for unifying data from custom logs. For example, you might have multiple Java loggers generating custom logs to track business information. With Datadog, you can create new standard attributes or modify existing ones in order to remap team-, product-, or business-specific attributes. In the Datadog app, you define the naming convention, the type of attribute (e.g., string or integer), and the list of all attributes you wish to map to the standard term. See Datadog’s documentation for more details.

Make your log data consistent
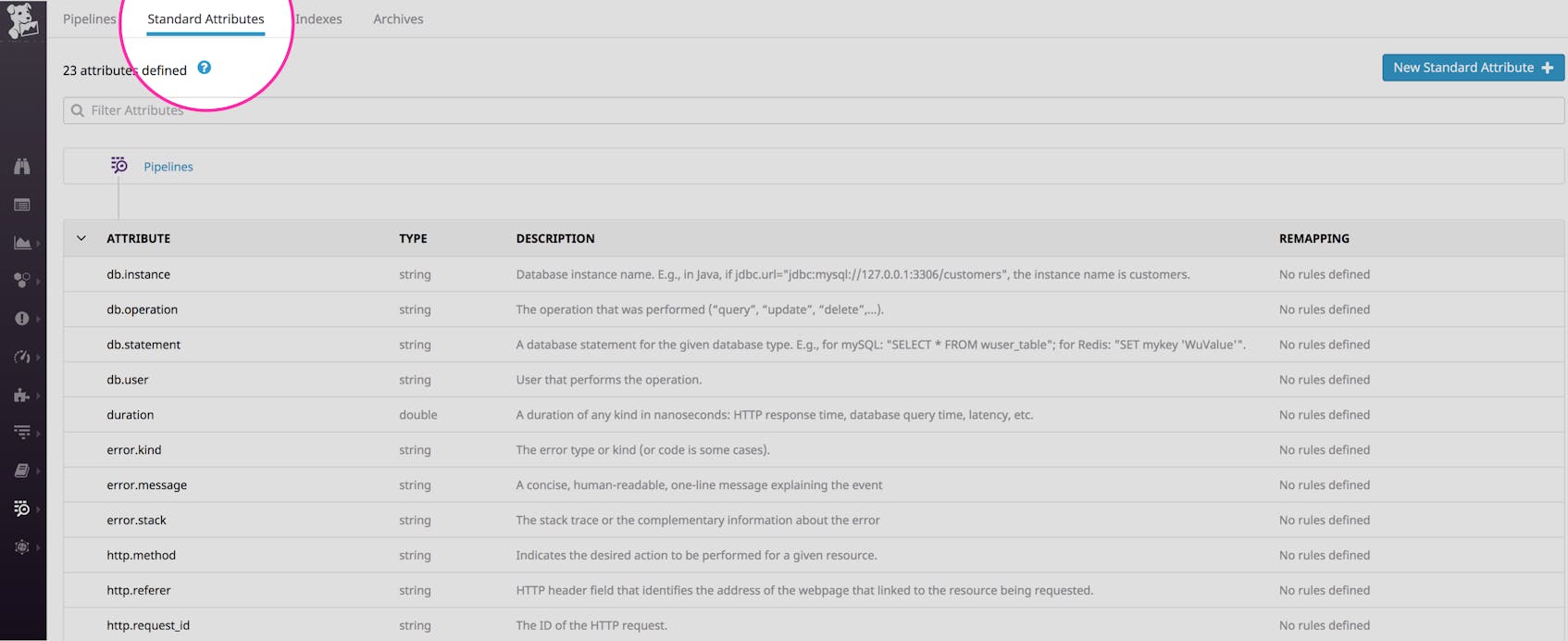
Using a common schema to standardize your log attributes makes it easy to analyze data from across all log sources in your infrastructure, giving you better coverage and visibility into your environment. If you’re already using Datadog to centralize and view your logs, you can take advantage of Datadog’s schema with any of our log integrations without any additional configuration. If you want to begin customizing or creating additional standard attributes, simply go to the Standard Attributes tab of your log configuration.
If you’re not yet using Datadog, start a free 14-day trial.
