

If you were online yesterday chances are some of the services you use everyday were partially or completely unavailable around 1pm Eastern Time.

How it impacted Datadog
We were affected too: our web site was down between 1:48pm and 2:14pm. We kept accepting and processing data in the meantime but you could not visualize it.

We know you depend on Datadog to monitor your infrastructure and your applications, so you need us to be here when you’re experiencing issues. We are sorry to have let you down during these 26 minutes that it took us to restore our service.
Out of yesterday’s Amazon EC2 incident we’re planning to make a few changes to our infrastructure to be available when the “rest of the internet” is not.
- In the short term, in the few places where it’s still the case, we will do without shared block storage, which was at the root of this incident.
- Datadog’s infrastructure is already distributed across multiple zones; that has served well in the past to survive a number of similar outages. We have already planned to go even further to increase our availability.
If you want to know more about yesterday’s incident, read on!
What is EBS and how do we use it?
AWS’ Elastic Block Storage (EBS) is, at least on paper, a great way to get storage in the cloud. It is persistent, so unlike ephemeral storage it can survive any instance shutdown, can be copied around very easily and offers a decent (if variable) mix of latency, resilience and throughput.
We use EBS in 2 critical functions:
- it provides storage (as an encrypted RAID 10 array) to a Postgres database that hosts a tiny fraction of our data (user accounts, dashboard definitions, graph definitions).
- it also backs our configuration management server running Chef.
We don’t use EBS to store the bulk of our data, which is metrics and events reported via our agents and our API.
An early warning
Shortly after 12pm Eastern Time, 1 hour before the issue was announced, we noticed that one of the EBS volumes used by that Postgres database was acting up, deviating strongly from our seasonal I/O as shown below. Each peak represents an hourly, I/O-heavy, index maintenance job.
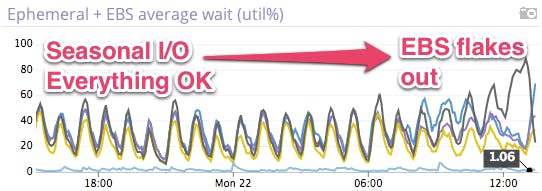
All devices in the RAID 10 array are expected to behave roughly the same, here utilization diverges around 12pm, causing the database to slow down noticeably.
This faulty volume scenario has happened in the past, and one of the advantages of running the database over an EBS-backed, RAID 10 array is the ability to swap out faulty devices while keeping the database up and running. So we proceeded down that well-trodden path.
It’s not just us…
While we were in the middle of the device swap, Datadog (for we eat our own dogfood) let us know that it was going to be a wilder ride than we had imagined.

Then the database became unresponsive. It last reported a load of 47, meaning that the database has stopped answering queries. At 1:48pm, the site had become slow enough that our load balancers decided that it’s down.
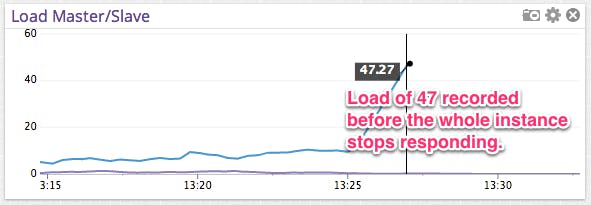
We were also prepared for that scenario. We always maintain a standby database updated nearly in real-time. All we have to do is flip the roles and repoint the whole site to use the standby database.
To do this (and much more) in a few keystrokes we use Chef as our configuration management tool (puppet would work all the same). It takes care of this kind of tedious and error-prone details.
This would have worked nicely if the Chef server, that centralizes configuration were not also running on EBS. It meant that a 2 minute operation turned into a series of manual steps that took about 10 minutes to complete, on top of the time it took for us to realize that using Chef was not going to be an option.
And we’re back…
Once the failover was done and the web application servers restarted, we were back online but we still needed to process data that had accumulated in our intake while the site was down so that it could be visible.

By 3pm we were pretty much caught up. Some data were still trickling in slowly (e.g. Cloudwatch data from AWS) but event streams and graphs were back.
What went well
Standbys to survive a run-on-the-bank We were able to avoid a much longer outage by having a standby database instance, ready to serve, in a different, unaffected zone. It took longer to update the application configuration files than to actually turn the standby database instance into an active one.
In particular we did not have to stand up a new instance with new volumes right when things go wrong. One consistent pattern of shared infrastructure is that systemic issues cause a run-on-the-bank; everyone is frantically trying to spin up new instances, create new volumes to replace the failing ones.
A split intake from exhaust We continued to accept data at the same rate without interruption. There is very little coupling between the intake, where data enters Datadog and the exhaust on the web where data gets consumed.
Limited use of EBS We used to have EBS volumes for most of our storage, including our NoSQL, distributed Cassandra clusters. We moved off of EBS earlier this year to get past performance and reliability issues; Cassandra’s distributed nature allowed us to do it with a lengthy migration process but no downtime.
Multi-zone deployment We distribute nodes across all zones in US East, as recommended by AWS. Whatever extra networking costs we bear because of that, we gladly make up in resiliency.
What went wrong
Manual Postgres failover Making manual configuration changes under pressure to restore service as fast as possible, is stressful, tedious and error-prone. We rely on Chef to provide some level of automation for that, and we had overlooked our relying heavily that automation to work.
Residual use of EBS in a function that is easily overlooked We had all but forgotten that the Chef server runs on an EBS root device. It was the very first instance we created almost 2 years ago (we have abandoned EBS root devices since). Because the Chef server plays a critical but passive role in data processing – its sole job is to keep our configuration consistent, it was easy to overlook and consider as something accessory to the application. It is not.
No useful degraded mode when Postgres is unavailable The web site will tolerate certain failures (e.g. no search) but we have not come up with a way to deliver some minimally usefully view into what’s happening if the database becomes unavailable in the future. It is costly to design and validate a running mode where the application is basically running on fumes. We figured it is better to invest in a swift failover or a more redundant setup.
Lessons learned
Shared storage is hard. EBS is a very addictive piece of technology. It is easy to use, hard to let go. Yet we will look for ways to replace it, with things like LVM to keep functionality at the same level, at the cost of a bit of extra complexity to manage.
Publicly shared infrastructure suffers from occasional run-on-the-banks. When disaster strikes, everyone is going through the same recovery steps: discard failing, create new. Rather you should have enough capacity on hand to carry on because excess capacity is available but no one can get to it. Counter-intuitive but observed again yesterday.
Colophon
All the screenshots (except the first news announcement) come from Datadog. If you want to stay on top of your infrastructure and get real-time (and arguably the prettiest) graphs, give us a try.
