

Amazon Elastic File System (EFS) provides shared, persistent, and elastic storage in the AWS cloud. Like Amazon S3, EFS is a highly available managed service that scales with your storage needs, and it also enables you to mount a file system to an EC2 instance, similar to Amazon Elastic Block Store (EBS). But EFS offers other features—like simultaneous access from multiple clients and AWS Lambda integration—that make it well-suited for use cases such as big data workloads, machine learning, and serving web content.
It’s important to monitor EFS latency, I/O, throughput, and connections in order to ensure the performance of the services and applications that access your file systems. Monitoring EFS can also help you understand costs, which are determined in part by the size and settings of your file systems. In this post, we’ll show you which Amazon EFS metrics are important to monitor, but first, let’s look at how EFS works.
An overview of EFS
EFS is based on the Network File System (NFS) protocol, and it automatically handles data consistency and manages file locking to safely allow for parallel access from multiple clients. You can access EFS from EC2 instances, Lambda functions, Amazon SageMaker notebook instances, and AWS container services (ECS tasks and EKS pods running on EC2 or Fargate). If you’re using Direct Connect, you can also connect to EFS from on-premise hosts. This flexibility makes EFS appropriate for a variety of use cases: for example, you can store static website data in EFS and serve it from a fleet of EC2 instances or ECS tasks, or run a big data application comprised of Lambda functions that read the data, normalize it, and write it back to the file system.
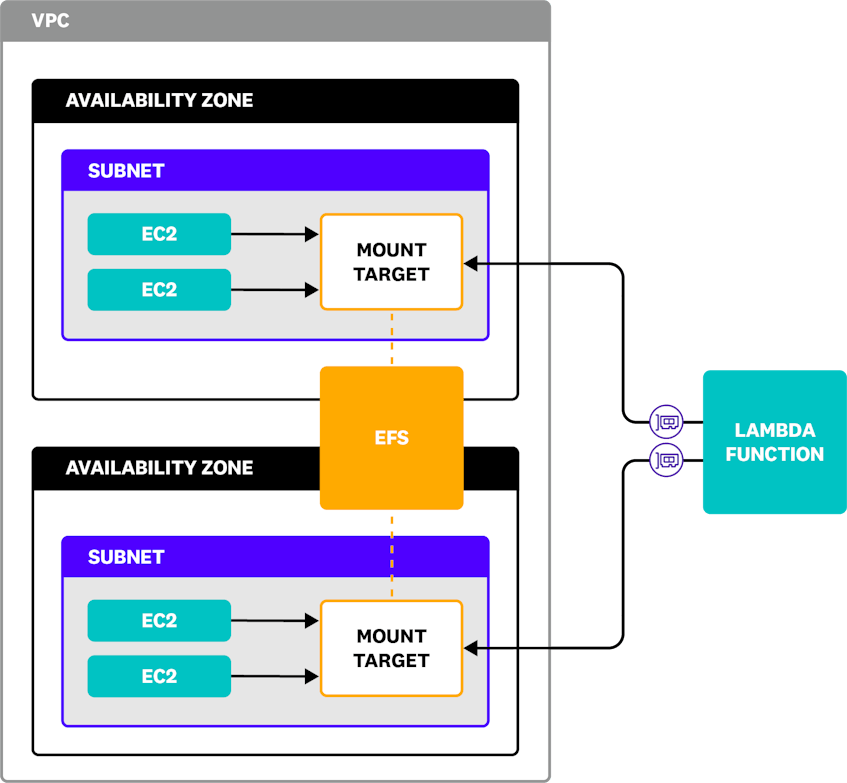
By default, EFS stores copies of your data in multiple availability zones (AZs) and provides access to clients via mount targets. When you create a mount target, AWS creates an Elastic Network Interface (ENI) in a subnet you specify, providing a local endpoint for all clients in that subnet (or clients that can route to it). AWS recommends creating a mount target in each AZ to minimize latency and avoid cross-zone data transfer charges.
The diagram below shows an EFS file system that stores its data across two availability zones. A subnet in each AZ contains a mount target, and EC2 instances within the subnet communicate with the local mount target. The diagram also shows a Lambda function accessing the mount target in each subnet via ENIs that are created automatically when the function is connected to the VPC.
Access points enable you to limit a client’s access to a subset of a file system by specifying a path for the client to use as its root directory. You can create multiple access points to give different applications access to different subdirectories, and you can optionally configure an access point to enforce a user identity so that all clients access the data as a single user. You can also create a file system policy to allow or deny connections to an access point.
A file system must have an access point in order for Lambda functions to connect to it. Other clients—EC2 instances, ECS tasks, EKS pods, and SageMaker notebooks—can mount a file system without using an access point if the file system policy will allow it, but this may give your applications greater access than necessary.
Performance modes
EFS operates in one of two performance modes, which influence the file system’s latency and I/O operations per second (IOPS). General Purpose mode is the default, and it provides the lowest latency for most use cases. Max I/O mode provides higher IOPS, although it adds some latency to each operation. If your workload’s data access is parallelized across a large number of clients or processes—for example, training a machine learning algorithm—Max I/O can improve your application’s data storage and retrieval performance. You can choose either performance mode without affecting your EFS costs, but you can’t change the performance mode of a file system after you’ve created it.
Throughput modes
You can also choose your file system’s throughput mode, which determines the amount of data your clients can read and write in each disk operation. Bursting Throughput is the default mode. It provides a consistent baseline level of throughput that is proportional to your file system’s size, but it also allows you to burst above the baseline for relatively short periods of time. Your baseline throughput scales up as your file system grows, and your ability to burst increases (i.e., you accrue burst credits) as your file system operates below the baseline throughput rate.
If your application consistently requires throughput above the baseline level provided by Bursting Throughput mode, you can choose to use Provisioned Throughput mode instead. This mode allows you to specify a level of throughput that is always available regardless of the size of your file system. Provisioned Throughput mode carries an additional cost, but if the amount of data your application uses is small relative to your throughput needs—for example, a static website with high traffic—it can help you ensure that your file system is not a bottleneck for your application’s performance.
Storage classes
Each file system you create in EFS keeps your data in one or more storage classes, which provide different levels of availability and performance, and which incur different costs. The Standard storage class keeps data in multiple availability zones within the VPC where you created your file system. In contrast, the One Zone class stores data in a single AZ, which reduces both the availability of your data and the costs associated with storing it. These tradeoffs make the One Zone class most appropriate for storing temporary data that can be easily recreated, such as staging or build environments.
You can configure EFS to automatically move data from either of these classes to an infrequent access (IA) class—Standard-Infrequent Access or One Zone-Infrequent Access—if it is not accessed within a time frame you specify. It’s less expensive to use IA classes, so storing unused data there can help you manage your EFS costs. But you must pay a per-access charge any time you retrieve data from IA, and the latency is higher, so it may or may not be your preferred storage option, depending on your data access patterns.
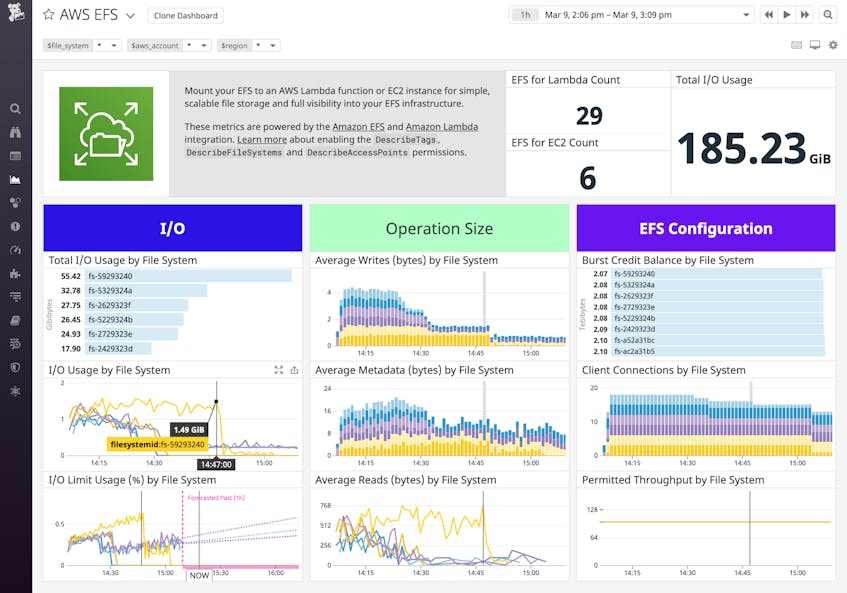
Key Amazon EFS metrics to monitor
So far in this post, we’ve shown you how EFS provides shared storage to a variety of clients, and we’ve looked at the configuration options that let you balance availability, performance, and cost. In this section, we’ll walk you through the key metrics you should monitor to fully understand the health and performance of your file system. We’ll show you metrics from the following categories:
Terminology in this section comes from our Monitoring 101 series. Most of the metrics in this section are available from Amazon CloudWatch, but some come from Linux utilities. We’ll explore these and some other tools you can use to collect Amazon EFS metrics in Part 2 of this series.
Storage metrics
EFS is elastic and will scale to provide more storage as your needs increase. But the size of your file system affects your EFS costs, so it’s important to track how much data you’re storing—overall and in each storage class—in order to understand and anticipate your monthly charges.
| Name | Description | Metric type | Availability |
|---|---|---|---|
| File size | Storage space used by a single file or directory | Resource: Utilization | Linux utilities |
| File system size | Aggregate storage space used by a file system | Resource: Utilization | CloudWatch, Linux utilities |
Metric to watch: File size
Monitoring the size of individual files or directories can give you granular insight into your EFS usage. You should track the growth of files that contribute significantly to your overall usage—for example, fast-growing log files—to understand and accurately predict your application’s storage needs.
Metric to watch: File system size
A typical disk utilization metric doesn’t apply in the case of EFS, which has no fixed upper limit on the amount of data you can store. But monitoring your file system size over time can show you how your application is storing and accessing data in three dimensions: the Standard storage classes, the IA storage classes, and in total. If you’re using lifecycle management, this metric will provide insight into how data shifts from Standard to IA storage classes. Seeing the rate of that shift can illustrate patterns in how your application accesses existing data.
Latency metrics
Your file system’s performance mode and storage class can influence its latency, so you’ll want to keep an eye on your latency metrics to ensure that you’ve chosen the most optimal configuration. Because EFS is based on NFS, you can use the nfsiostat tool on an EC2 instance, ECS task (via execute-command), or EKS pod (via kubectl) to see the round-trip time required for that client to access data on any attached EFS file system. If you’re using EFS with Lambda, Amazon CodeGuru Profiler can help you visualize the time your application spends waiting for disk operations to complete.
| Name | Description | Metric type | Availability |
|---|---|---|---|
| Read round-trip time | The time between when the client sends a request to read data and when it receives the reply from EFS | Work: Performance | Linux utilities |
| Write round-trip time | The time between when the client sends a request to write data and when it receives the reply from EFS | Work: Performance | Linux utilities |
Metric to watch: Read/write round-trip time
You can monitor EFS’s round-trip time (RTT) to understand how storage access contributes to your application’s overall latency. You may be able to reduce average RTT across all of your clients by ensuring that they are connecting to mount targets in their local availability zone and by minimizing any competing network traffic within the VPC. If only some clients have a slow RTT, you should optimize the network performance of the relevant nodes—for example, by scaling up to a larger instance size—to prevent sporadic latency in your application. You should also ensure that your file system is using the optimal performance mode and storage class, as Infrequent Access storage classes and Max I/O performance mode generally have higher latencies.
I/O metrics
Your I/O rate will increase as more clients access a shared file system, and your application’s access to storage could get throttled if your clients collectively require more IOPS than your file system can provide. It’s therefore important for you to monitor I/O utilization, especially if you’ve parallelized storage access across a large number of clients or processes.
You can use CloudWatch to monitor the I/O utilization of file systems that use General Purpose mode, but this metric isn’t available if you’re using Max I/O mode.
| Name | Description | Metric type | Availability |
|---|---|---|---|
| I/O utilization | The percentage of the file system’s available IOPS that is in use | Resource: Utilization | Availability: CloudWatch |
Metric to alert on: I/O utilization
If your file system reaches its IOPS limit, your application could slow down as it waits to read and write data. You should create an alert that triggers when your file system approaches a specified percentage of its IOPS limit to give your team time to refactor or re-architect your application (e.g., to introduce a caching layer) before its performance degrades. Alternatively, you should consider moving to a new file system configured to use Max I/O mode.
Throughput metrics
A file system’s throughput limit is determined by its performance mode, size, and level of activity. In Bursting Mode, the throughput limit changes based on the file system’s size and burst credit balance. In Provisioned Throughput mode, you specify the limit in the file system’s configuration. Monitoring the metrics described in this section can help you see whether insufficient throughput presents a risk to your application’s performance—or whether you’ve provisioned more throughput than your application requires.
| Name | Description | Metric type | Availability |
|---|---|---|---|
| Burst credit balance | The number of bytes of bursting throughput the file system has available | Resource: Utilization | CloudWatch |
| Permitted throughput | The amount of throughput available to the file system, in bytes per second | Work: Throughput | CloudWatch |
| Metered I/O bytes | The number of bytes used in reads, writes, and metadata operations on the file system | Resource: Utilization | CloudWatch |
Metric to alert on: Burst credit balance
In Bursting Throughput mode, your file system can temporarily attain throughput rates above the baseline. The more burst credits you have, the longer you can sustain a higher throughput.
You accrue burst credits when you’re operating below the baseline throughput, and you spend burst credits when you’re operating above the baseline (i.e., bursting). If your burst credit balance reaches zero, your application’s access to your file system will be limited to the baseline throughput, which could cause user-facing latency.
Monitor burst credit balance to ensure that you have sufficient credits to support the data access patterns of your workloads. If you find that you are consistently running out of burst credits, you should consider switching to Provisioned Throughput mode, which will enable you to define the amount of throughput you require.
Metric to watch: Permitted throughput
Permitted throughput illustrates the throughput available to you at any moment, and it is calculated differently depending on which performance mode you’re using. In Bursting Throughput mode, this metric changes along with burst credit balance and file system size. If no burst credits are available, permitted throughput will be equal to the file system’s baseline throughput. In Provisioned Throughput mode, the value of this metric will equal the larger of your provisioned amount of throughput or the baseline throughput. If its value is lower than you expected, it could help explain any errors or latency in your application.
Metric to alert on: MeteredIOBytes
CloudWatch aggregates the data used on read, write, and metadata operations into a MeteredIOBytes metric. If the value of this metric reaches your file system’s permitted throughput, your application’s access will be limited, which could cause user-facing latency. Create an alert on MeteredIOBytes as a percentage of permitted throughput so you can provision enough throughput to meet your application’s requirements and prevent application latency.
Connection metrics
EFS supports thousands of connections per file system, but even if you’re not at risk of surpassing that limit, it can be helpful to monitor each file system’s connection count to watch for unexpected changes. Fewer connections than usual could indicate a problem with an application or the network. And if you see more connections than you expect, you could have a security issue or an auto-scaling anomaly that you need to investigate.
| Name | Description | Metric type | Availability |
|---|---|---|---|
| Client connections | A count of all the clients connected to the file system | Resource: Utilization | CloudWatch |
Metric to alert on: Client connections
Your file system’s I/O is a limited resource—especially if you’re using General Purpose mode—and an upward trend in your connection count could be one cause of an increase in IOPS. If your application typically has a steady number of clients accessing your file system, you should create an alert to notify you if the client connections metric rises above normal so you can evaluate whether you’re at risk of running out of IOPS.
Monitor EFS performance for healthy storage
In this post, we’ve shown you how EFS works and which EFS metrics you can track to understand your file system’s performance. It’s important to monitor your file system’s latency, I/O, and throughput, as well as your usage, to ensure the health of your application and troubleshoot any bottlenecks that arise. Coming up in Part 2, we’ll show you some of the tools you can use to gather logs and metrics from EFS.
Acknowledgments
We’d like to thank Ray Zaman at AWS for their technical review of this post.
Source Markdown for this post is available on GitHub. Questions, corrections, additions, etc.? Please let us know.
