


Recently we extended the Datadog Agent to support extracting additional metrics from Kubernetes using the kube-state-metrics service. Metrics are exported through an HTTP API that supports content negotiation so that one can choose between having the response body in plain text format or as a binary stream encoded using Protocol buffers.
Binary formats are generally assumed to be faster and more efficient, but being Datadog we wanted to see the data and quantify the improvement. We hope the results documented here will help save you time and improve performance in your own code. But before we dive into our findings, let’s start with Protocol buffers 101.
A gentle introduction to Protocol buffers
Protocol Buffers is a way to serialize structured data into a binary stream in a fast and efficient manner. It is designed to be used for inter-machine communication and remote procedure calls (RPC). This can be used in many different situations, including payloads for HTTP APIs. To get started you need to learn a simple language that is used to describe how your data is shaped, but once done a variety of programming languages can be used to easily read and write Protobuf messages - let’s see a simple example in Python.
Let’s say we want to provide a list of metrics through an HTTP endpoint: a metric is something with a name, a string identifier for the type, a floating point number holding the value and a list of tags, simple strings like “env:prod” or “role:db” we can use later to filter, aggregate, and compare results. We could simply print out metric values in plain text with a known encoding, using some sort of field separator and a newline character to delimit every entry, something we can implement with a simple format. With Protocol buffers instead we need to save a text file (we can name it metric.proto) that contains the following code:
message Metric {
required string name = 1;
required string type = 2;
required float value = 3;
repeated string tags = 4;
}
Messages in the real world can be way more complex but for the scope of the article we will try to keep things simple. You can dive deeper browsing the official docs, namely the language definition and the Python tutorial.
As we mentioned, the .proto file alone is not enough to use the message, we need some code representing the message itself in a programming language we can use in our project. A tool called protoc (standing for Protocol buffers compiler) is provided along with the libraries exactly for this purpose: given a .proto file in input, it can generate code for messages in several different languages.

We only need the Python code, so after installing protoc we would execute the command:
protoc --python_out=. metric.proto
The compiler should generate a Python module named metric_pb2.py that we can import to serialize data:
import metric_pb2
my_metric = metric_pb2.Metric()
my_metric.name = 'sys.cpu'
my_metric.type = 'gauge'
my_metric.value = 99.9
my_metric.tags.extend([‘my_tag’, ‘foo:bar’])
with open('out.bin', 'wb') as f:
f.write(my_metric.SerializeToString())
The code above writes the protobuf stream on a binary file on disk. To read the data back to Python all we need to do is this:
with open('out.bin', 'rb') as f:
read_metric = metric_pb2.Metric()
read_metric.ParseFromString(f.read())
# do something with read_metric
Streaming Multiple Messages
That is neat but what if we want to encode/decode more than one metric from the same binary file, or stream a sequence of metrics over a socket? We need a way to delimit each message during the serialization process, so that processes at the other end of the wire can determine which chunk of data contains a single Protocol buffer message: at that point, the decoding part is trivial as we have ve already seen.
Unfortunately, Protocol Buffers is not self-delimiting and even if this seems like a pretty common use case, it’s not obvious how to chain multiple messages of the same type, one after another, in a binary stream. The documentation suggests prepending the message with its size to ease parsing, but the python implementation does not provide any built in methods for doing this. The Java implementation however offers methods such as parseDelimitedFrom and writeDelimitedTo which make this process much simpler. To avoid reinventing the wheel and for the sake of interoperability, let’s just translate the Java library’s functionality to Python, writing out the size of the message right before the message itself. This is also the way kube-state-metrics API chains multiple messages.
This is quite easy to achieve, except that the Java implementation keeps the size of the message in a Varint value. Varints are a serialization method that stores integers in one or more bytes: the smaller the value, the fewer bytes you need. Even if the concept is quite simple, the implementation in Python is not trivial but stay with me, there is good news coming.
Protobuf messages are not self-delimited but some of the message fields are. The idea is always the same: fields are preceded by a Varint containing their size. That means that somewhere in the Python library there must be some code that reads and writes Varints - that is what the google.protobuf.internal package is for:
from google.protobuf.internal.encoder import _VarintBytes
from google.protobuf.internal.decoder import _DecodeVarint32
This is clearly not intended to be used outside the package itself, but it seemed useful, so I used it anyway. The code to serialize a stream of messages would be like:
with open('out.bin', 'wb') as f:
my_tags = (“my_tag”, “foo:bar”)
for i in range(128):
my_metric = metric_pb2.Metric()
my_metric.name = 'sys.cpu'
my_metric.type = 'gauge'
my_metric.value = round(random(), 2)
my_metric.tags.extend(my_tags)
size = my_metric.ByteSize()
f.write(_VarintBytes(size))
f.write(my_metric.SerializeToString())
To read back the data we need to take into account the delimiter and the size. To keep things simple, just read the entire buffer in memory and process the messages:
with open('out.bin', 'rb') as f:
buf = f.read()
n = 0
while n < len(buf):
msg_len, new_pos = _DecodeVarint32(buf, n)
n = new_pos
msg_buf = buf[n:n+msg_len]
n += msg_len
read_metric = metric_pb2.Metric()
read_metric.ParseFromString(msg_buf)
# do something with read_metric
As you can see, _DecodeVarint32 is so kind to return the new position in the buffer right after reading the Varint value, so we can easily slice and grab the chunk containing the message.
At this point you may wondering why bother with Protocol buffers if we need to introduce a compiler and write Python hacks to do something useful with that. Let’s try to provide an answer, measuring all the things.
Benchmarks anyone?
There are a number of reasons why people need to serialize data: sending messages between two processes in the same machine, sending them across the internet, or both - all of these use cases imply a very different set of requirements. Protocol buffers are clever and efficient but some optimizations and perks provided by the format are more visible when applied to certain data formats, or in certains environments: whether this is the right tool or not, that should be decided on a case by case basis.
Let’s start having a look at the size of the payload produced by encoding a bunch of messages, both with Protocol buffers and using plain text. For simple data like our Metric, binary encoding 100k messages takes 3.7Mb on disk that shrink to about 200 Kb when gzip compressed. If we try to encode the same message with a naive, streamable, newline-delimited text format like sys.cpu,gauge,[my_tag,foo:bar],0.99\n that takes 3.4 Mb on disk and about 180 Kb once zipped to store the same 100k entries.
Results are similar with a real world example: a payload returned by the kube-state-metrics API containing about 60 messages, encoded with Protocol buffers and gzip compression, takes about 6Kb; the same payload encoded with the Prometheus text format and gzip compression has pretty much the same size.
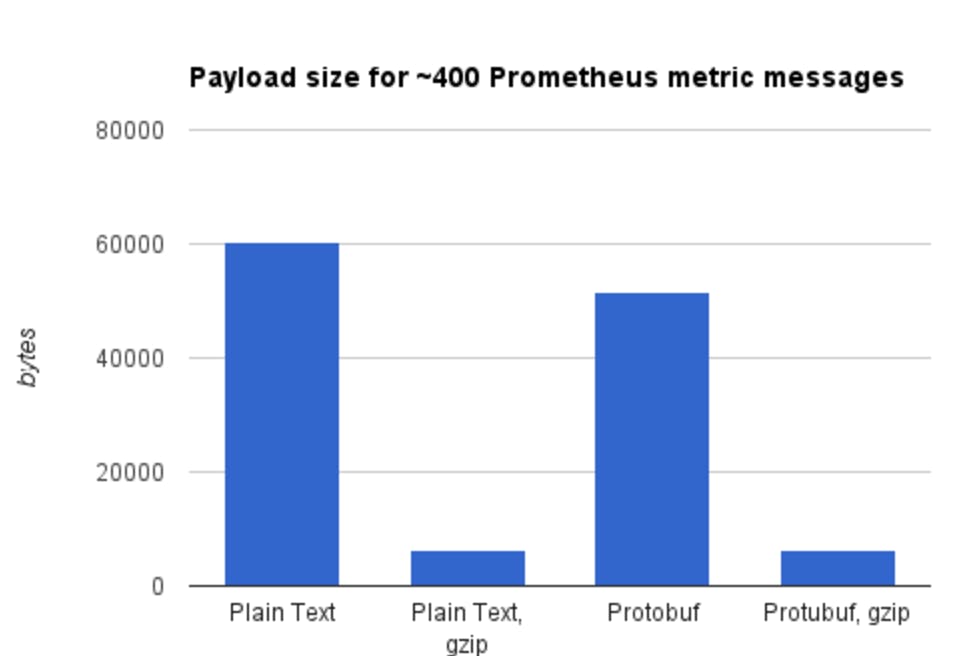
This is somehow expected since strings in Protobuf are utf-8 encoded and our message is mostly text. If your data looks like our Metric message and you can use compression, payload size should not be a criterion to choose Protocol buffers over something else. Or to not choose it.
Speaking of performance, Protocol Buffers should be faster than several other protocols but in practice, it shows how the Python implementation is extremely slow. Because of that, pretty much everyone working with Python and Protobuf uses an optimized version of the library, equipped with a C++ extension; the current version is not pip installable but it’s fairly easy to build and install and it provides a huge boost on the performance side.
These are the results using Python 3.5.1 with protobuf 3.1.0 on a MacBook Pro (13-inch, Early 2015) to encode our Metric type, with and without Protobuf’ cpp extension, compared to the bogus text encoder from a few paragraphs ago.

The encoding phase is where Protobuf spends more time. The cpp encoder is not bad, being able to serialize 10k messages in about 76ms while the pure Python implementation takes almost half a second. For one million messages the pure Python protobuf library takes about 40 seconds so it was removed from the chart.
Decoding results are better, with the cpp implementation able to deserialize 10k messages in less than 3ms; using the oversimplified plain text decoder is like cheating so we don’t plot the values that would be close to zero.

You can find the code used to run the benchmarks here.
Now that we have a rough idea of what we should expect from Protobuf in terms of performance, let’s get back to our use case: should we use it to parse kube-state-metrics? Or should we use the plain text format?
The (short) road to Protobuf
After playing a bit with Protobuf, it wasn’t obvious whether to choose it or not to implement the kubernetes_state check. We had to introduce about 5Mb in binary dependencies to the agent (at this point it should be clear that using the pure Python version of the library is futile and the C++ runtime does not come for free) and the benchmarks seemed to show moderate gains over processing plain text. But trying to look at the entire picture makes things way more clear.
A Python version of the protocol used by the API is publicly available and can be included in our codebase so we can ignore the overhead in terms of setup and tooling caused by the compilation process.
In terms of payload size, being the API server capable to compress HTTP responses, we can choose any of the two formats (Protobuf and plain text) provided by the kube-state-metrics API without changing the overall performance of the check.
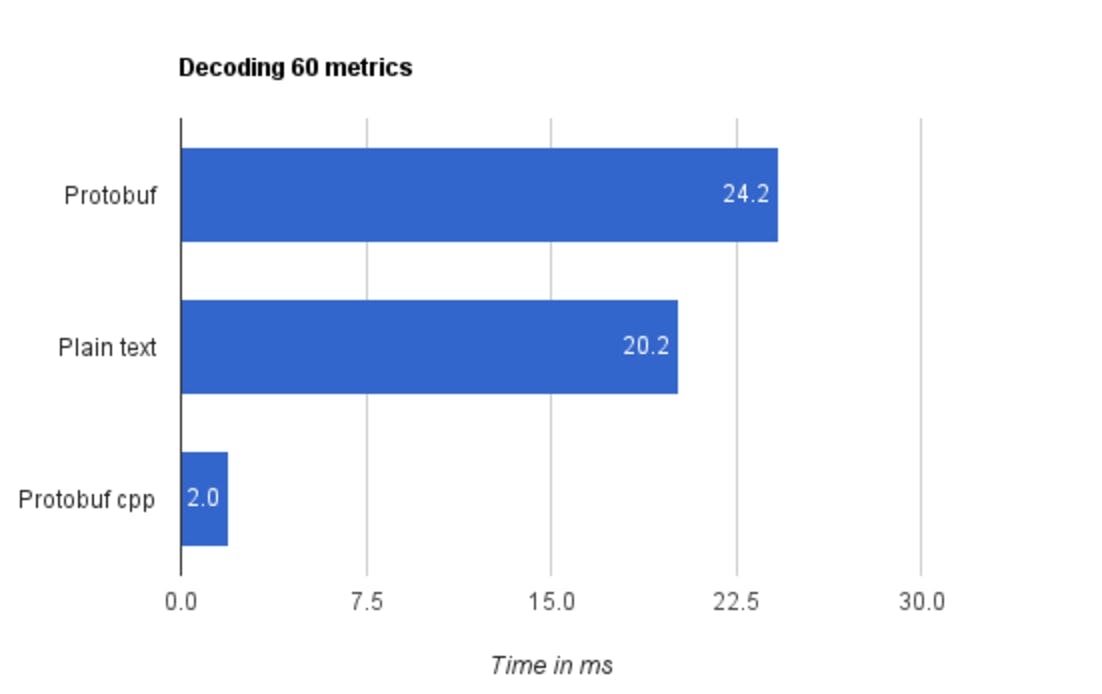
It’s important to note we access data that is already serialized, meaning that encoding performance is someone else’s problem; we only need to focus on what’s the impact of decoding messages on the overall speed of our check. These are the results of processing 60 metrics from the kube-state-metrics API in both plain text and protobuf. The text was processed with the Python parser implemented in the Prometheus client library.
As you can see, parsing complex data in text format is very different from our simple metric message: the prometheus parser has to deal with multiple lines, comments, and nested messages. Putting aside the pure Python version of the library, parsing the binary payload outperforms plain text by one order of magnitude, crunching 60 metrics in about 2 milliseconds - the payload transfer will always be the bottleneck, no matter what.
Even if the Protobuf Python library does not support chained messages out of the box, the code needed to implement this feature is less than 10 lines. The data we get is structured, so once the message is parsed we are sure that a field contains what we expect, meaning less code, less tests, less hacks, less odds of a regression if the API changes.
The new kubernetes_state check was released with the Agent version 5.10, you can check out the code on GitHub.
Want to hack on Kubernetes, Python and other projects like this? Join us at Datadog!
