

Istio is an open source service mesh that was released in 2017 as a joint project from Google, IBM, and Lyft. By abstracting the network routes between services from your application logic, Istio allows you to manage your network architecture without altering your application code. Istio makes it easier to implement canary deployments, circuit breakers, load balancing, and other architectural changes, while also offering service discovery, built-in telemetry, and transport layer security. Companies like Namely and Trulia use Istio to run their service-oriented architectures.
As with any complex distributed system, getting visibility into your Istio mesh is crucial to keeping your system healthy and available. There are two reasons for this. First, you’ll need to monitor the services running within your Istio mesh, both to know that your services are handling requests as expected and to ensure that you’ve removed any performance bottlenecks. Second, you’ll want to make sure that Istio’s components themselves can function, and do so without becoming an unnecessary resource burden. The two reasons are related: Istio can only route traffic into a consistent and performant service topology if its components are healthy and available. In this post, we’ll show you the metrics that can give you visibility into your Istio mesh.
How Istio works
Istio ships as a cluster of components that run as separate pods within a Kubernetes deployment. (The Istio team is also working on support for other platforms like Nomad and Consul.) You’ll want to monitor each component to ensure the health and performance of your Istio service mesh.
- Envoy is a proxy server that routes traffic through your mesh. Istio injects Envoy as a sidecar within each Kubernetes pod that runs one of your services.
- Pilot builds an abstract model of the services in your mesh and configures the Envoy proxies to manage traffic appropriately for the model.
- Galley validates your Istio configuration and provides that configuration to Pilot and Mixer. This allows you to configure traffic routing, telemetry, and access control by applying Custom Resource Definitions (CRDs) within Kubernetes.
- Citadel manages Transport Layer Security (TLS), and provides certificates and private keys to services to allow for encrypted traffic between Envoy proxies.
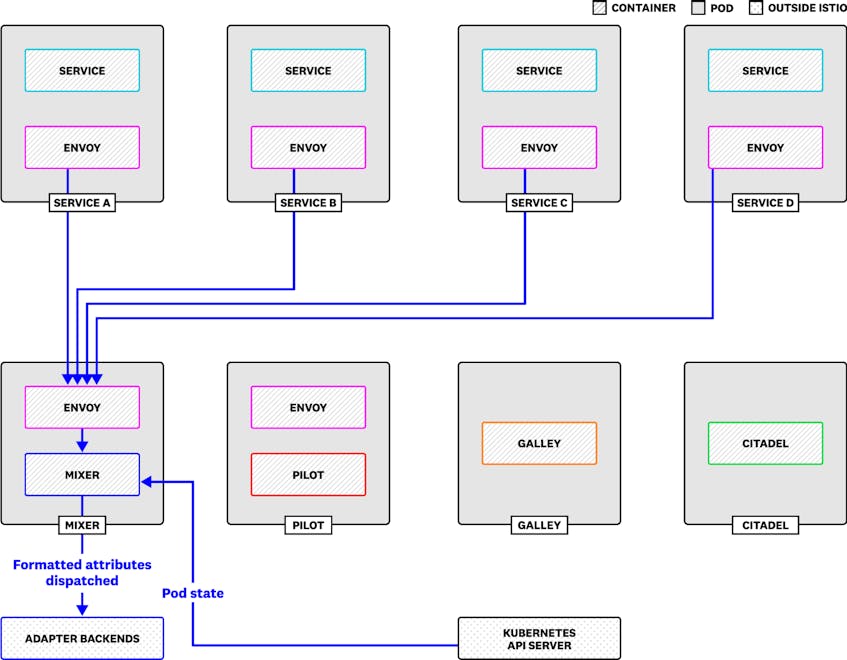
- Mixer enables you to monitor network traffic in your service mesh, passing data from Envoy’s transport-layer traffic and application-layer requests to applications called adapters. Adapters either format the data for consumption by backends such as Prometheus, or generate further data for other adapters to use. Mixer also uses traffic-based data to enable policies for access control, routing, and rate limiting.
In this post, we’ll show you metrics that can give you visibility into each of these components.
Note that as of version 1.4, Istio has begun to move away from using Mixer for telemetry, and can generate certain mesh-level metrics in Prometheus format from within the Envoy proxies. Since this capability is still in its early stages, we’re assuming that you are using earlier versions of Istio, or have enabled Mixer-based telemetry collection with version 1.4.
Key Istio metrics
We’ll begin our survey of Istio metrics with network traffic performance indicators. Istio makes these metrics available by default through Mixer, which extracts them from Envoy network traffic.
After discussing mesh-level traffic metrics, we’ll look at the metrics that each Istio component exposes.
When describing metrics, we’ll use terminology from our Monitoring 101 series, our general framework for collecting metrics, setting alerts, and investigating issues.
Istio mesh metrics
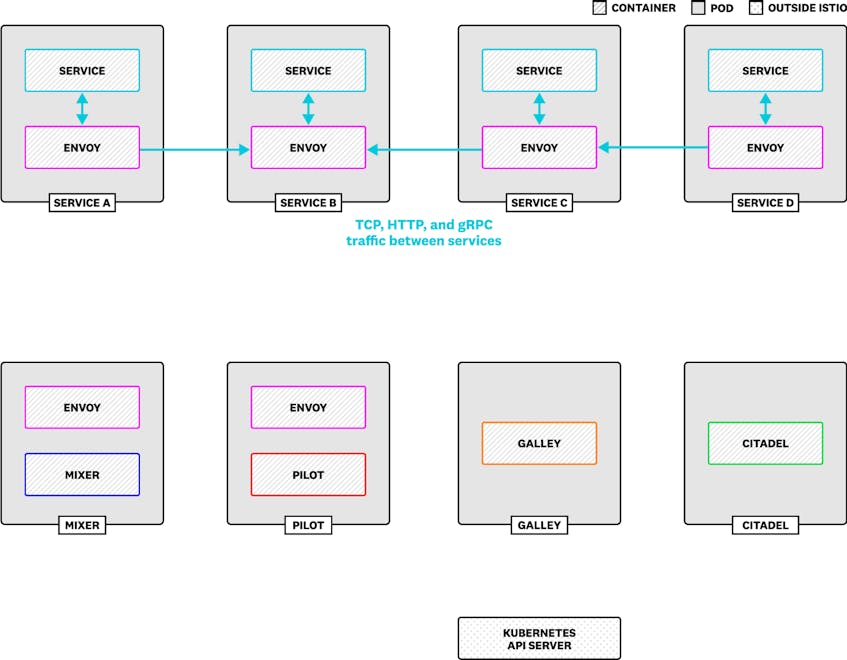
Istio collects data from your mesh using an Envoy filter that runs within proxies, intercepts requests, and provides data to Mixer in the form of attributes. Mixer then transforms these attributes into metrics, traces, and logs. (You can read more about this process in Part 2.) As Istio routes traffic programmatically between services, you can use metrics from your mesh to see the outcome of your Istio configuration, and understand whether your mesh has encountered any issues.
Mixer leaves it up to you how often to query and aggregate these metrics—it simply reports the current value of each metric. Istio’s built-in Prometheus server scrapes metrics from Mixer (along with Pilot, Galley, and Citadel) by default every 15 seconds, though you can choose another backend for collecting metrics.
When Mixer collects metrics from Envoy, it assigns dimensions that downstream backends can use for grouping and filtering. In Istio’s default configuration, dimensions include attributes that indicate where in your cluster a request is traveling, such as the name of the origin and destination service. This gives you visibility into traffic anywhere in your cluster.
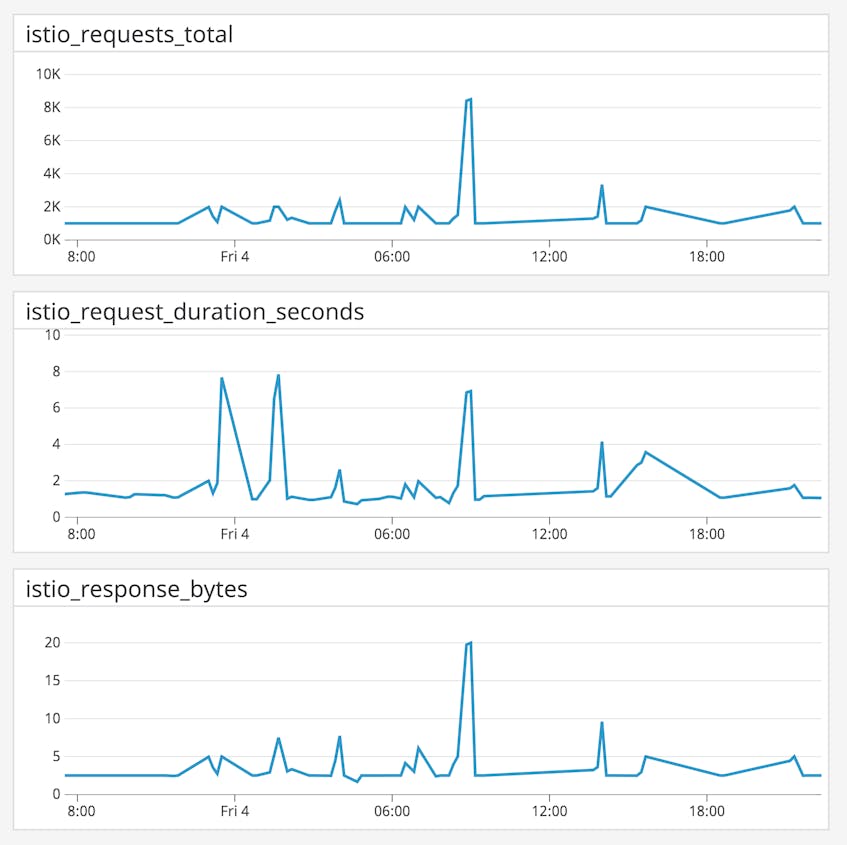
| Name | Description | Metric type | Availability |
|---|---|---|---|
| requests_total | Number of requests received from Envoy proxies within the evaluation window | Work: Throughput | Default Mixer configuration |
| request_duration_seconds | How long it takes an Envoy proxy to process an HTTP or gRPC request | Work: Performance | Default Mixer configuration |
| response_bytes | The size of the response bodies, in bytes, that an Envoy proxy has processed | Work: Throughput | Default Mixer configuration |
While Envoy proxies output their own statistics, this guide will focus on the mesh-level metrics that Istio collects. As we’ll explain in Part 2, Istio’s network traffic metrics include metadata from the services running within your mesh. Envoy’s statistics, which are beyond the scope of this guide, are useful for investigating issues with specific Envoy proxies. You can see which statistics your proxies collect in the Envoy documentation.
Metric to watch: requests_total
The request count metric indicates the overall throughput of requests between services in your mesh, and increments whenever an Envoy sidecar receives an HTTP or gRPC request. You can track this metric by both origin and destination service. If the count of requests between one service and another has plummeted, either the origin has stopped sending requests or the destination has failed to handle them. In this case, you should check for a misconfiguration in Pilot, the Istio component that routes traffic between services. If there’s a rise in demand, you can correlate this metric with increases in resource metrics like CPU utilization, and ensure that your system resources are scaled correctly.
Metric to watch: request_duration_seconds
The request_duration_seconds metric measures how many seconds it takes to process any HTTP or gRPC request sent through Istio’s service mesh. This metric measures the approximate duration of the whole request-response cycle, i.e., beginning when Envoy receives the first byte of a request and ending when Envoy sends the last byte of the response.
This metric is a good overall performance indicator for your services. Higher-than-normal values can point to above-average CPU utilization, database write latency, higher execution time for new code, new downstream services within the request path, and other possible issues. Unusually low values can indicate that your services are not completing the work you expect them to (e.g., if accompanied by an increase in 5xx status codes). If some application pods are showing degraded performance, consider passing less traffic to them by using Istio features like routing rules and rate limiting until you can alleviate the load, or scaling up your application deployment.
Metric to watch: response_bytes
The response_bytes metric reports the size of the response bodies, in bytes, that Envoy has processed. If there is a drastic change in this metric, check your Istio logs for possible issues. For instance, a much lower response size might indicate that some services have begun returning 4xx and 5xx response codes. Mixer’s default configuration includes the response code as a dimension. Depending on your metrics collection backend, you can aggregate requests_total by response_code to see if Istio is returning more client– or server-side errors. You can also consult your Istio logs, which we’ll discuss in Part 2.
Pilot metrics
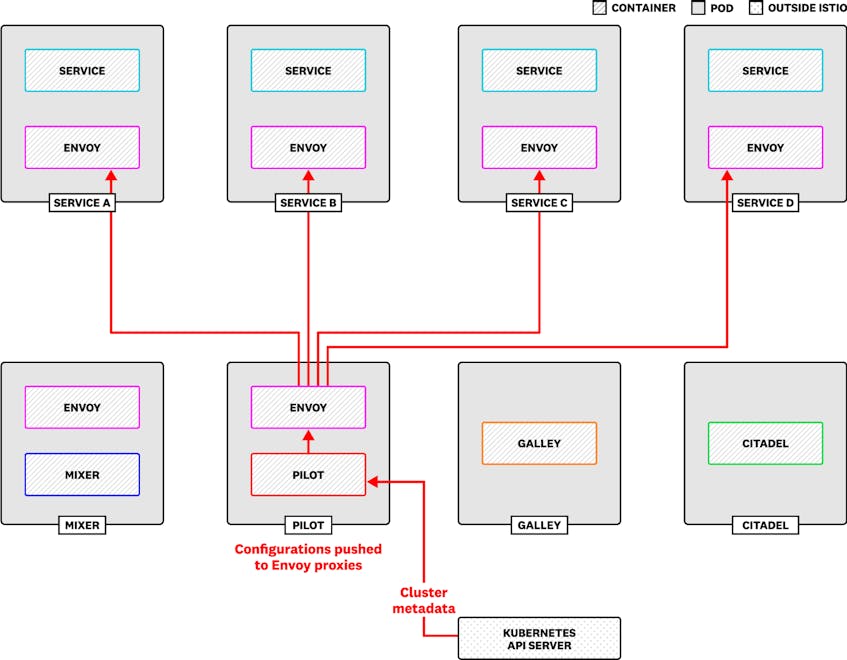
Pilot maintains an abstract model of your mesh, such as a list of currently running services, and uses the model to configure the Envoy sidecars. Pilot updates the abstract model based on changes in your platform. For example, Pilot communicates with the Kubernetes API server for the statuses of nodes, pods, services, and endpoints.
These metrics can help you detect when Pilot runs into complications with configuring Envoy, and ensure the availability of services in your mesh.
| Name | Description | Metric type | Availability |
|---|---|---|---|
| pilot_xds | Count of concurrent xDS client connections for Pilot | Other | Pilot Prometheus exporter |
| pilot_xds_pushes | Count of xDS messages sent, as well as errors building or sending xDS messages | Work: Throughput, Errors | Pilot Prometheus exporter |
| pilot_proxy_convergence_time | The time it takes Pilot to push new configurations to Envoy proxies (in milliseconds) | Work: Performance | Pilot Prometheus exporter |
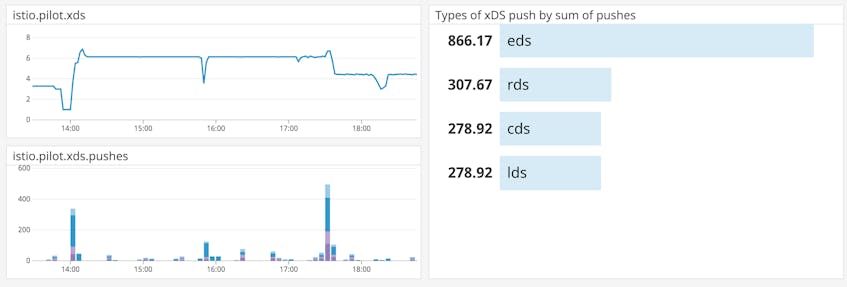
Metric to watch: pilot_xds, pilot_xds_pushes
Pilot pushes configuration changes to Envoy proxies by using Envoy’s built-in management APIs, which together are called xDS. The Endpoint Discovery Service (EDS) API keeps track of members in a cluster, for example, while the Route Discovery Service (RDS) listens for changes in request routing configuration.
Pilot implements new user configurations by pushing xDS messages to clients, so monitoring xDS pushes gives you a good indication of demand on your Pilot xDS server. The pilot_xds metric indicates the number of xDS clients Pilot is currently connected to. If Pilot is using memory or CPU more heavily than usual, look for an uptick in xDS clients.
Another factor in Pilot’s performance is the rate of xDS pushes, which increases with the number of clients as well as the number of Pilot configuration changes. The pilot_xds_pushes metric counts the messages that Pilot has pushed to xDS APIs, including any errors in building or sending xDS messages. You can group this metric by the type tag to count xDS pushes by API (e.g., eds or rds)—if there are errors, Pilot will record this metric with a type tag like rds_builderr or eds_senderr. You can also track the metric without the type tag for an overall view of xDS throughput.
If high Pilot demand is a problem, consider deploying more Pilot pods. You can also edit the PILOT_PUSH_THROTTLE environment variable within the Pilot pod’s manifest, reducing the maximum number of concurrent pushes from the default of 100.
Metric to watch: pilot_proxy_convergence_time
This metric measures the time (in milliseconds) it takes Pilot to push new configurations to Envoy proxies in your mesh. This operation is potentially slow, depending on the size of the configuration Pilot is pushing to the Envoy proxies, but necessary for keeping each proxy up to date with the routes, endpoints, and listeners in your mesh. You’ll want to monitor it to keep it at a reasonable level, i.e., one that won’t hurt the availability of your services.
Galley metrics
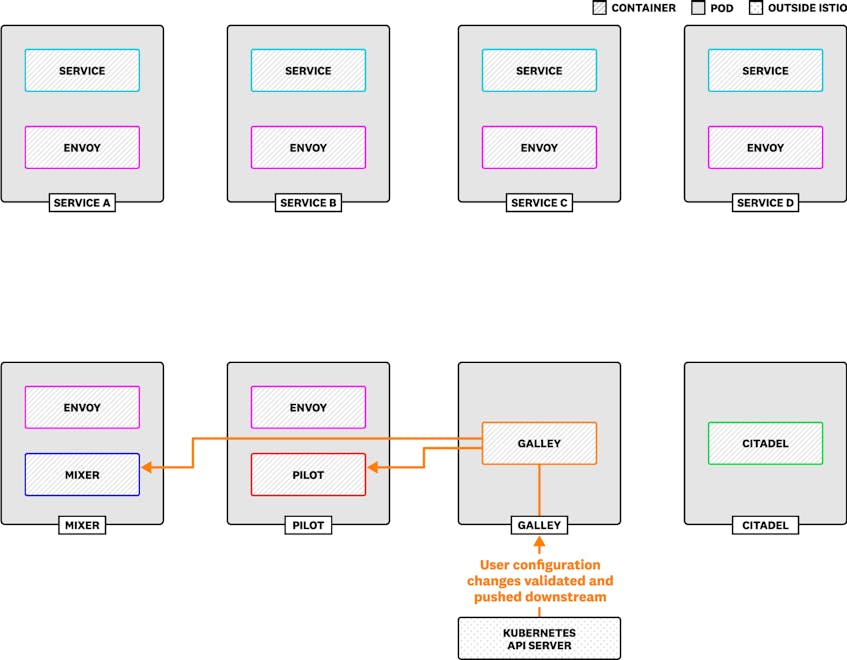
Galley allows you to operate Istio by changing the configuration of the platform that runs your mesh—currently, this means that you can configure metrics, add routing rules, and perform other tasks by applying Kubernetes CRDs. When you apply a new configuration, Galley will detect the change, validate your new manifests, and make your changes available to Pilot and Mixer to implement. You can monitor Galley to ensure that operators pass valid changes to Pilot and Mixer without putting too much load on your Galley server.
| Name | Description | Metric type | Availability |
|---|---|---|---|
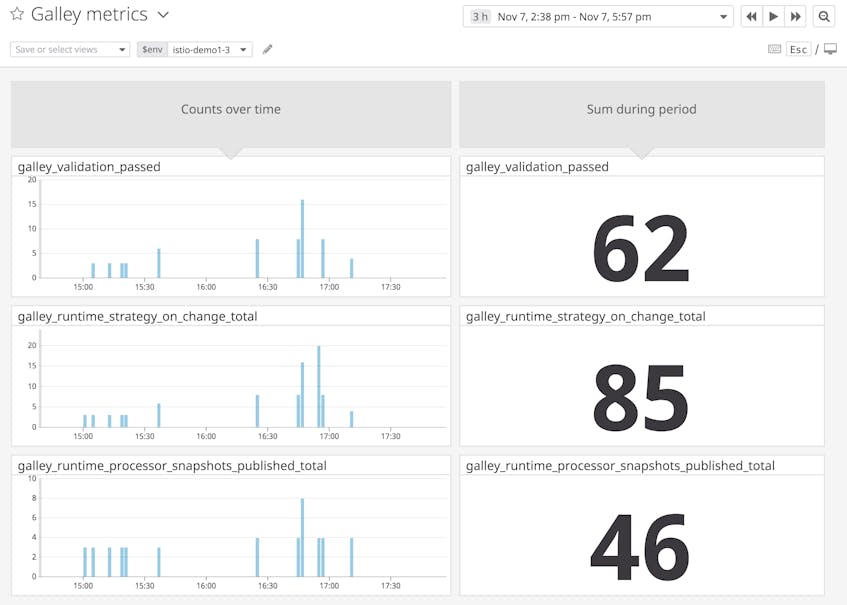
| galley_validation_passed | Count of validated user configurations | Work: Throughput | Galley Prometheus exporter |
| galley_validation_failed | Count of configuration validation failures | Work: Errors | Galley Prometheus exporter |
| galley_runtime_processor_snapshots_published_total | Count of snapshots published by a Galley strategy | Work: Throughput | Galley Prometheus exporter |
| galley_runtime_strategy_on_change_total | Count of configuration changes processed by a Galley strategy | Work: Throughput | Galley Prometheus exporter |
Metric to watch: galley_validation_passed, galley_validation_failed, galley_runtime_processor_snapshots_published_total, galley_runtime_strategy_on_change_total
You can monitor Galley’s responses to user configuration changes with counters for different steps within the process. These metrics indicate how much work Galley is doing. If Galley is under heavier than normal load, they will offer possible reasons why.
When an operator applies a new Kubernetes manifest that targets one of the CRDs that Galley tracks (e.g., Mixer template instances), Galley validates the configuration using its validation webhook. If the configuration is valid, Galley increments the metric galley_validation_passed. Otherwise, Galley increments galley_validation_failed. You can examine your Galley logs for specific reasons why validation has failed. This log, for example, shows that a user attempted to configure an Istio Gateway for UDP, a protocol that Gateways do not support.
2019-12-05T16:34:44.317683Z info validation configuration is invalid: invalid protocol "UDP", supported protocols are HTTP, HTTP2, GRPC, MONGO, REDIS, MYSQL, TCPGalley will also process the configuration change (and increment galley_runtime_strategy_on_change_total), and will make the configuration available to Pilot or Mixer by publishing a snapshot (and incrementing galley_runtime_processor_snapshots_published_total).
Galley implements two strategies for producing snapshots from configuration changes. For service entries, the strategy is immediate, meaning that Galley will publish a snapshot as soon as you change one of the services you have registered with Istio. For all other CRDs, Istio uses a debounce strategy, which prevents configuration changes from overwhelming Galley by limiting them to a steady cadence.
You can compare the values of Galley’s counters to get insights into configuration processing within Istio. If strategies process changes more frequently than they produce snapshots, a debounce strategy is probably responding to only a subset of the changes—if Galley hasn’t processed a new configuration, this may be why. And if Galley is facing heavier-than-acceptable resource usage along with a high number of processed changes or published snapshots, you should investigate the source of the new configurations.
Finally, since you can configure Galley’s validation webhook, there’s a risk that it will accept invalid configurations—consider this possibility if you see an uptick in passed validations relative to failed ones.
Note that Galley’s validation webhook runs separately from its configuration processing component (i.e., what publishes snapshots from strategies)—the count of validations (passed and failed) won’t necessarily line up with the counts of galley_runtime_strategy_on_change_total and galley_runtime_processor_snapshots_published_total.
Citadel metrics
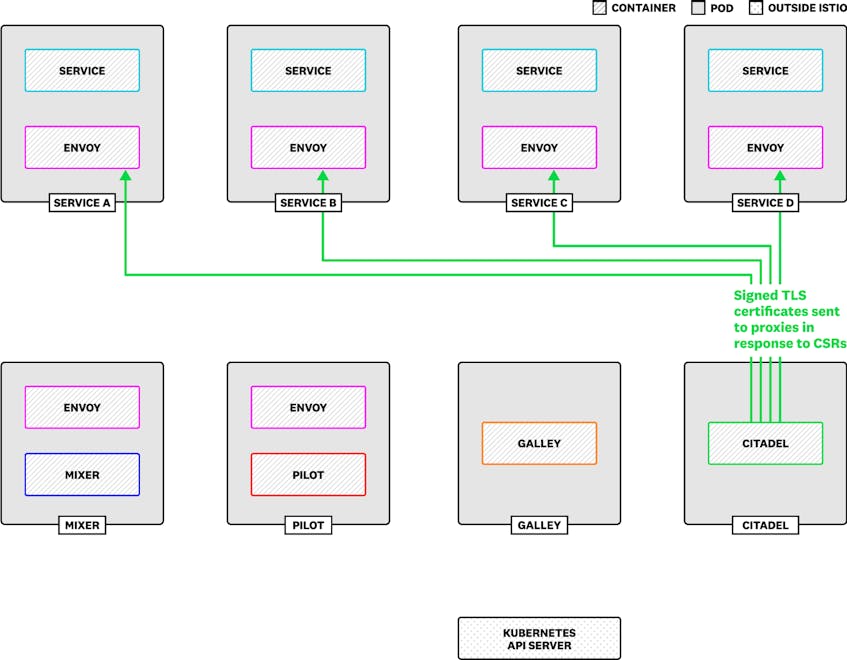
Citadel runs its own gRPC service to handle certificate signing requests (CSRs) from your Istio-managed infrastructure, acting as a Certificate Authority that signs and issues TLS certificates. Citadel signs each CSR, then provides the certificate to the Envoy mesh.
Monitor Citadel to confirm that it is signing the certificates your services need without errors, and to ensure that Istio can send secure traffic between services.
| Name | Description | Metric type | Availability |
|---|---|---|---|
| csr_count | Count of certificate signing requests (CSRs) handled by Citadel | Work: Throughput | Citadel Prometheus exporter |
| success_cert_issuance_count | Count of TLS certificates issued to clients | Work: Throughput | Citadel Prometheus exporter |
| csr_parsing_err_count | Count of errors Citadel encountered while parsing CSRs | Work: Error | Citadel Prometheus exporter |
| id_extraction_err_count | Count of errors Citadel encountered while extracting IDs from CSRs | Work: Error | Citadel Prometheus exporter |
| csr_sign_err_count | Count of errors Citadel encountered while signing CSRs | Work: Error | Citadel Prometheus exporter |
| authentication_failure_count | Count of errors Citadel encountered while authenticating CSRs | Work: Error | Citadel Prometheus exporter |
Metrics to watch: csr_count, success_cert_issuance_count, csr_parsing_err_count, id_extraction_err_count, csr_sign_err_count, authentication_failure_count
You can monitor the amount of work Citadel is performing by tracking the number of CSRs it has handled (csr_count) and the number of certificates it has successfully issued (success_cert_issuance_count). Both metrics are cumulative counts, and you’ll want to make sure your monitoring platform can graph the change in these metrics over a predefined interval in order to extract meaning from them.
The difference between these counts indicates how often Citadel has failed to issue a certificate. If the difference is rising, you can check Citadel’s error metrics for possible causes. Citadel could be encountering an error while parsing the CSR (csr_parsing_err_count), extracting an ID from the CSR (id_extraction_err_count), or signing the CSR (csr_sign_err_count). And if Citadel fails to authenticate a CSR, it will increment the metric authentication_failure_count. Since Citadel publishes a log every time it increments one of these error metrics, you can get more context by inspecting your Citadel error logs.
Mixer metrics
| Name | Description | Metric type | Availability |
|---|---|---|---|
| mixer_runtime_dispatches_total | The count of dispatches to adapters over the evaluation window | Work: Throughput | Mixer Prometheus exporter |
Metric to watch: mixer_runtime_dispatches_total
While Mixer was designed with reliability in mind, operators relying on Mixer for monitoring mesh traffic should still keep an eye on its performance, as an unhealthy or overloaded Mixer pod would make it more difficult to spot other issues with your infrastructure.
When Mixer makes attributes available to an adapter, this is known as dispatching the data. Mixer dispatches attributes to adapters in the form of template instances, conventional formats for presenting data, such as log entries, trace spans, and metrics. (The mesh-level metrics we introduced earlier are instances of the metric template.)
To get a handle on how much work Mixer is doing within your Istio deployment, and how that affects the rest of your system, you should track mixer_runtime_dispatches_total, the number of template instances dispatched to Mixer adapters. If increases in this metric correspond with a jump in CPU utilization within your Mixer pods past an acceptable threshold, you may want to reduce the number of instances Mixer dispatches by changing your configuration.
Mixer tags the mixer_runtime_dispatches_total metric with the name of the adapter it is sending template instances to. You can group this metric by adapter to get a cross-section of the demand on your Mixer pods. In addition to adapters for monitoring backends like Prometheus, Mixer can dispatch instances to an adapter for allowing or denying IP addresses, an adapter that helps perform rate limiting, and various others.
You may also be running the Kubernetes Env adapter (e.g., if you’ve used Helm to install Istio’s default chart), which stores the state of your cluster’s Kubernetes pods in memory by periodically querying the Kubernetes API server. The Kubernetes Env adapter combines its metadata with attributes from Envoy traffic, and produces new attributes that you can use to, for instance, generate metrics.
If Mixer is suffering from heavy load, and it is not possible to reduce dispatches to specific adapters by changing your configuration, you may need to deploy more instances of the Mixer pod.
Performance on two planes
In this post, we’ve shown you the metrics that can bring visibility to two critical aspects of Istio. The first aspect is the health and performance of Istio’s internal components—all of these are important for your Istio mesh, and each component exposes key work metrics. The second aspect is the traffic that runs through your Istio mesh, which reflects both the health and performance of your services and your current mesh configuration. Metrics like request count and duration give you visibility into the performance of your service mesh, and can help you gauge the success of your load balancers, canary deployments, and other distributed architectures.
Now that you know which metrics to monitor, Part 2 will introduce the built-in techniques that Istio offers for monitoring them, in addition to other kinds of data such as logs and traces.
Acknowledgments
We’d like to thank Zack Butcher at Tetrate as well as Dan Ciruli and Mandar Jog at Google—core Istio contributors and organizers—for their technical reviews of this series.
