Optimizing Distributed Tracing: Best practices for remaining within budget and capturing critical traces
5月 19, 2025
Intro
As we saw in the first article of this series, in the modern software landscape, tracing is key to understanding how your distributed services interact. However, as your teams scale and the volume of your traces grows, it’s easy to end up ingesting more data than planned—leading to data overload and ballooning bills.
In this post, we’ll explore how you can control trace ingestion volume, ensuring that critical traces still make it into your dashboards while remaining within your budget. We’ll also dig into two powerful Datadog features that will help you throughout your journey, namely resource-based sampling and adaptive sampling. We’ll look at what these features are, how they complement each other, and best practices for using them effectively.
The challenge of balancing cost and visibility
Observability is most valuable when it gives you comprehensive insights into application behavior. However, ingesting every single trace at a 100% sampling rate can be prohibitively expensive— especially at scale—and can overwhelm your SRE/engineer teams sifting through the data.
As a result, teams often face a difficult trade-off:
Lower sampling rates to stay within budget
By reducing sampling, you may significantly lower costs but risk missing critical traces that illuminate rare edge cases or intermittent failures. In the event of an incident, having limited or incomplete data can hamper root cause analysis and lengthen recovery times.Maintain high sampling rates for important services and endpoints
This approach ensures that you’re capturing in-depth data where you need it most. However, it can quickly inflate both your budget and data volume. Teams may find themselves drowning in unfiltered traces, making it harder to parse out meaningful signals while also grappling with unpredictable costs.
Prioritizing what matters most
That is why it’s important to define clear guidelines for your organization’s observability efforts. For example, if you run an e-commerce platform, your checkout flow might be a critical path tied directly to revenue and user experience. This critical path must be traced at a higher sampling rate to capture any anomalies or latency issues quickly, as latency or errors in this area can immediately affect your bottom line. Conversely, routine background tasks like health checks or scheduled sync processes might not need the same level of scrutiny. By dialing down the sampling rate for these less critical endpoints, you can balance visibility with cost.
The following best practices will help you focus on what truly matters—ensuring critical endpoints get the attention they deserve while less essential ones don’t monopolize your data volume or budget.
Best Practices
Identify high-value endpoints: Start by listing the most critical endpoints; those directly tied to revenue, user experience, or compliance. Typically, these are:
- Revenue drivers (e.g., checkout flow, payment APIs)
- Customer-facing features (e.g., sign-up and login endpoints)
- Compliance-sensitive operations (e.g., data handling and privacy-related workflows)
These endpoints should have the highest sampling rates so you can quickly spot anomalies and latency issues.
Establish a baseline sampling rate: Start with a default sampling rate across all endpoints. From there, adjust each endpoint’s sampling rate based on its value to your business. This approach helps you apply consistent coverage while making sure mission-critical endpoints receive extra attention.
Monitor traffic volume per resource: Use Datadog’s Ingestion Control page to gain visibility into how much traffic each endpoint generates. If a less-critical endpoint generates an outsized portion of your total traces, it may be wise to decrease its sampling rate. This ensures your monthly ingestion volume (and associated costs) remain in check.
Adjust in real time: Monitor your usage and budget in the Datadog Ingestion Control page. If you see unexpected trace volume spikes—for instance, a sudden surge in requests to a non-critical endpoint—you can lower its sampling rate immediately in the UI; no code changes or restarts of service are required.
Integrate with your observability strategy: Traces are just one piece of the observability puzzle. Ensure your logs, metrics, dashboards, and alerts are well integrated so that you get a holistic view into your system. Also, when an incident occurs, make sure you have enough coverage from your most critical services. Consider temporarily loosening sampling parameters if deeper insight is required during a critical event.
Datadog’s resource-based sampling allows you to configure sampling rates at the resource (endpoint) level. This is especially useful if certain endpoints or classes of requests are more important for your business.
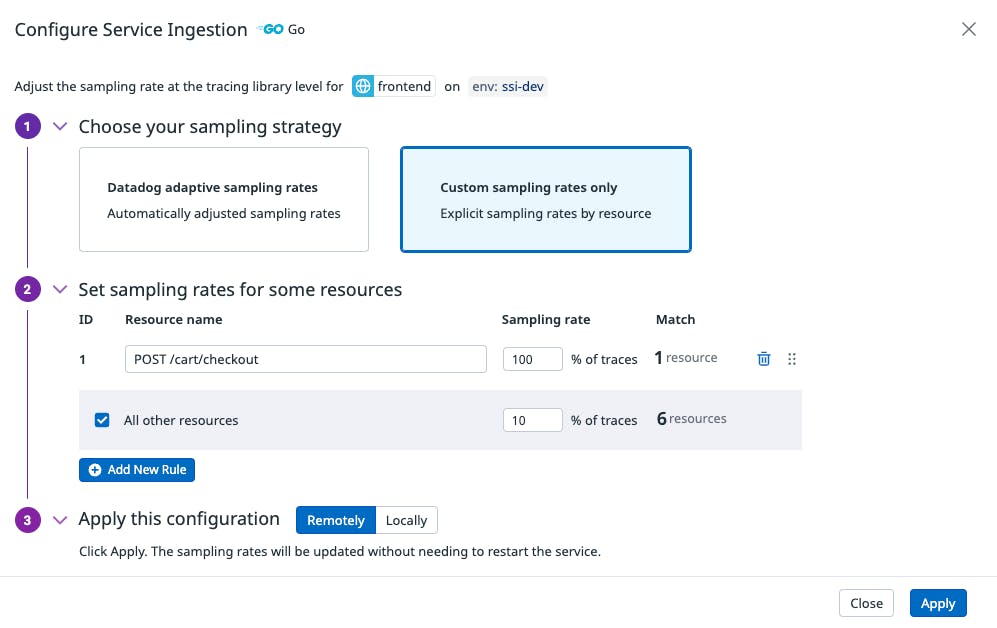
A practical example on how to configure resource-based sampling
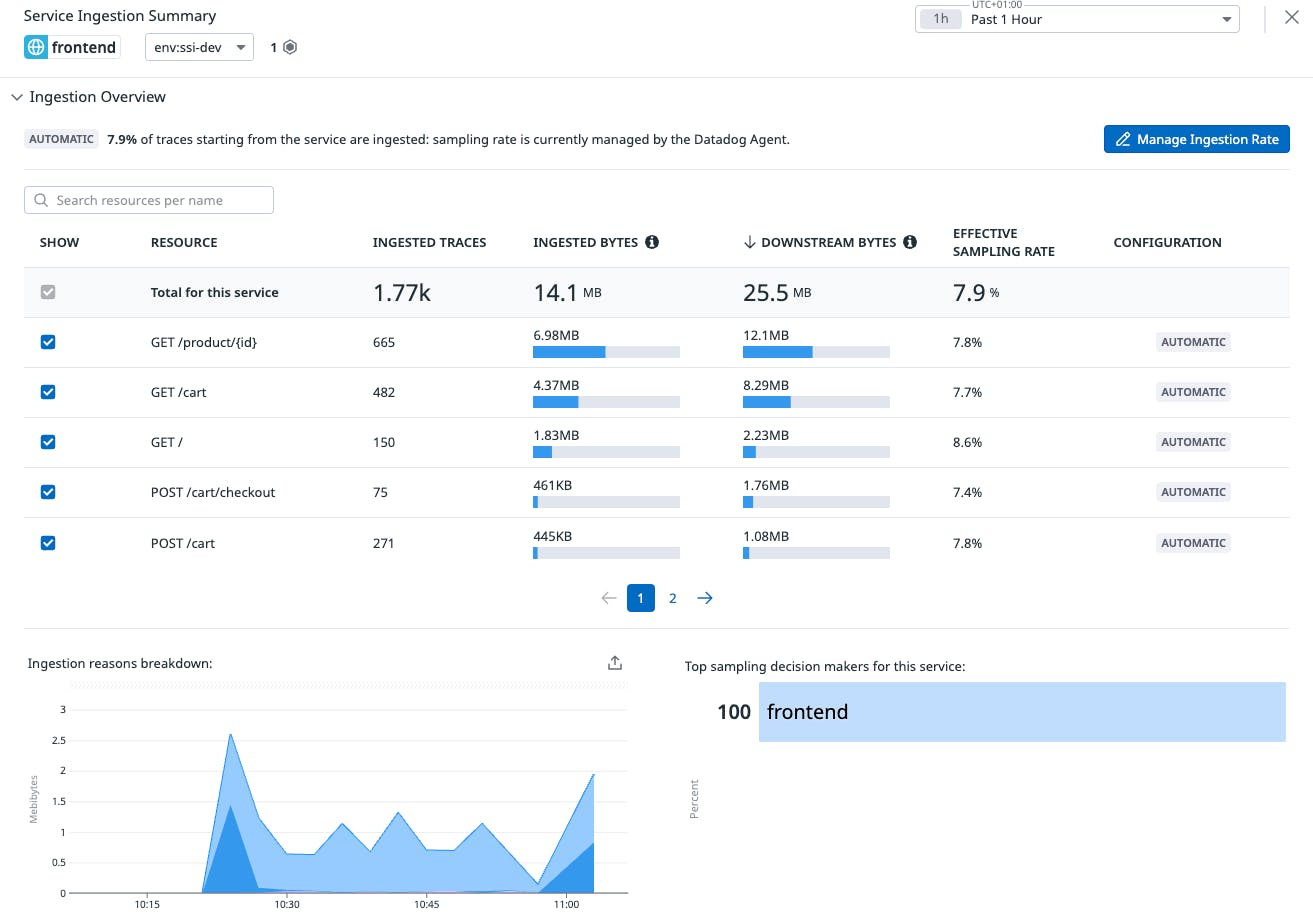
In our above application, the frontend service invokes multiple downstream services. We have multiple resources within our service and we want to treat them differently when it comes to sampling.
By using resource-based sampling, we have full control on how we want to sample each individual resource. In fact, we have configured to ingest 100% of POST /cart/checkout—our top critical resource—and 10% for the remaining resources .
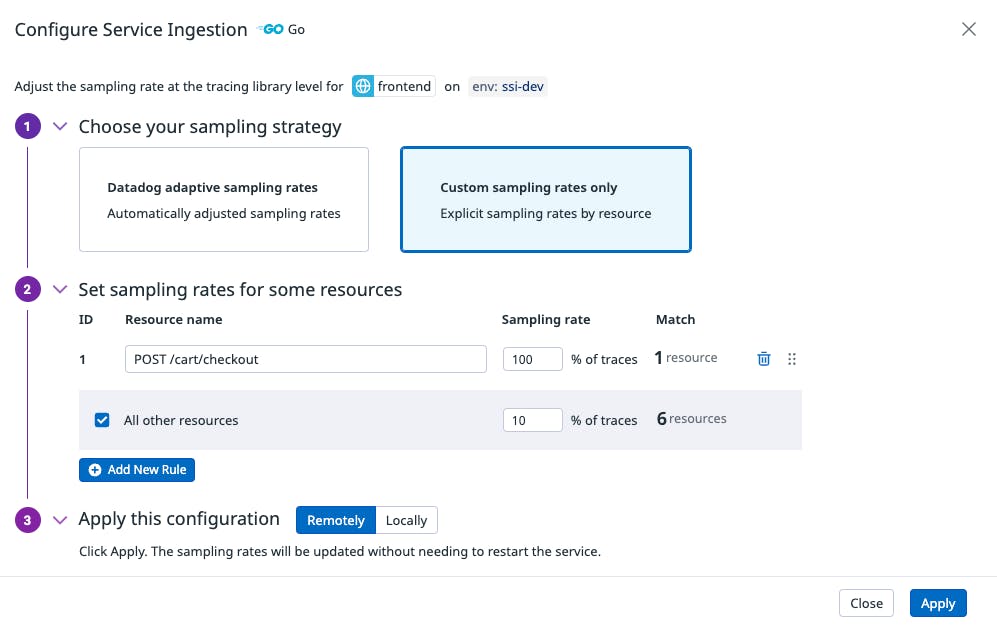
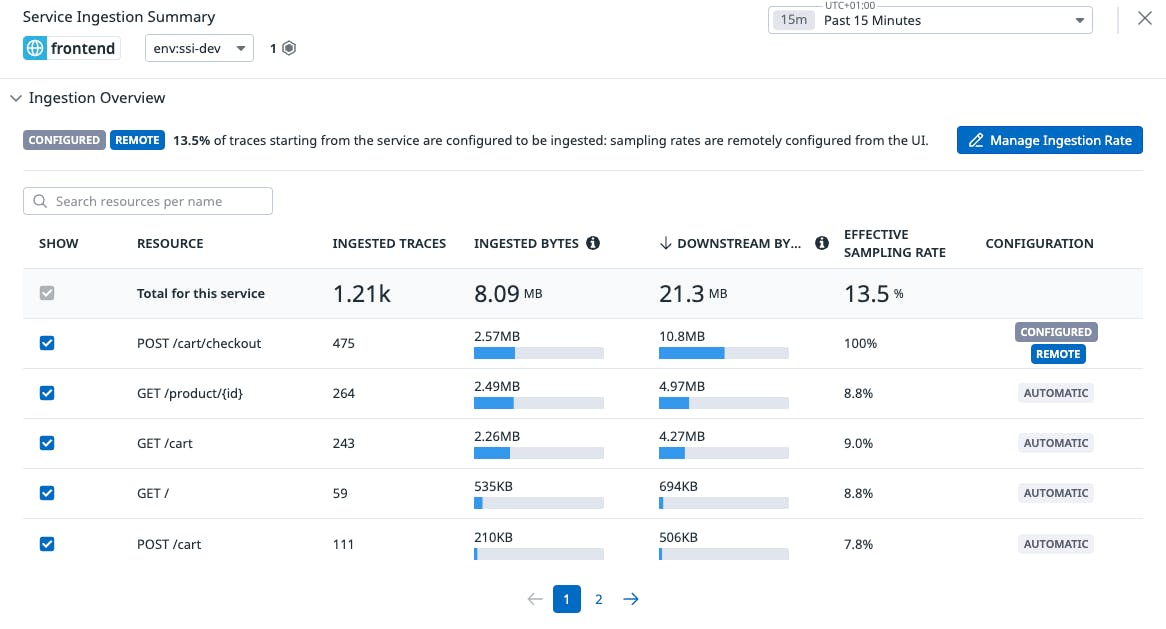
If we apply this configuration, after a few minutes, we could check the status under the Ingestion Control page.

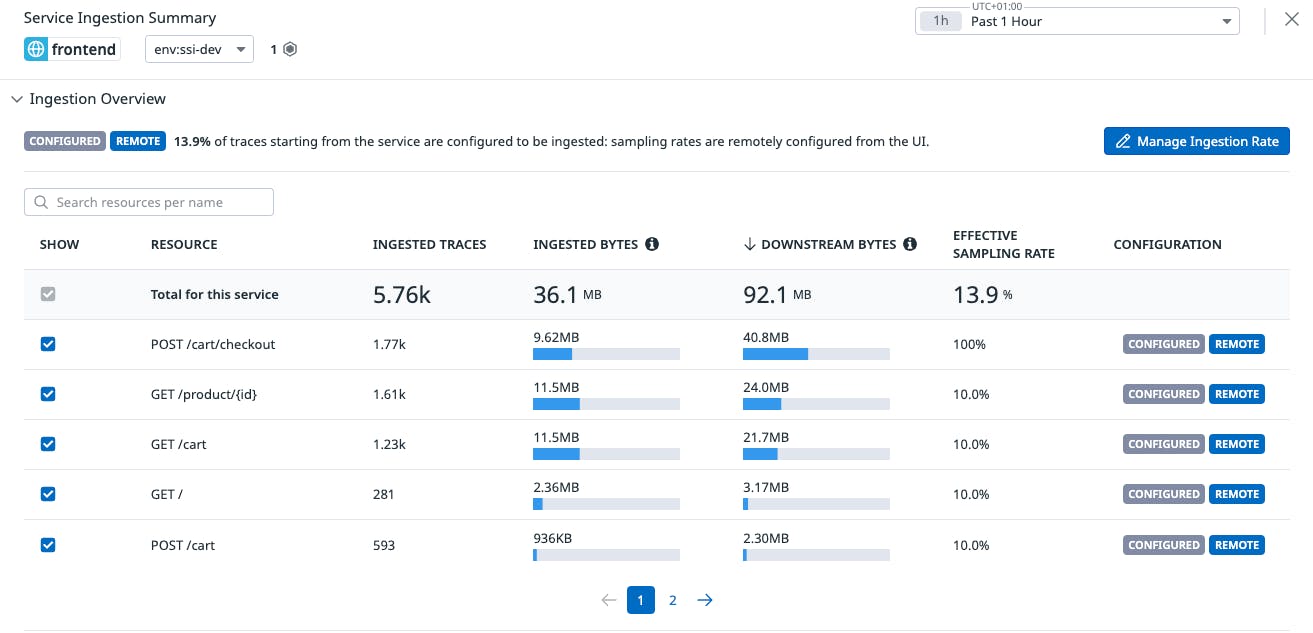
As we can see, our remote sampling rules have been applied.
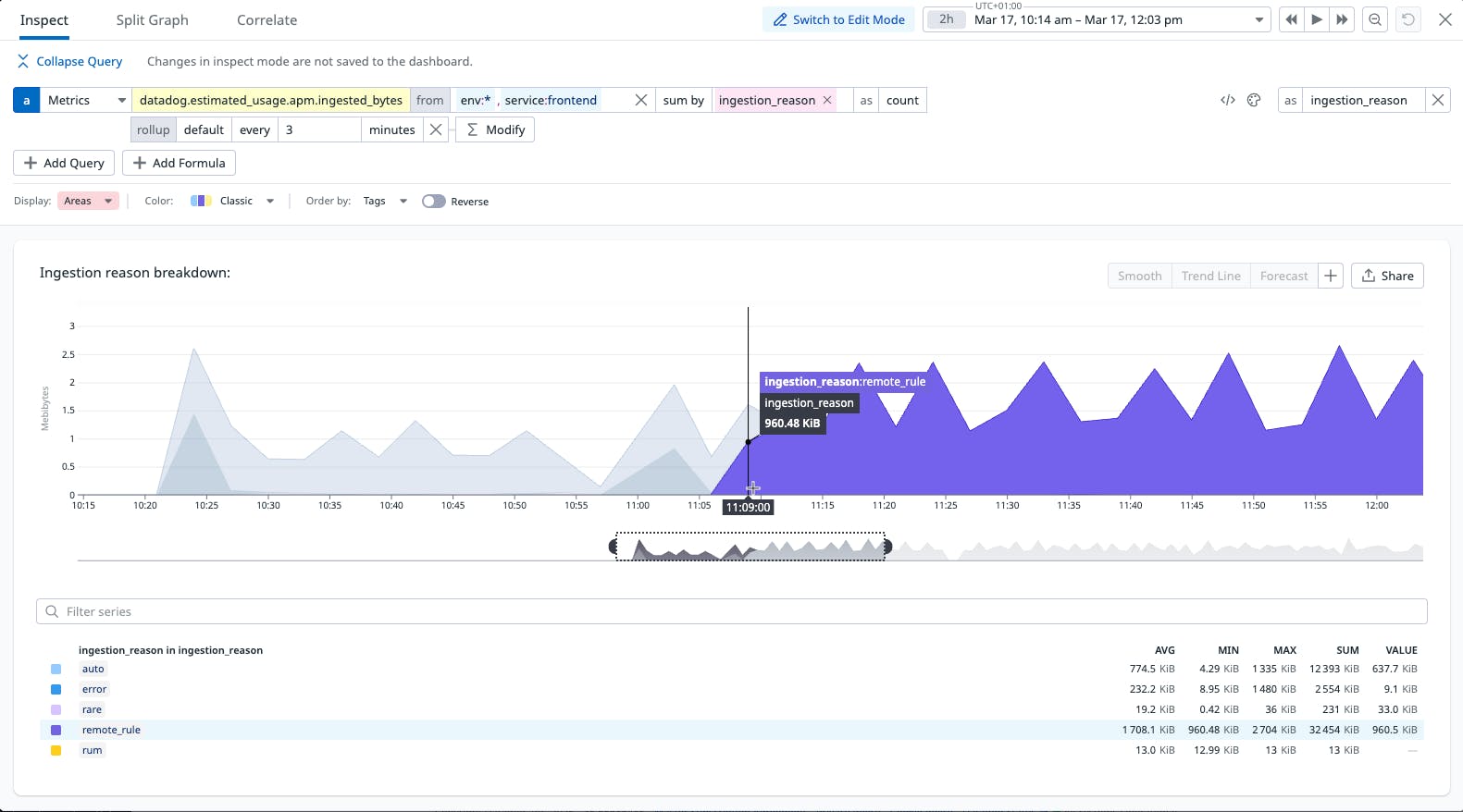
As traffic goes through our application, we should be able to see the variation of ingestion on POST /cart/checkout and all the remaining resources. As you can see, POST /cart/checkout has an effective sampling rate of 100% and all the remaining resources sample at 10% rate.
And, if you do not want to configure sampling rate for the remaining resources, you could even use the default configuration or leave them automatically managed by the Datadog Agent.
Staying on track with a target volume
As your e-commerce platform gains traction and expands globally to serve customers across multiple countries, maintaining an optimal observability strategy becomes even more critical.
Let’s say your recent marketing campaign drives a surge in traffic to your adservice, making it essential to closely monitor its performance. Ensuring a higher sampling rate for critical paths such as adservice endpoints helps detect anomalies, latency spikes, or failures that could impact end-user experience and revenues. Meanwhile, less critical background tasks can be deprioritized, allowing you to balance system visibility with operational efficiency.
Therefore, you might configure a high sampling rate—or even 100%—for these critical transaction traces. However, a higher sampling rate also translates directly into greater trace ingestion volume. If your monthly volume is tightly budgeted, consistently sampling at high rates may exceed your target, resulting in unexpected costs or the need to abruptly reduce coverage elsewhere.
With Datadog’s adaptive sampling, you gain a dynamic balance between budget and visibility. You allocate more coverage to critical paths—where transaction errors or latency can have immediate financial and regulatory repercussions—and automatically scale back sampling on processes where full granularity is less essential. This strategy ensures robust oversight where it’s needed most, without overburdening your budget or data pipelines on routine tasks.
This trade-off becomes even more pronounced when traffic surges. With a high sampling rate in place, sudden usage spikes can quickly consume your budget. Consequently, you may need to impose stricter sampling on lower-priority services or even temporarily lower sampling across the board to maintain cost predictability.
Adaptive sampling helps you meet a specified monthly ingestion volume target for your applications. By automatically adjusting which traces are ingested (and which are dropped), adaptive sampling keeps your usage on track—without requiring continuous fine-tuning from your team.
A practical example on how to configure adaptive sampling
For this example we are going to use the same sample application seen before. This time, instead of configuring sampling per resource, we are going to rely on Datadog’s adaptive sampling.
First, we set up our monthly ingestion budget. This is our target monthly volume for trace ingestion that we want all our selected services to match at the end of the month, while keeping visibility over service endpoints. At this point, adaptive sampling will then ensure visibility for low-traffic services and endpoints by capturing at least one trace for each combination of service, resource, and environment every five minutes.
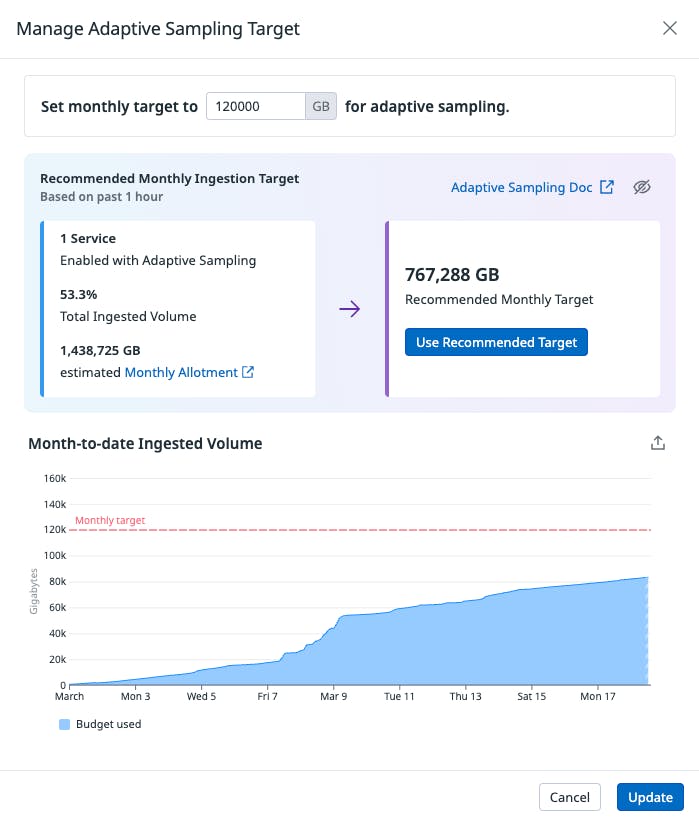
Let us define our adaptive sampling target. For testing purposes, we are going to set 120TB.
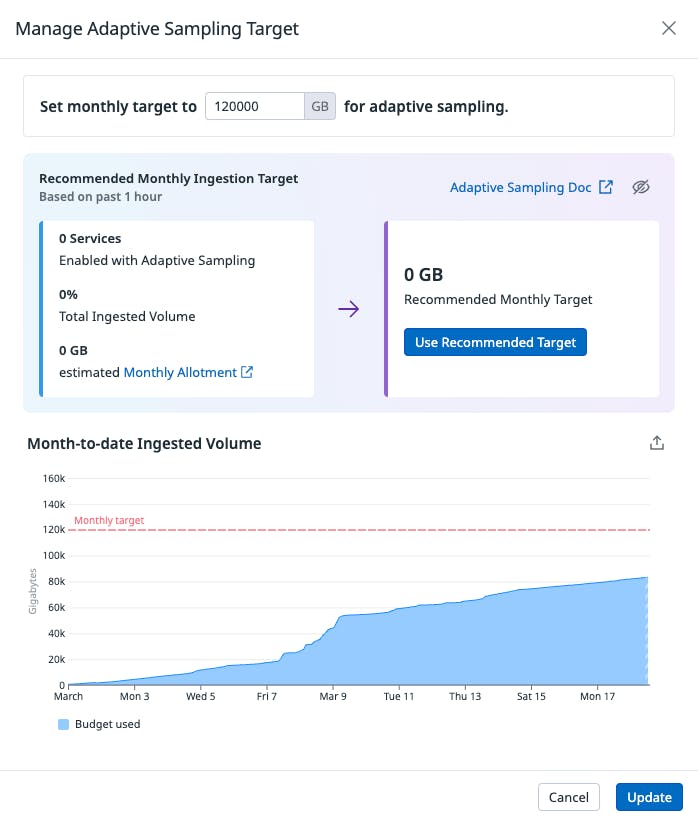
The allocated budget only applies to services enrolled in adaptive sampling. It does not include any additional volume generated by services utilizing local sampling rules or other sampling mechanisms configured within the Agent or tracing library.
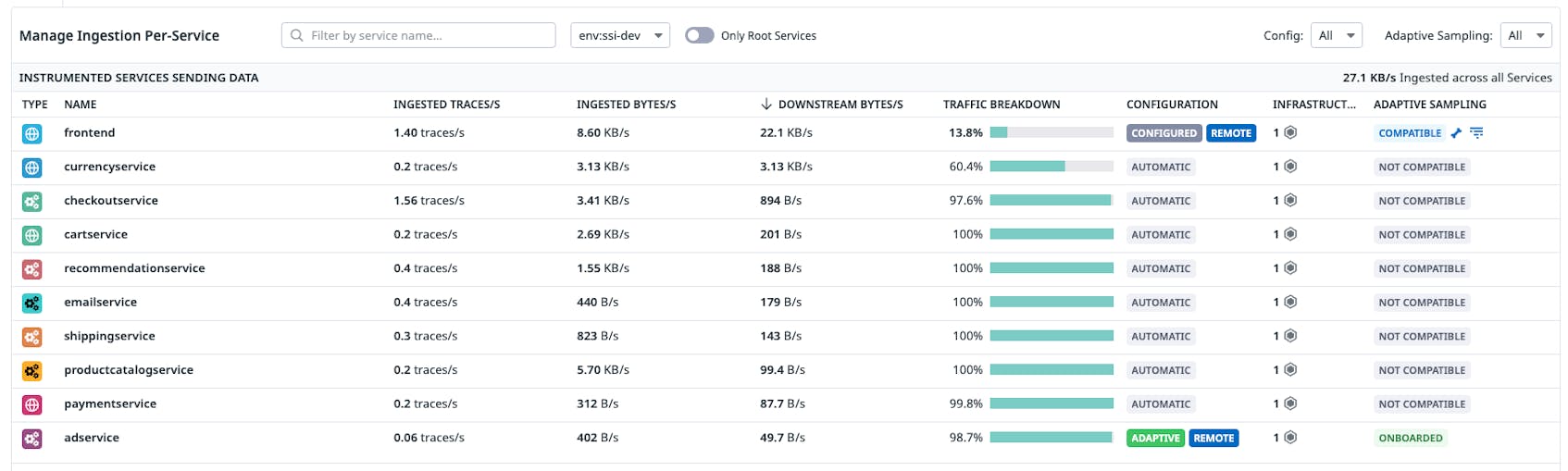
Then, we configure adservice to use adaptive sampling.
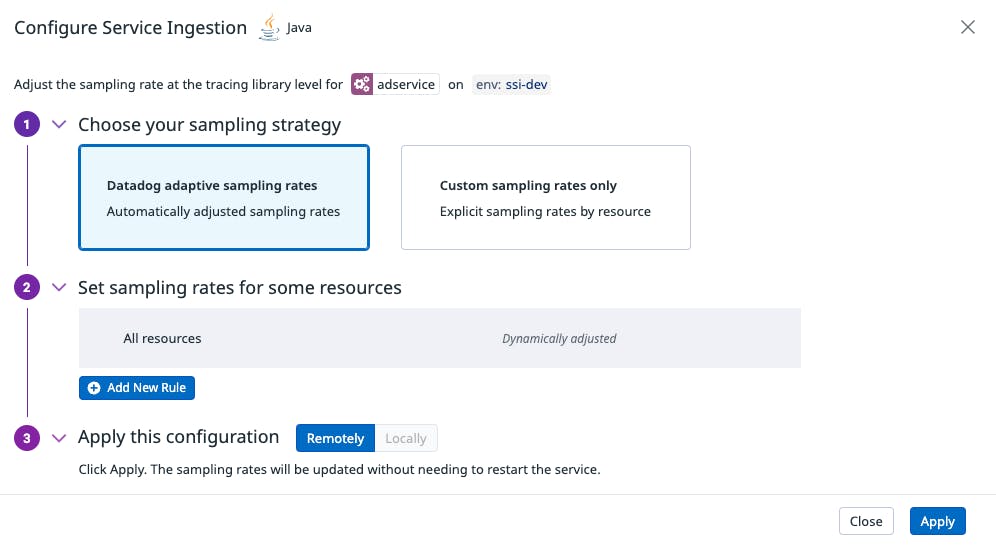
We click on Manage Ingestion Rate button and then choose adaptive sampling as our strategy:
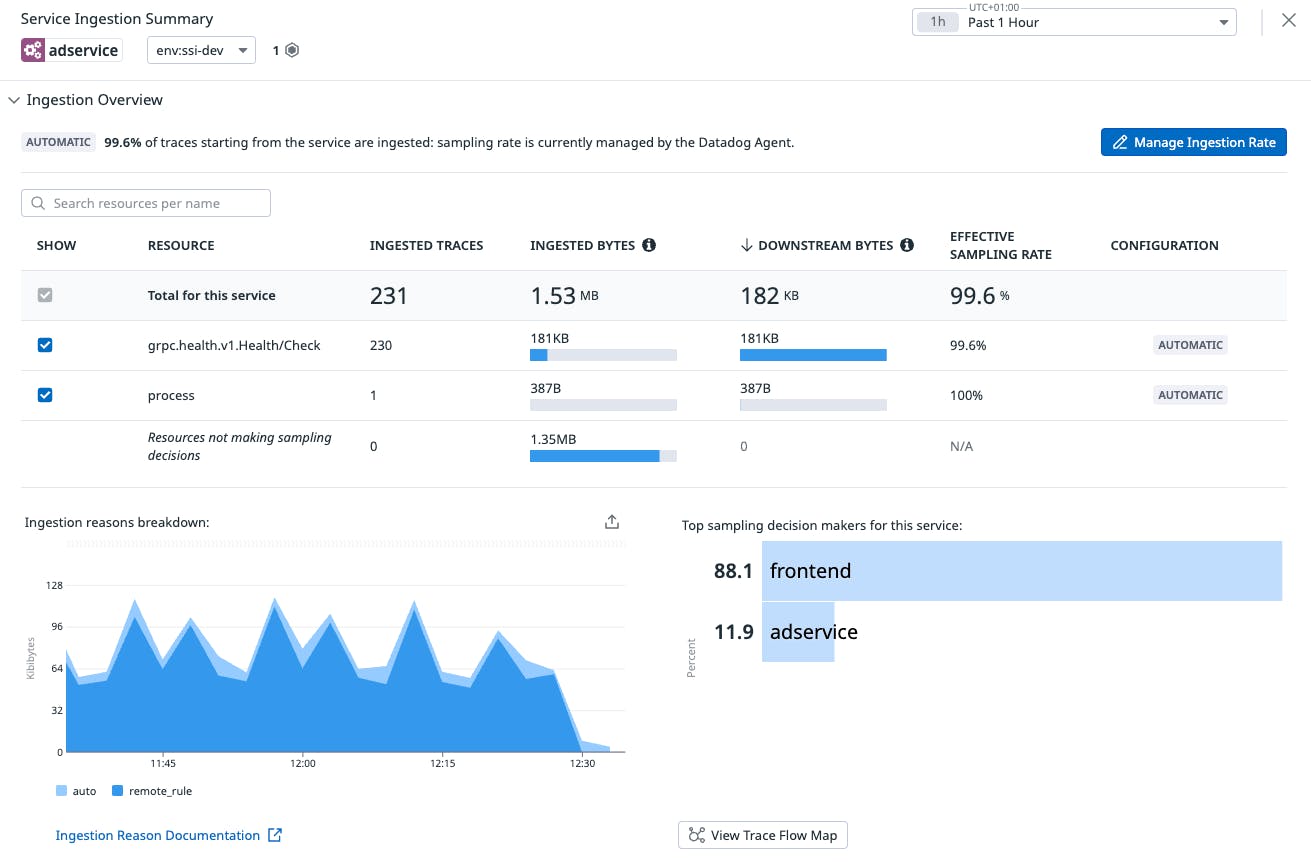
As we can see, our adservice has been onboarded with adaptive sampling
After some time, we can see Datadog’s adaptive sampling being applied to our adservice.

Lastly, we can assess month-to-date ingested volume of our selected service in respect to our monthly target.
To summarize, Datadog’s resource-based sampling and adaptive sampling are powerful tools that allow you to capture the most critical traces without blowing your budget. Resource-based sampling allows you to strategically define which endpoints are most critical, while adaptive sampling lets Datadog adapt sampling to real-time traffic changes. This allows you to maintain deep observability while still managing overall costs.
With these best practices in mind, you will be ready to fine-tune your traces and make informed decisions to keep your systems running optimally—all while gaining the visibility you need to deliver a great user experience.
What to do next
We have just scratched the surface of this topic, driving through some of the capabilities that Datadog offers to help companies successfully migrate to the cloud, facilitate their DevOps journey, and consolidate monitoring solutions.
Authors
Stefano Mazzone, Sr. Product Solutions Architect