
De plus en plus, les entreprises multiplient les modèles
En analysant les données de télémétrie des agents LLM de nos clients, nous avons constaté que les entreprises font de plus en plus appel à plusieurs prestataires. 63 % font confiance à OpenAI, mais les modèles Gemini de Google et Claude d’Anthropic ont respectivement gagné 20 et 23 points en un an.
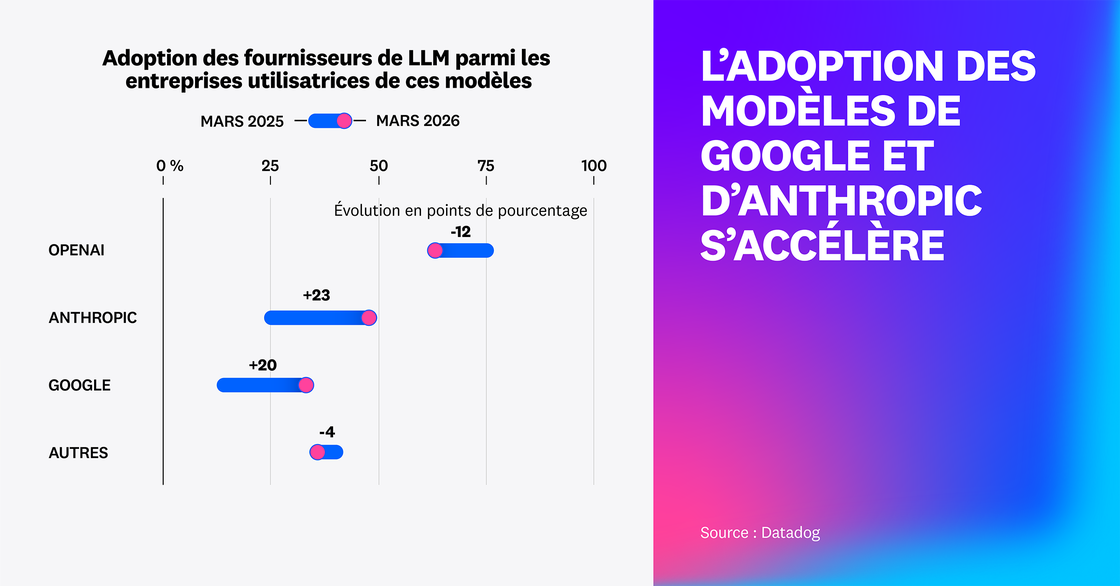
Il est important de noter que, si la part d’OpenAI a diminué sur un an, cela ne signifie pas que les modèles de l’entreprise sont moins utilisés dans l’absolu. C’est même l’inverse : le nombre de clients Datadog utilisant OpenAI a plus que doublé, même si d’autres fournisseurs ont connu une croissance plus rapide.
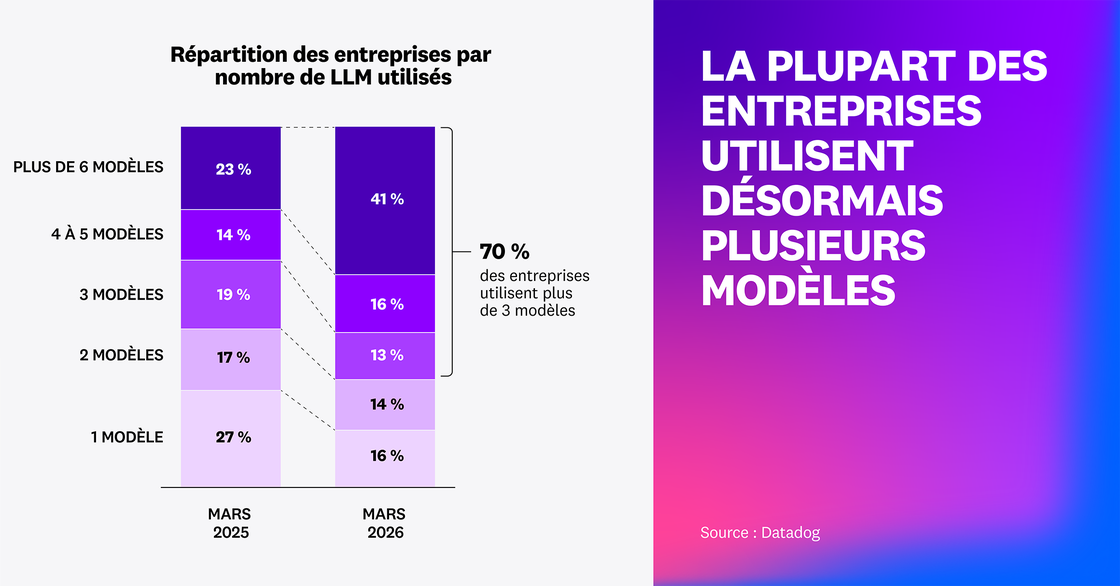
La diversification des modèles s’observe aussi au sein des entreprises. Elles sont plus de 70 % à utiliser au moins trois modèles, et le nombre d’entreprises qui s’appuient sur plus de six modèles a presque doublé. Plutôt que de se fier à un modèle unique par défaut, elles créent des portefeuilles de modèles afin d’utiliser le plus adapté à chaque charge de travail, selon les exigences de latence, de coût, de risque opérationnel et de tâche.
Cette multiplication des plateformes pose toutefois de nombreuses difficultés en matière d’ingénierie de plateforme, de DevX et de conformité. Avec des appels d’API dispersés entre différents fournisseurs de modèles et services, les équipes ont du mal à itérer rapidement. L’application uniforme des politiques de sécurité et de conformité est aussi plus complexe. Enfin, la gestion fluide des défaillances lorsque les fournisseurs limitent les requêtes ou voient leurs performances et leur efficacité se dégrader devient moins évidente. Pour s’en sortir, les équipes sont de plus en plus contraintes de gérer les requêtes via un mécanisme de routage modulaire, comme un service de passerelle ou une passerelle managée de type OpenRouter, en évitant les appels directs aux API des fournisseurs de modèles depuis les différents composants de leurs environnements.
Les équipes qui prennent aujourd’hui une longueur d’avance considèrent l’inférence comme un pipeline et évaluent, comparent et modifient régulièrement le modèle adapté à chaque étape, au gré de la baisse des coûts et de l’évolution des performances. Elles choisissent par exemple des modèles légers pour l’extraction et le tagging, et des modèles avancés pour réaliser des synthèses. En exécutant une passerelle de modèles et en maintenant un framework d’évaluation opérationnalisé, elles peuvent sélectionner le modèle idéal pour chaque cas d’usage en fonction de la qualité des résultats, des coûts et de la latence attendus. Les évaluations en ligne jouent ici un rôle clé, en permettant de comprendre la qualité des résultats, la sécurité et les performances des modèles et des agents en production, et donc de faire le bon choix.
« La plupart des équipes utilisent désormais plusieurs modèles en production. Environ 70 % en exploitent au moins trois, et ce chiffre ne cesse d'augmenter, tendance portée notamment par les agents. C'est pour cette raison que nous proposons une intégration adaptée aux start-up comme aux grandes entreprises, qui permet d'accéder en toute sécurité à des centaines de modèles. Les utilisateurs veulent pouvoir changer rapidement de modèle, mener des tests librement et identifier celui qui convient le mieux à leurs workflows. »
Cofondateur et directeur technique d’OpenRouter
La dette technique des LLM s’alourdit à mesure que les équipes adoptent les nouvelles versions sans retirer les versions précédentes
En choisissant de multiplier les modèles, les entreprises s’exposent également à la complexité de leur maintenance. Notre analyse des clients Datadog suggère que les équipes testent rapidement les nouvelles versions de leurs modèles pour rester dans la course, mais se montrent réticentes à retirer les anciennes versions déjà en production. Par conséquent, de nombreuses entreprises risquent d’ajouter des modèles plus rapidement qu’elles n’en suppriment. Or, chaque modèle supplémentaire au sein d’un système d’agents accroît la charge opérationnelle et alourdit les besoins d’évaluation. Les équipes doivent donc valider en continu les performances et gérer les régressions de l’ensemble de leurs modèles actifs.
À prompts, outils et workflows d’agents identiques, les résultats peuvent varier d’un modèle à l’autre, ce qui signifie que chaque modèle supplémentaire introduit son propre profil de qualité, de latence et de coût. Dans la pratique, le renouvellement constant des modèles pose un problème de gouvernance.
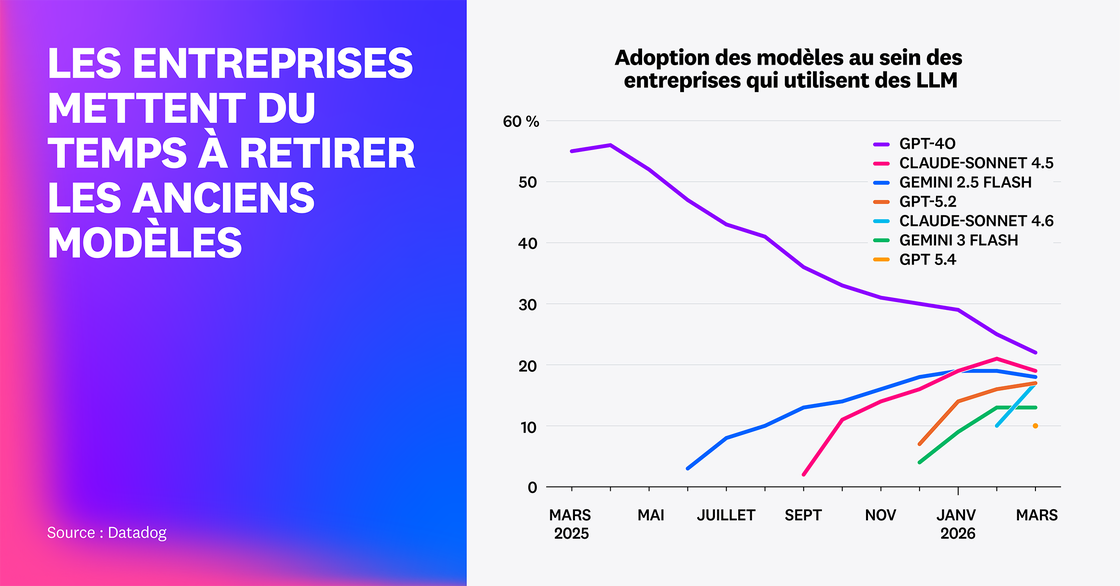
Nous nous sommes penchés sur le taux d’adoption de sept modèles populaires pour comprendre comment les entreprises gèrent la disponibilité de nouvelles versions. Nous avons constaté que les équipes intègrent les nouveaux modèles peu après leur lancement. Par exemple, Claude Sonnet 4.6 a été adopté par 17 % des entreprises dans le mois qui a suivi sa sortie. Parallèlement, l’adoption de modèles plus anciens comme Sonnet 4.5 et GPT-4o a reculé, tout en restant respectivement à 19 % et 22 % en mars 2026. Ces niveaux sont comparables à ceux de Sonnet 4.6 et GPT-5.4. En 2026, aucun modèle ne se démarque clairement, et de plus en plus d’équipes misent sur plusieurs modèles en parallèle.
Même si la gestion de systèmes multi-modèles peut être maîtrisée grâce à une évaluation continue, une gouvernance adaptée et un routage efficace via des passerelles, les équipes devront néanmoins composer avec le retrait progressif des anciens modèles par leurs fournisseurs. Par exemple, alors que GPT-4o était encore le modèle le plus utilisé dans les traces de requête que nous avons examinées lors de notre étude de mars 2026, OpenAI a déjà retiré ce modèle de l’interface de ChatGPT, ce qui pose question quant à la pérennité de son support via l’API.
Avec le doublement des frameworks d’agents, l’importance d’une télémétrie approfondie se renforce
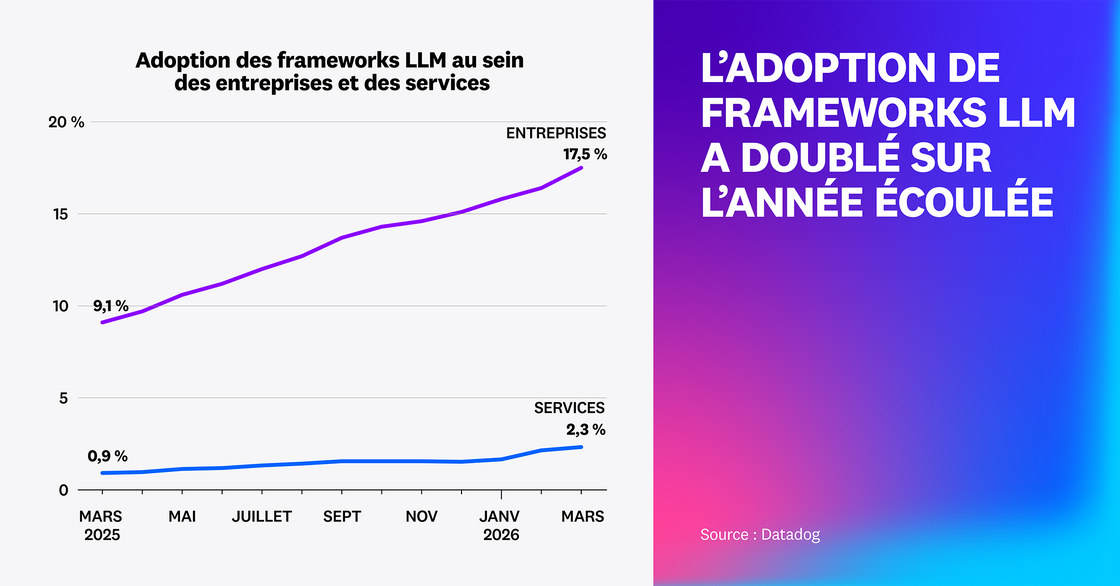
Les frameworks d’agents comme LangChain, Pydantic AI, LangGraph et Vercel AI SDK accélèrent le développement en facilitant la création de patterns récurrents. D’après notre étude, l’adoption de ces frameworks a presque doublé entre début 2025 et début 2026, passant de plus de 9 % des entreprises à presque 18 %. De même, le nombre de services utilisant des frameworks d’agents a plus que doublé sur cette période. Les frameworks accélèrent le développement, mais peuvent aussi introduire une coûteuse complexité opérationnelle. Les équipes ont en effet besoin d’une télémétrie complète des agents pour voir comment ces derniers s’exécutent et identifier les logiques importées inefficaces susceptibles d’être remplacées par des workflows personnalisés.
Cet essor des frameworks se retrouve à l’identique dans toutes les structures, des start-up aux grands groupes, en passant par les entreprises de taille intermédiaire.
Les équipes qui s’appuient sur du code boilerplate fourni par les frameworks pour leurs patterns clés peuvent se retrouver à démultiplier les agents en raison de l’ajout d’étapes et de chemins supplémentaires en arrière-plan. Les ingénieurs ont alors plus de mal à comprendre ce qui se passe au runtime. Dans le développement d’applications d’IA assisté par des frameworks, une seule importation peut engendrer une prolifération d’outils, de mécanismes de reprise et de branches. Il peut en résulter une hausse des coûts et de la latence, mais aussi une plus grande difficulté à reproduire les problèmes. C’est pourquoi il est essentiel pour les équipes de collecter une télémétrie complète des agents pour comprendre leur exécution en conditions réelles, diagnostiquer les comportements imprévus et déterminer à quel niveau les workflows s’éloignent des résultats attendus. Elles pourront ainsi remplacer les logiques importées inefficaces par des workflows sur mesure.
« La prochaine vague de défaillances des agents ne sera pas liée à ce qu'ils ne savent pas faire mais à ce que les équipes ne peuvent pas voir. Les agents doivent intégrer les mêmes boucles de feedback en production que celles attendues des meilleurs logiciels. Contrairement aux logiciels traditionnels, le flux de contrôle des agents est piloté en direct par un LLM, ce qui rend l'observabilité non seulement utile, mais essentielle. »
Fondateur et PDG de Vercel
Les entreprises développent des agents fortement structurés, avec de longs prompts système, mais la mise en cache des prompts reste rare
D’après notre étude, 69 % des tokens d’entrée figurant dans les traces des clients correspondaient à des prompts système : instructions internes, définitions de politiques ou directives pour les outils exécutées en aval de la requête initiale de l’utilisateur. Ce résultat suggère que la plupart des efforts d’ingénierie de contexte des clients Datadog visent à optimiser les prompts système récurrents au sein de systèmes d’agents fortement structurés. Dans la mesure du possible, les équipes doivent réduire les prompts système pour limiter la consommation de tokens et placer les composants réutilisables dans des modules pour pouvoir les mettre en cache.
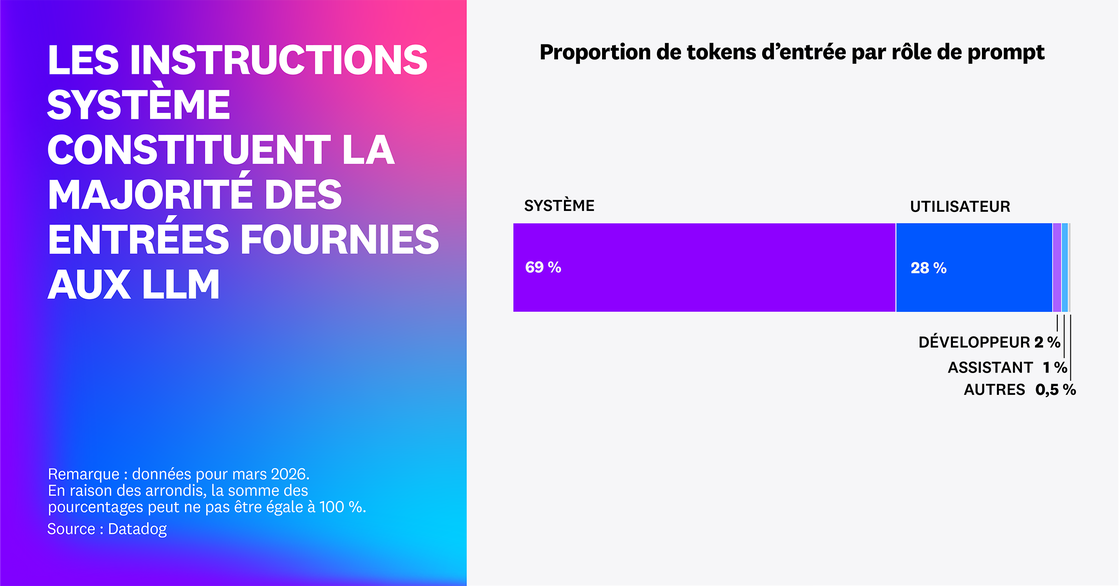
Les systèmes structurés impliquent l’utilisation de davantage d’outils et plus de contraintes, notamment par le biais de politiques et de garde-fous de sécurité. Or, la répétition à l’identique des garde-fous et des instructions des outils d’un appel à l’autre pèse fortement sur les coûts et la latence.
La mise en cache des prompts réduit les coûts et accélère l’exécution de manière très efficace, sans altérer le comportement du modèle. Elle est particulièrement intéressante si les instructions système, politiques et schémas d’outils visant à stabiliser l’application sont réellement réutilisables d’un appel à l’autre. Toutefois, nous avons remarqué que même parmi les modèles compatibles, seuls 28 % des spans d’appels aux LLM présentent des tokens lus depuis le cache. La majorité des appels de ces applications traitent donc toujours le prompt en entier à chaque fois.
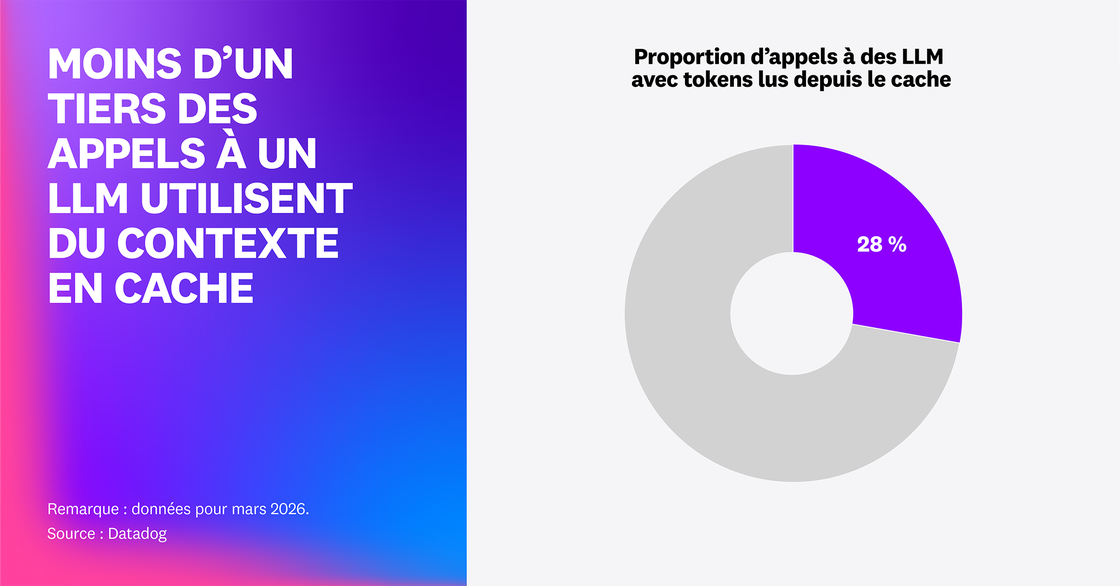
Si le taux d’utilisation du cache ou la part de tokens mis en cache de votre application est faible, le problème vient sans doute de la structuration du prompt. Si le prompt est mal structuré, du contenu dynamique peut être injecté trop tôt ou des blocs d’état censés être stables peuvent être réorganisés ou réécrits d’une requête à l’autre, empêchant ainsi la réutilisation du préfixe nécessaire à la mise en cache.
L’explosion de la fenêtre de contexte ouvre un nouveau potentiel à l’ingénierie du contexte
Avec la montée en puissance de l’IA agentique, les modèles gagnent en puissance et les requêtes volumineuses deviennent moins coûteuses. Les fenêtres de contexte des meilleurs modèles ont gagné plusieurs ordres de grandeur au cours des deux dernières années : de 128 000 tokens jusqu’à près de deux millions de tokens avec certains forfaits. Ces fenêtres ne sont donc plus une limitation pour une grande majorité des utilisateurs. Les équipes en profitent pour introduire dans les prompts davantage de contexte, comme les historiques de conversation, les documents récupérés, les sorties des outils ou les garde-fous. Ce contexte est essentiel pour rendre les agents plus fiables et adaptés à des cas d’usage complexes.
Notre analyse des spans de traces pour les appels aux LLM chez les clients Datadog montre qu’en un an, le nombre moyen de tokens utilisés dans les requêtes a plus que doublé pour les clients médians et quadruplé pour les utilisateurs les plus avancés du 90e percentile.
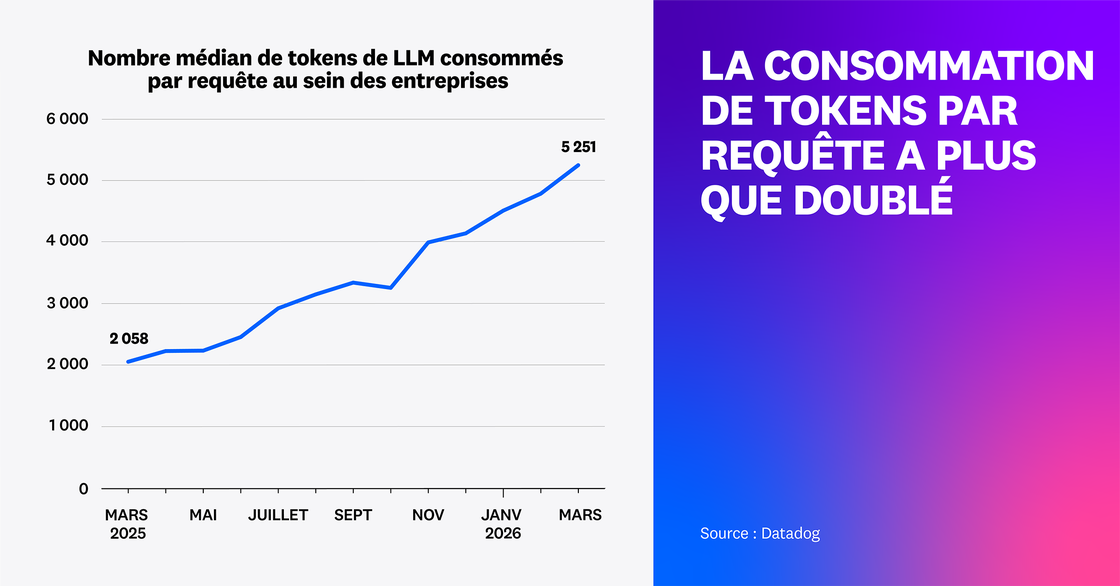
À mesure que la taille des prompts augmente et que les équipes développent de nouvelles façons de collecter, générer et injecter du contexte dans les pipelines d’agents, la latence et les coûts vont inévitablement poser problème. D’autre part, les prompts incluent davantage d’historique, de documents récupérés, de sorties d’outils et de garde-fous. Avec toutes ces informations, le bruit et la redondance peuvent noyer le signal, en particulier lorsque des informations critiques se retrouvent enfouies dans des entrées trop longues.
C’est donc la qualité du contexte, et non sa taille, qui limite désormais la puissance des agents LLM. La plupart des équipes sont encore loin d’exploiter pleinement la taille de contexte offerte par leurs modèles. La principale problématique n’est donc pas tant de gérer les tokens que de comprendre quelles informations sont utiles aux décisions des modèles. Les entreprises qui investissent dans l’ingénierie du contexte (qualité des données récupérées, synthèse, déduplication et hiérarchisation claire des informations) combleront l’écart entre ce que permettent les modèles à long contexte et ce que les agents en production peuvent exploiter de manière fiable. Cela implique de mettre en place des systèmes capables de sélectionner, compresser et structurer de manière fiable les informations les plus pertinentes pour la prise de décision, afin que le modèle puisse en tirer le meilleur parti.
La fiabilité des agents plafonne en raison des erreurs de quota, première cause d’échec des appels aux LLM
Nous nous sommes penchés sur les échecs des appels aux LLM dans les traces des clients de Datadog LLM Observability. En février 2026, notre analyse montre que 5 % de l’ensemble des spans d’appels aux LLM ont signalé une erreur, dont 60 % étaient dus à des dépassements de quota. En mars 2026, 2 % de l’ensemble des spans LLM de notre dataset ont renvoyé une erreur, dont près d’un tiers était lié à des quotas, soit près de 8,4 millions d’erreurs au total. Ces chiffres suggèrent que les capacités limitées des fournisseurs de modèles compromettent la fiabilité des agents. Pour garantir la fiabilité dans des environnements dynamiques, lorsque la capacité maximale des agents dépend des quotas, les entreprises doivent jouer sur deux leviers : des mesures opérationnelles (gestion des budgets et mécanismes de backpressure) et l’optimisation des prompts.
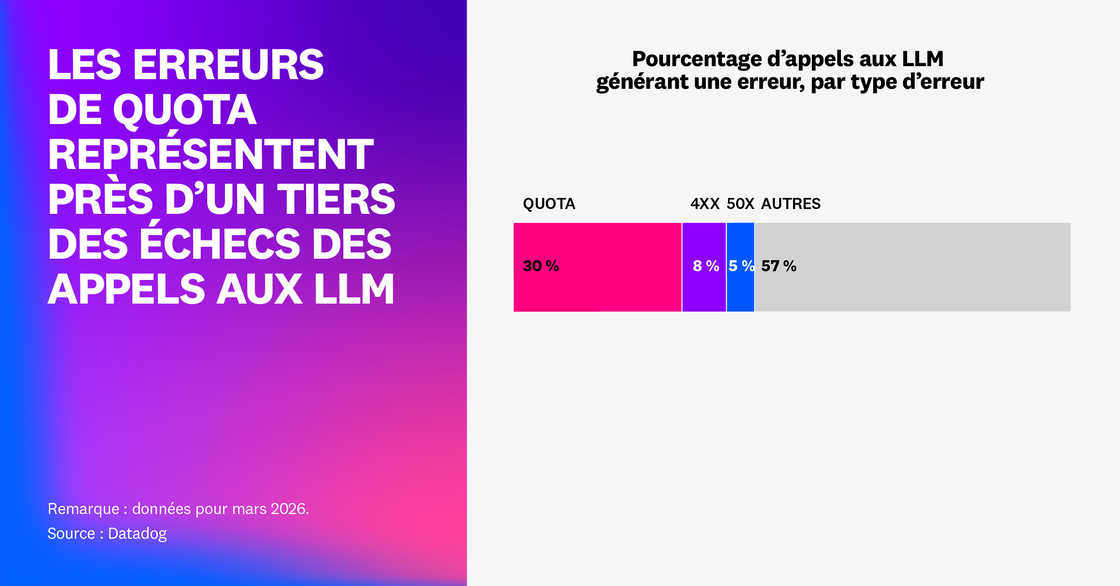
Lorsque la principale cause des défaillances d’applications basées sur des LLM réside dans des problèmes de capacité, les équipes doivent travailler sur l’ingénierie de capacité. En particulier, des quotas de capacité partagés à l’échelle de l’entreprise, combinés à des pics de concurrence et de tentatives de reprise, peuvent entraîner des hausses ponctuelles du volume de requêtes qui épuisent de manière imprévisible la capacité allouée. C’est particulièrement vrai pour les systèmes qui exécutent des boucles variables avec des méthodologies ReAct par exemple, ou plusieurs agents collaboratifs. Le problème s’aggrave lorsque des boucles d’agents de longue durée atteignent les quotas des fournisseurs ou les plafonds de requêtes parallèles de l’entreprise, car des tentatives de reprise risquent d’accroître encore la charge. D’une simple difficulté, les équipes font alors face à une défaillance durable du système.
Les prompts et la logique applicative doivent être pensés de sorte à éviter les pics de longueur de boucle et la multiplication des appels aux outils. En parallèle, les équipes de plateforme doivent déployer des systèmes de file d’attente, mécanismes de backoff et des capacités de repli dans l’environnement d’exécution des applications LLM. Par ailleurs, en mettant en place des budgets pour contraindre les boucles d’agents à s’arrêter une fois un nombre maximal d’appels ou de tokens atteint, les équipes peuvent éviter les boucles incontrôlées susceptibles de dépasser les capacités et d’impacter les services en aval.
Les agents sont encore en grande majorité monolithiques
D’après notre étude, 59 % des requêtes d’applications agentiques ne passent qu’un appel à un service, quand seulement 18 % des requêtes de bout en bout en passent au moins trois. Ces chiffres révèlent qu’une grande majorité des agents restent encore monolithiques. Pour autant, certaines entreprises semblent tester des architectures multi-agents ou déployer des agents sur leurs propres services afin de s’interfacer avec le reste de leur environnement selon une logique de microservices.
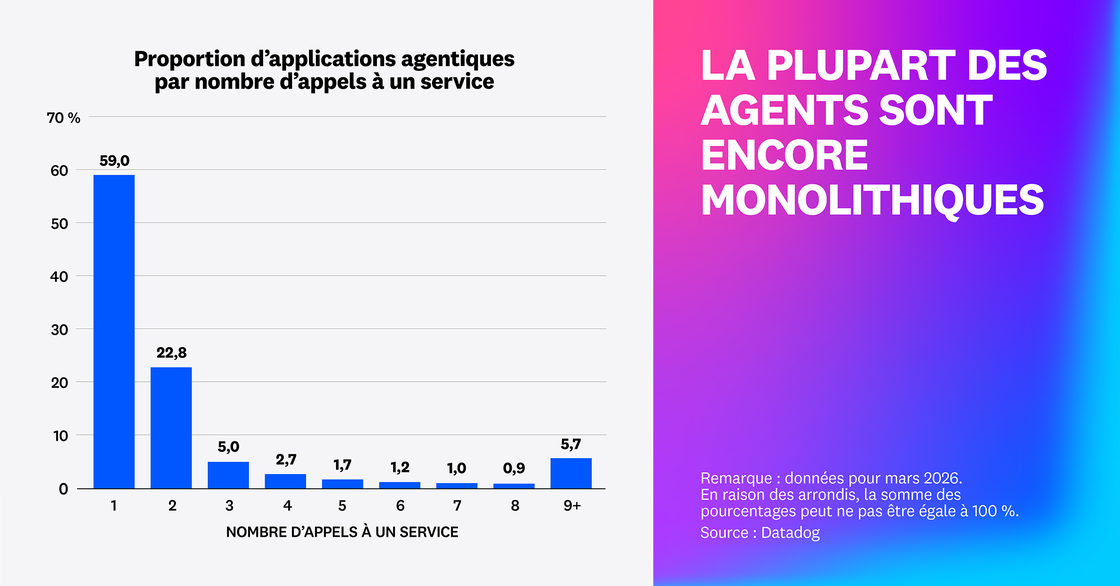
Les équipes savent que les structures monolithiques se scalent difficilement et cherchent à changer d’approche, mais les agents en production restent pour l’heure majoritairement monolithiques. La transition vers des services d’agents dédiés et des architectures multi-agents impose de nouvelles exigences pour les plateformes des entreprises. Pour déboguer et tester ces applications, les équipes doivent propager le contexte et les traces à travers les différents services. Pour gérer ces plateformes distribuées, elles ont besoin de cartographies de services intégrant également les outils.
Perspectives
Les entreprises technologiques spécialisées en IA misent sur des systèmes multimodèles structurés, fortement contextualisés et de plus en plus distribués dont le succès repose sur l’évaluation continue du comportement, des performances et des coûts des agents. Les architectures d’agents deviennent de plus en plus complexes : les fenêtres de contexte s’agrandissent, les prompts se multiplient et les risques d’exposition aux dérives invisibles s’aggravent.
Face à ces défis, les équipes doivent acquérir de nouvelles compétences : piloter des boucles d’évaluation fiables, réfléchir à l’ingénierie du contexte, structurer des entrées à forte valeur informationnelle et encadrer activement la prolifération des modèles et du contexte avant qu’elle ne se transforme en dette technique. Malgré toutes ces évolutions, les bases de l’excellence opérationnelle restent d’actualité. Les équipes doivent continuer à maîtriser les budgets et le backpressure, prévoir des mécanismes de repli et orienter chaque tâche vers le modèle le plus adapté. Les entreprises qui sortiront du lot auront transformé leurs agents en systèmes de production rigoureux, évalués et améliorés en continu, pour les rendre plus observables, gouvernables, résilients et maîtrisés en termes de coûts.