

Typical HAProxy monitoring processes and their shortcomings
Monitoring issues through HAProxy typically involves parsing the output of the HAProxy Status Page (reproduced below). The page is designed to give you a real-time report of HAProxy current performance and state: how many pools there are, how many servers per pool, how much traffic HAProxy has served, and how many times backend servers have failed. You can use this report in a few different modes:
- Periodic reporting (e.g. a cron job that gets the value once a day or once a week)
- Ad-hoc reporting (e.g. whenever slowness or errors are reported).
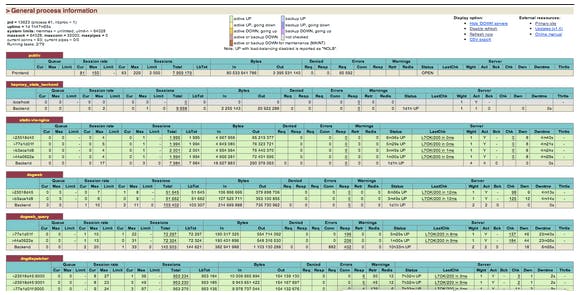
Because the report is a snapshot of HAProxy at a given point in time, it is meant to be refreshed very frequently (the official documentation uses 5 seconds as an example). It is not saved or aggregated over time. Instead, it is discarded almost immediately. Thus, historical data that are critical to figure out past issues and anticipate future ones, are lost.
Even if the report is generated on a regular basis (e.g. via a cron job once an hour) it is bound to miss issues that occurred between each report generation. This limitation due to sampling fundamentally limits the granularity of the issues that the report could pick up, to twice the reporting period, i.e. 2 hours in the cron example.
So neither way is enough to do a comprehensive job at monitoring HAProxy around the clock.
“Traditional” HAProxy monitoring is broken because:
- Regardless of how often reports are generated, it always lacks historical context and suffers from aliasing.
- It’s overly relied upon to diagnose issues rather than being part of comprehensive system monitoring process.
- It doesn’t allow users to be proactive in their approach to infrastructure management.
These issues are explained in more detail below.
1. Infrequent HAProxy monitoring reports with no historical context
Infrequent or reactive monitoring with no historical context is problematic for a number of reasons. First, you need to be watching the HAProxy console to catch problems when they occur. If a pool of servers goes offline in the middle of the night, a weekly or even daily report will not catch the exact time when the incident happened. If you wait for your customers to report slowdowns and look at the report only then, you still won’t get the whole story.

Even if you keep the HAProxy monitoring console on display around the clock, you will still risk missing emerging issues. Here’s why: the console tabulates counters since the time the HAProxy started (or when statistics were reset). This is fine to measure overall traffic served, but it does not cut it to track errors since past errors remain displayed until the statistics are reset or HAProxy is restarted.
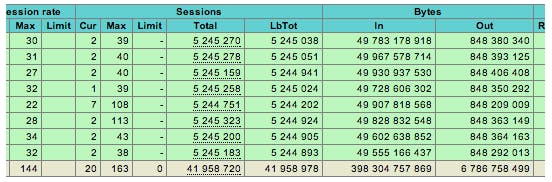
In addition to the risk of missing needed information, strictly reactive monitoring, i.e. in response to a reported problem, gives no basis for comparison to understand what normal conditions look like. So it can be difficult to detect small changes in your systems that are warning signs of larger problems, such as the servers’ response time or error rates creeping up beyond the acceptable. Even if you’re doing periodic monitoring on a hourly, daily, or weekly basis, these canaries in the coal mine will still be missed if they’re occurring second by second or minute by minute, as they often are.
2. Failure to correlate HAProxy monitoring with other monitoring and events
Another problem with traditional HAProxy monitoring is that it only monitors HAProxy. Rarely are the problems actually with HAProxy itself, a testament to the quality of the HAProxy code. Instead, HAProxy serves as an easily visible place where many other issues surface. In order to understand root causes, you need a broader picture of your system.
For example, when a server is getting too slow, HAProxy will simply mark it as “down.” This doesn’t tell you if it’s a problem with the server itself or a problem with one of the dependencies, e.g. a slow database down the chain. To truly understand, you need to also capture the database performance metrics. In general, you need to monitor more than just HAProxy. You need to examine metrics and events from the web server, the application server, and the database server, just to name a few. Depending on the complexity of your system, a comprehensive overview could include anywhere from 1-2 services to well over 10.
Without comprehensive monitoring coverage and the ability to easily correlate performance across the stack, you run the risk of never fully identifying root causes.
3. Infrequent and uncorrelated HAProxy monitoring lacks predictive capabilities
When monitoring is done infrequently, without historical context, and without correlation to other events, you rarely have enough information to see problems as they emerge. Instead, you’re forced to wait until they bubble up to bigger issues that affect customers.
Server capacity is a good example. When customers begin reporting slowness in your system, HAProxy monitoring allows you to see the issue once it becomes a larger customer-reported problem, for instance when the reported downtime per server increases. You can then react: identify the root cause and scramble to fix the problem.
A better solution is to be proactive by anticipating when issues will emerge and responding before they affect customer experience. If you were monitoring your entire stack on a real-time basis and maintaining historical information you would be able to see changes to the performance of your stack that signal the potential for issues in the near future. For instance, servers coming in and out of the HAProxy pools frequently could be signs of looming capacity issues, or buggy code introduced in the stack.
By further correlating HAProxy pool changes with performance metrics from the rest of your stack you would quickly be able to link the problem to corresponding events such code releases or spikes in customer traffic. The combination of frequent monitoring, historical context, and correlation of metric across your entire system allows you to predict many larger issues by detecting smaller changes. This is critical for HAProxy users who want to be proactive rather than reactive in their approach to infrastructure integrity.
Traditional HAProxy monitoring is inadequate, but similar problems of infrequent reports, uncorrelated information, and lack of predictive capacities exist in many monitoring systems that target a single application.
Datadog’s approach to HAProxy monitoring
At Datadog, we decided to improve our HAProxy monitoring processes and developed support for the shortcomings listed above. Datadog archives HAProxy data, and is able to correlate with other systems in order to quickly detect where a problem that may affect HAProxy is actually occurring. Graphing and alerting can be set up based on this data in order to predict when issues may occur. You can sign up for free to try these capabilities out with HAProxy and the other systems in your environment.
