

The introduction of advanced statistical methods is reshaping the UX of alerts.
This blog post is adapted from my Monitorama AMS 2018 talk. Slides from the talk and Framer prototypes for all demos are available at: https://github.com/DataDog/MonitoramaEUDesignForAI
I’ve been designing monitoring tools for almost 10 years now, and in that time a lot has changed. The infrastructure we build software on, for example, has been transformed multiple times—moving first from physical hosts to VMs in the cloud, then from VMs to containers, and now from containers to serverless and cloud service-based infrastructure.
With the introduction of advanced statistical methods into alerting I think we’re seeing the first major transformation in alerting UX, so I want to unpack it and talk about where things are going.
Alerting UX Today
See the static threshold prototype →

Nearly all alerts today are defined using some combination of these 4 dimensions:
1. Scope
The hosts, containers, services, or other targets to watch. The alert might be as simple as ensuring each target is responding, in which case not much more is required. About a third of all alerts in Datadog take this form.
2. Metric
Some number of metrics are available to track for the specified scope (like the free disk space on a host), and you can pick one or more of these to alert on.
3. Threshold(s)
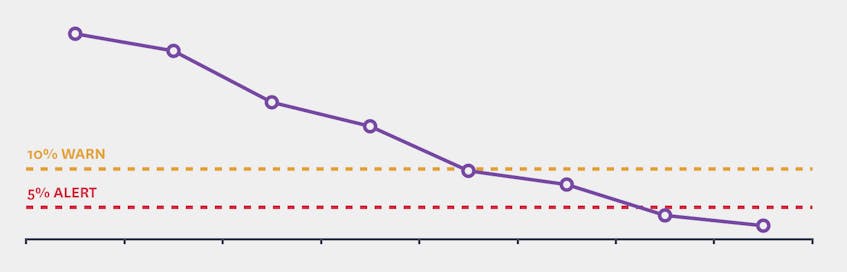
After choosing a metric, you set the threshold to alert. Nearly two thirds of all alerts in Datadog are static thresholds of the form:
If Free Disk Space is equal to Zero, alert
You can also define multiple thresholds. If you don’t want to run out of disk space, you can’t simply be notified when free space reaches zero—by then it’s too late. You might set a critical threshold at 5% free and a second warn threshold at 10% to check the trend and guess how much time you have before hitting that critical threshold.
4. Time
There’s almost always an additional dimension attached to the metric and threshold, which is a range of time or duration. For example, you may require that the metric be above the defined threshold for at least 5 minutes and/or within the last hour.
To see an example workflow, check out monitor creation in Datadog.
Limitations of Today’s Alerting UX
These constraints have existed for so long that it’s easy to be blind to them. It’s only with a bit of exposure to the possibilities of algorithmic alerting that I’ve become more aware of them, and they’re the jumping-off point for the changes on the horizon.
Static Thresholds Don’t Adapt
Whether a system is growing and changing or a temporary event (say a busy holiday shopping period for an e-commerce site) alters baseline levels, static thresholds are…well, static. They don’t adapt to changing conditions or environment, and they require regular review and updates to remain useful.
Warning Thresholds Are a Crutch
Indeed, warning thresholds are often a crutch to allow for a safe amount of time before a critical alert threshold is reached. They’re like a heads-up to eyeball a metric and see what’s happening. You might simply look at the graph and decide it’s safe to wait—but with potentially hundreds or thousands of alerts configured this way, these warnings become a significant source of both false positive and nuisance alerts.
Scope Has to Be Defined Up Front
The most basic constraint of alerting systems today is that they need to be told what to watch. Scope is actually more flexible than other dimensions, in that you can define a group of targets to watch and any new group member will automatically be tracked. You’re still constrained by what you’ve told the system to watch, though, which can lead to lots of duplicated effort and maintenance.
Algorithmic Alerting
A new kind of alerting UX is beginning to take shape. Algorithmically driven alerting comes in 3 main varieties:
- Forecasting
- Anomaly detection
- Outlier detection
Forecasting
See the forecast prototype →
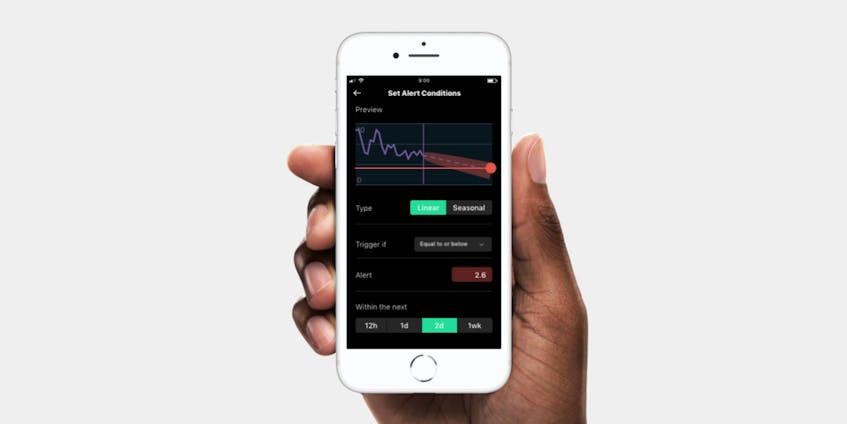
Forecasts take a similar form to static threshold alerts, but with one key difference: where a static threshold simply recognizes values above or below it, a forecast uses past data to predict when a threshold will be reached.
A static threshold is defined using the form:
If Free Disk Space is equal to Zero, alert
Forecast alerts use the form:
If Free Disk Space will be Zero in the next 24 hours, alert
This difference in structure adds a lot of flexibility to the threshold and time dimensions, making the system responsible for tracking the metric over time and estimating when it will cross the specified threshold. You can also decide how much time you need to fix the problem. For example, freeing up disk space might be quick while rebalancing a Kafka cluster might take longer.
More significant, though, is that you no longer need separate warning and critical thresholds. Since the system is watching the metric trend, you can be confident you’ll have enough time to remedy the problem without giving yourself a heads-up via that second warning threshold. For certain kinds of thresholds, like free disk space, this can be really handy.
Anomaly Detection
See the anomaly detection prototype →
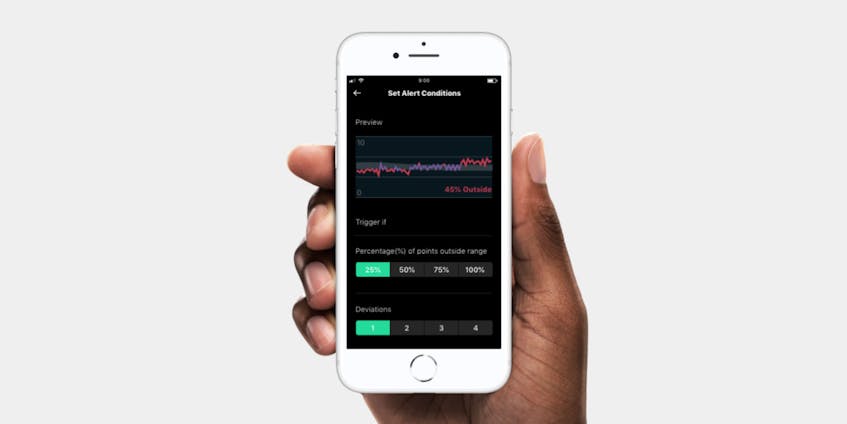
Similar to forecasting, anomaly detection looks at past behavior for the scope you’ve set and predicts what should be happening now. Using both a configurable confidence interval around that and a specified seasonality (like the trend over a day or a week), you can be alerted when the deviation from normal behavior is too great.
Outlier Detection
Unlike forecasting and anomaly detection, outlier detection doesn’t take past behavior into account. Instead, it looks at a group of things that should all be behaving the same way (say the request count to a group of web servers all receiving traffic from the same load balancer) and tells you if any of the group members is not like the others.
Patterns
What all these methods have in common is that they introduce a lot of additional flexibility in how the system tracks thresholds and utilizes time. They’re still created like alerts, though, with their metrics and scopes defined when created. The most fundamental constraint of an alert is that you have to opt into watching something. Going beyond that limitation requires a major shift in alerting UX.
Algorithmic Feeds
See the algorithmic feed prototype →
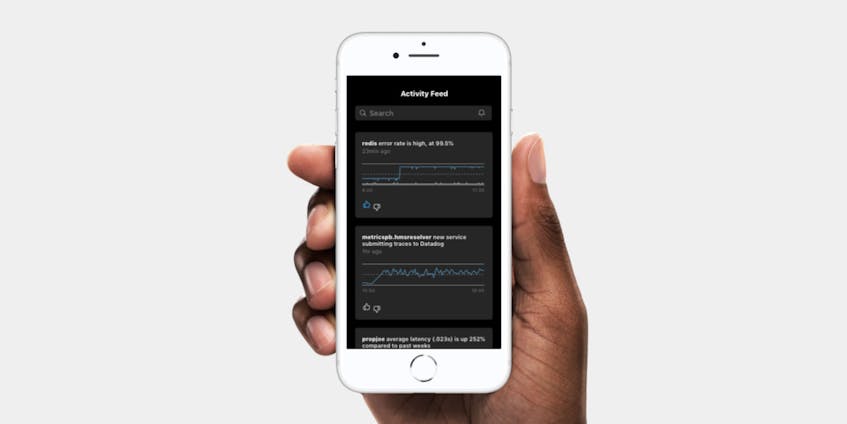
Algorithmic feeds may use some of the same methods as algorithmic alerting but don’t require all the upfront configuration that alerts do. The algorithms can be let loose on a system with very loose constraints so that you no longer have to define the individual scopes and metrics to alert on. Some examples of this are Slack Highlights and Datadog’s own Watchdog.
The most dramatic shift in UX introduced by these feeds is their ability to watch things you haven’t explicitly configured. Anomalous and outlier behaviors specifically can beenfit from a medium like a feed, given their somewhat intractable definitions and unpredictable timing.
They’re still in their infancy but these feeds are showing a lot of promise. The shift from opt-in alerting to feeds could prove to be the most dramatic change in the history of alerting UX, and if social media has taught us anything it’s that we can effectively train algorithms to show feeds of activity that people will be really interested in.
That brings us to the potential benefits of user input into these feeds…
Supervised Algorithmic Feeds
Once your monitoring system is generating a feed of events, you need a way to train it on what you want to see. We’re all accustomed to doing this on social media, with “likes” forming the basis of everything we see in our feeds. In an on-call rotation it’s not so simple, though, for two reasons:
1. You’re On Call
These tools wake you up at night. Information needs to be clear and actionable, and context needs to be provided. A black-box algorithm surfacing activity with no explanation or context will only frustrate you.
One benefit of static thresholds is that you can always understand why the alert triggered, and this clear understanding is the main obstacle to the wide-scale adoption of algorithmic alerting.
2. You’re On Teams
You’re not the only person responding to an alert, and there’s a lot of value in everyone on your team seeing the same things at the same times. You don’t want a feed that’s personalized to you alone, because then you can’t be sure that your team is seeing the same things.
There is one prediction I feel confident making:

Likes and individual personalization are not the future of alerting UX
What you need is a more specific set of actions to match alerts or their underlying dimensions (scope, metric, threshold, time of the alert) to the set of people that will be interested in them. Some examples:
- The web team is responsible for this service, so any alerts for the service should go to them
- A forecast shows a system running out of capacity in the next month. The engineering team leads who are responsible for capacity planning should be aware of these
- The behavior of this metric correlates highly with other metrics for which you’ve seen alerts in the past, and you can choose to see more activity for this metric
Matching Patterns to People
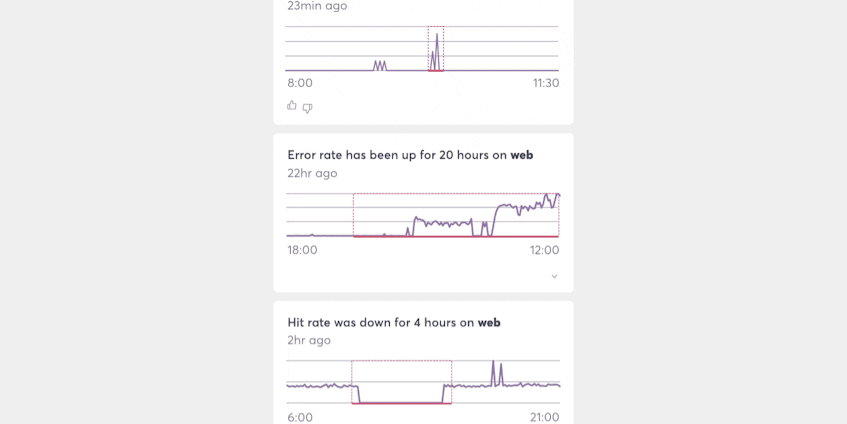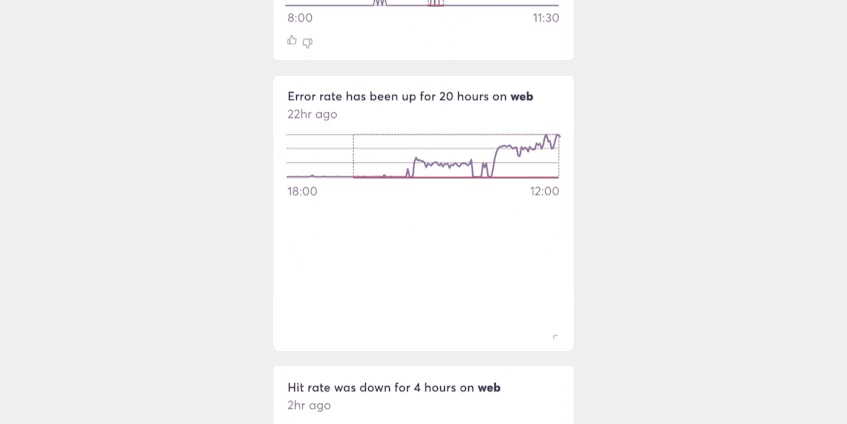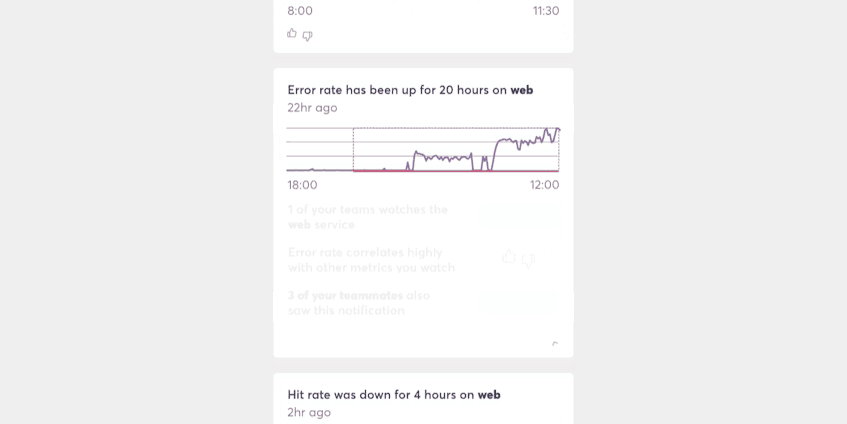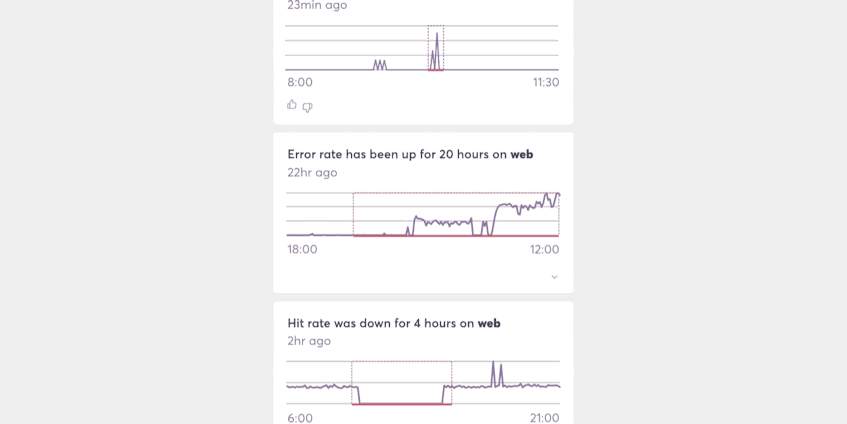
If the future of alerting UX is one that uses feeds to surface important events to people and teams, then our ability to match the patterns of those events to the people who care about them will determine the quality of that experience.
Doing that well will expand the reach of all 4 alerting dimensions to the point where manually defined alerts are no longer necessary. Similarly, the technical limitations today that make turning algorithms loose on an entire system prohibitively expensive will gradually disappear, making wide-scale adoption possible.
Help us define the future of alerting UX. Join us!
