---
title: "Toto 2.0: Time series forecasting enters the scaling era"
description: "For the first time, a time series foundation model gets reliably better with scale—five open-weights sizes from 4m to 2.5B parameters, trained from a single recipe."
author: "Emaad Khwaja, Gerald Woo, Chris Lettieri, Ameet Talwalkar, David Asker"
date: 2026-05-14
tags: ["ai", "ai research", "machine learning", "open source"]
blog_type_id: ai
locale: en
---
Today we’re releasing [Toto 2](https://github.com/DataDog/toto), a family of open-weights time series forecasting models, [on Hugging Face](https://huggingface.co/collections/Datadog/toto-20). Spanning 4m to 2.5B parameters, Toto 2.0 is designed to answer a simple and open question: Can time series foundation models (TSFMs) improve as they scale? Our results show they can. The highlights:
- **Scaling that works.** Every size improves on the one below it, with no sign of saturation at 2.5B.
- **Best in class on every benchmark we tested.** Toto 2.0 takes the top spots on[ BOOM](https://huggingface.co/spaces/Datadog/BOOM) (Datadog's observability forecasting benchmark),[ GIFT-Eval](https://huggingface.co/spaces/Salesforce/GIFT-Eval) (the standard general-purpose benchmark), and[ TIME](https://huggingface.co/spaces/Real-TSF/TIME-leaderboard) (a new contamination-resistant zero-shot benchmark).
- **A generational jump from **[**Toto 1.0**](https://www.datadoghq.com/blog/ai/toto-boom-unleashed.md)**.** Toto 2.0 is 7× more parameter-efficient at matching quality and dramatically faster at inference time.
- **Trained on observability and synthetic data, generalizes broadly.** Toto 2.0 does not see any public forecasting data during pretraining, yet leads the field on general-purpose benchmarks.
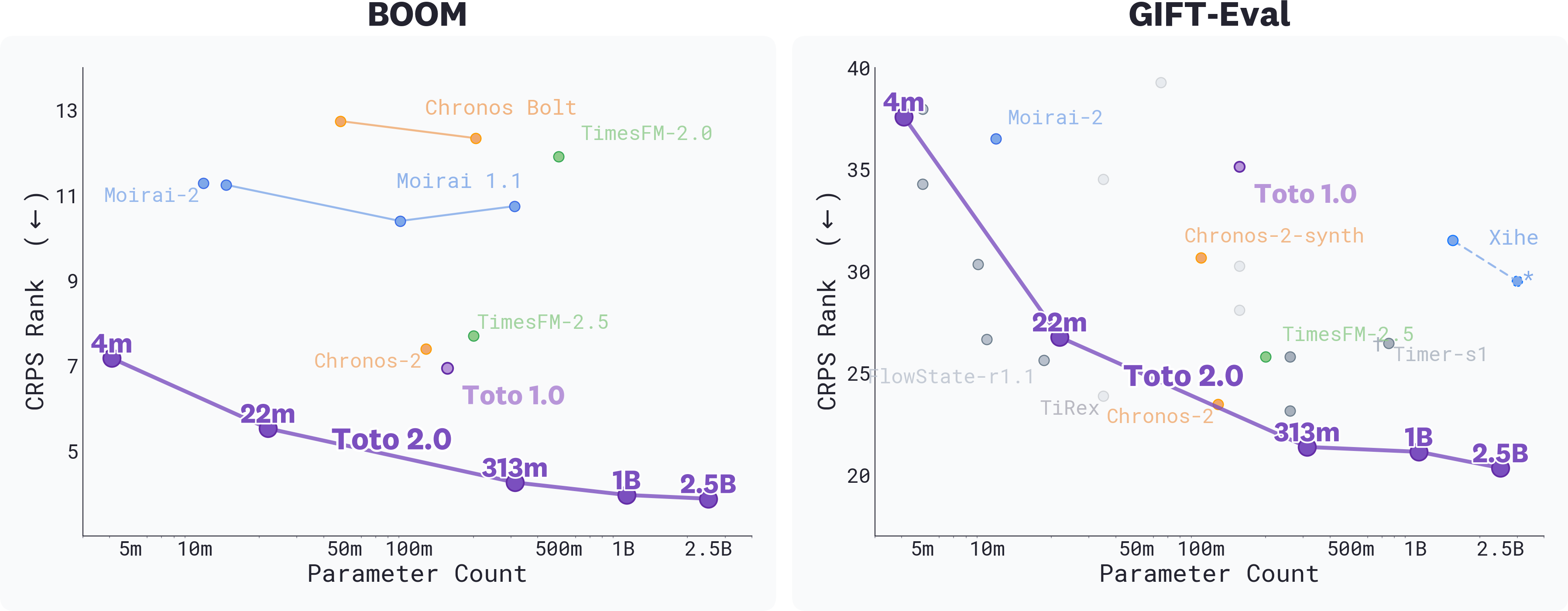
*CRPS Rank vs. parameter count on BOOM (left) and GIFT-Eval (right) for top foundation models; lower is better. The Pareto frontier traces the best CRPS rank achievable at each parameter budget—points on or near it represent the best quality-for-size tradeoff available. Every Toto 2.0 size sits on or near the frontier on both benchmarks, and CRPS rank improves monotonically with model size across the family. *
This post first walks through the [results and scaling behavior](#results), including inference latency improvements and long-horizon stability. It then details where we think the [next set of bottlenecks and opportunities for TSFMs are](#whats-next-for-tsfms): closing the long-horizon gap with classical baselines, data curation, evaluation that tracks downstream value, and multimodality. We will soon release a technical report providing more details on our training data, our architectural and training recipes, and our u-μP hyperparameter transfer pipeline that tunes hyperparameters once on a small proxy model.
Both the [Toto 2.0 model weights](https://huggingface.co/collections/Datadog/toto-20) and our infrastructure library for distributed u-μP training ([dd_unit_scaling](https://github.com/DataDog/toto/tree/main/dd_unit_scaling)) are available under the Apache 2.0 license.
## Results
Toto 2.0 sets a new state of the art on [BOOM](https://huggingface.co/spaces/Datadog/BOOM), [GIFT-Eval](https://huggingface.co/spaces/Salesforce/GIFT-Eval), and [TIME](https://huggingface.co/spaces/Real-TSF/TIME-leaderboard). On BOOM, every size sits on the Pareto frontier. Among foundation models on GIFT-Eval, the three largest Toto 2.0 sizes lead the field. On the broader leaderboard that includes finetuned, ensemble, and agentic systems, our finetuned 2.5B (FT) and "Toto 2.0 Family and Friends" (FnF) ensemble take the top two slots outright. On TIME, the three largest Toto 2.0 variants hold top ranks.
All benchmarks report results across several metrics. CRPS (Continuous Ranked Probability Score) measures the quality of a probabilistic forecast, scoring how well a predicted distribution over future values aligns with observed outcomes. It is the metric most directly relevant to production forecasting use cases. MASE (Mean Absolute Scaled Error) measures point forecast accuracy, normalized against a naive seasonal baseline. Where metrics are reported as ranks, scores are averaged across all benchmark datasets to enable comparison across heterogeneous data.
### BOOM
BOOM evaluates forecasting on observability metrics like CPU, memory, request latency, and error rates. These are the signals production monitoring systems care about.
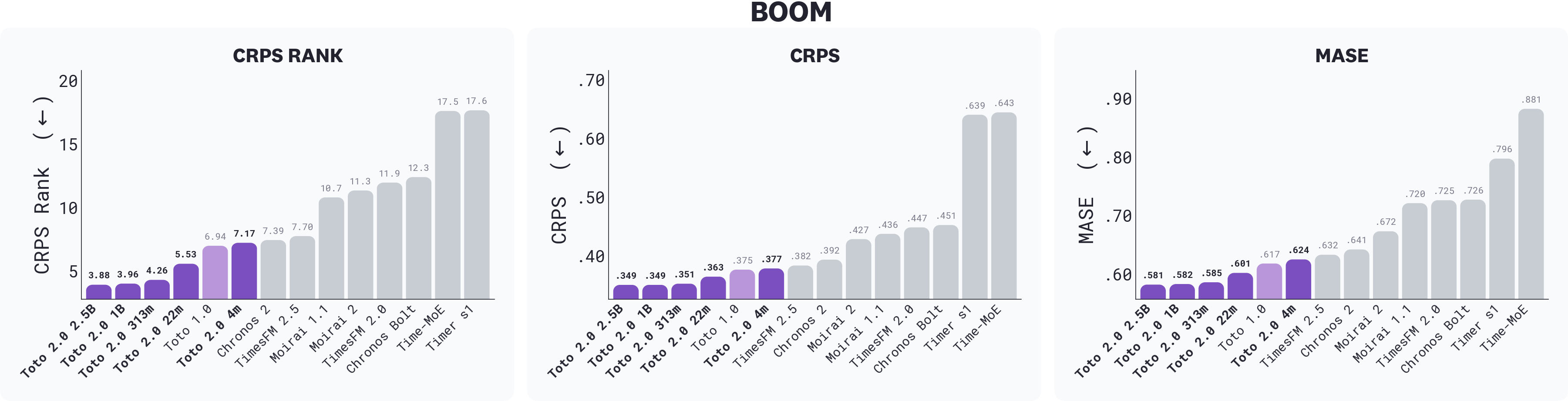
*BOOM results across CRPS rank, CRPS, and MASE; lower is better. All five Toto 2.0 sizes outrank every other foundation model on every metric. Toto 2.0 22m matches or beats Toto 1.0 across all three with roughly 7× fewer parameters. Toto models are shaded in purple.*
Every Toto 2.0 size sits on the Pareto frontier of BOOM: at any given parameter count, no other foundation model produces better forecasts. The three largest sizes lead the chart, with CRPS ranks of 3.88 (2.5B), 3.96 (1B), and 4.25 (313m). Behind them, the 22m at 5.52 already clears Toto 1.0 (6.94), establishing a 7× parameter-efficiency improvement over the previous generation. The 4m, at 7.17, is competitive with Toto 1.0 and Chronos-2 (7.39) despite being 30–40× smaller, making it a strong option for edge deployment.
### GIFT-Eval: Foundation models
GIFT-Eval is a general-purpose forecasting benchmark spanning 97 datasets across domains such as energy, retail, weather, and finance. Notably, Toto 2.0 base models are not trained on any public data from these domains.
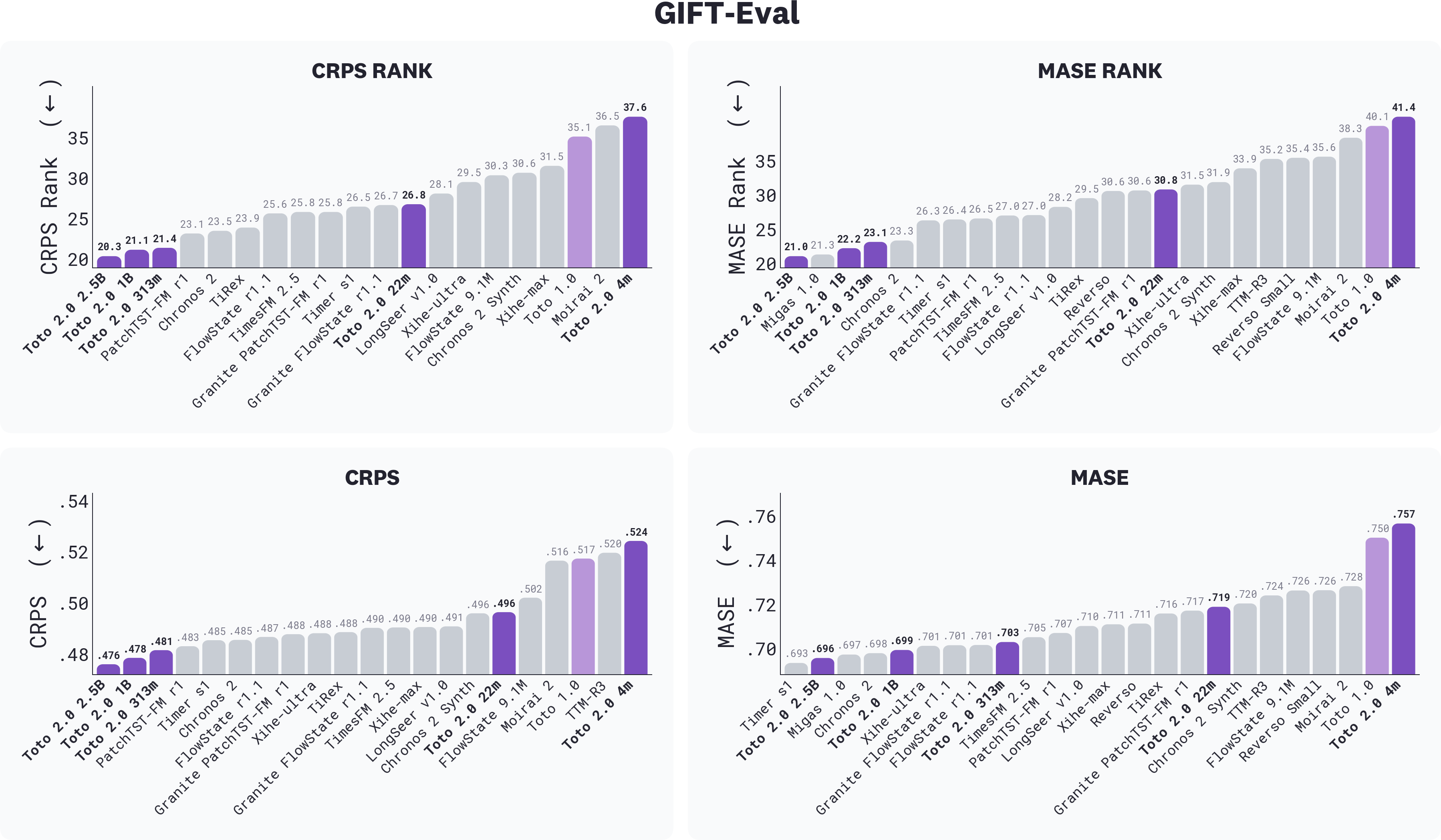
*GIFT-Eval results, filtered to foundation models only (i.e., excluding finetuned, ensemble, and agentic systems), across CRPS rank, MASE rank, CRPS, and MASE; lower is better. Toto 2.0 sizes are highlighted in purple. The three largest Toto 2.0 sizes lead on CRPS rank, while the 2.5B leads on MASE rank.
*
Toto 2.0 ranks **first** among foundation models. The three largest sizes score 19.5 (2.5B), 20.3 (1B), and 20.5 (313m) on CRPS rank, with a 1.6-point gap separating the 313m from the next best foundation model, PatchTST-FM r1 [^8] at 22.1. Chronos-2, a strong competitor, sits at 22.4. The 22m at 25.7 beats Toto 1.0 (33.9) by 8 points. Every size strictly improves on the one below it on rank metrics.
###
GIFT-Eval: Finetuned models
In addition to pretrained foundation models, the GIFT-Eval leaderboard also includes entries for finetuned foundation models (those that have been tuned on the official training split of the benchmark), as well as agentic and ensembling methods that combine multiple foundation models. The five Toto 2.0 base models serve as the starting point for our finetuned models. To see how easily Toto base models can be finetuned for downstream tasks, we explored two approaches that use in-distribution data: finetuning a single model on a mix that includes the GIFT-Eval train split, and ensembling multiple models with a learned per-window weighting scheme. Both place at the top of the leaderboard, with ensembling and finetuning taking first and second on both CRPS and MASE rank.
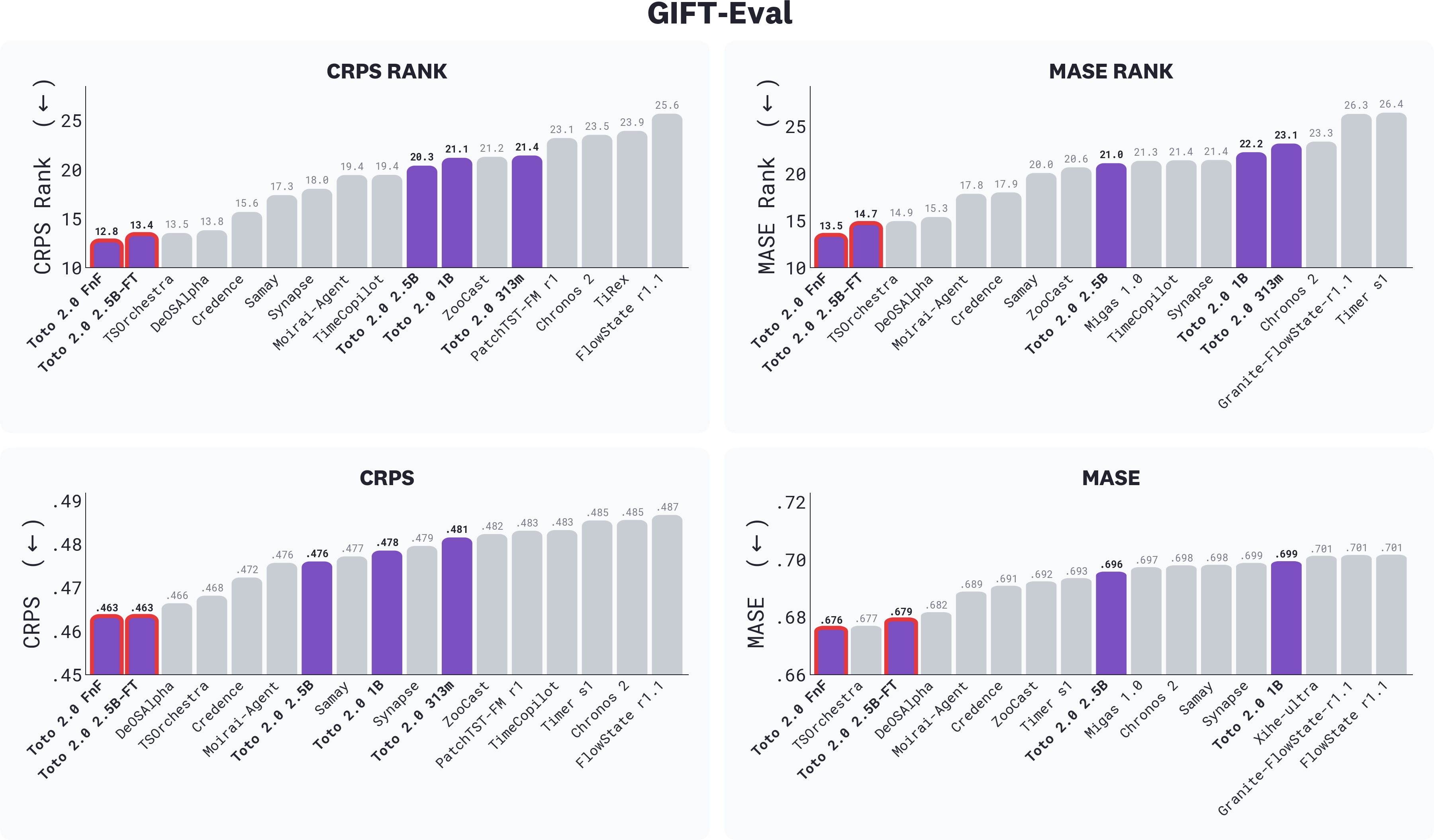
*GIFT-Eval leaderboard, showing all submission types: foundation models, finetuned models, ensembles, and agentic systems together. On this leaderboard, "finetuned" is used as an umbrella term for any model that uses the GIFT-Eval training split, including ensemble and agentic systems. Toto 2.0 sizes are highlighted in purple, with finetuned models outlined in pink. Toto 2.0 FnF takes #1 across CRPS rank, MASE rank, CRPS, and MASE; Toto 2.0 2.5B-FT alone places second, ahead of all prior leaderboard entries.*
The ensemble takes first on the GIFT-Eval leaderboard, ahead of the finetuned 2.5B. But the more interesting finding is what’s *inside* the ensemble. The meta-learner’s softmax weights reveal what each candidate actually contributes to that prediction. The Toto 2.0 family is the largest contributor to the ensemble, accounting for 39% of predictions on average—more than any other model in the pool, including Chronos 2 (32%), and more than the four remaining open models combined. The fact that nearly 40% of that combination is consistently routed through Toto demonstrates Toto's distinctive role in capturing patterns that the rest of the pool cannot. In other words: when the meta-learner is free to weight everything it has, it spends more on the Toto family than on any other source.
### TIME
TIME is a recent, task-centric zero-shot forecasting benchmark constructed from “fresh”* *datasets specifically chosen to mitigate the test-set contamination that affects established benchmarks. Toto 2.0 sweeps the top of the leaderboard: the 2.5B, 313m, and 1B take the top three positions on every TIME metric, with the next best external foundation model trailing the 1B by a clear margin. The 22m comes in fifth on rank metrics, ahead of every prior-generation foundation model we tested, and every size from the 22m up outperforms Toto 1.0.
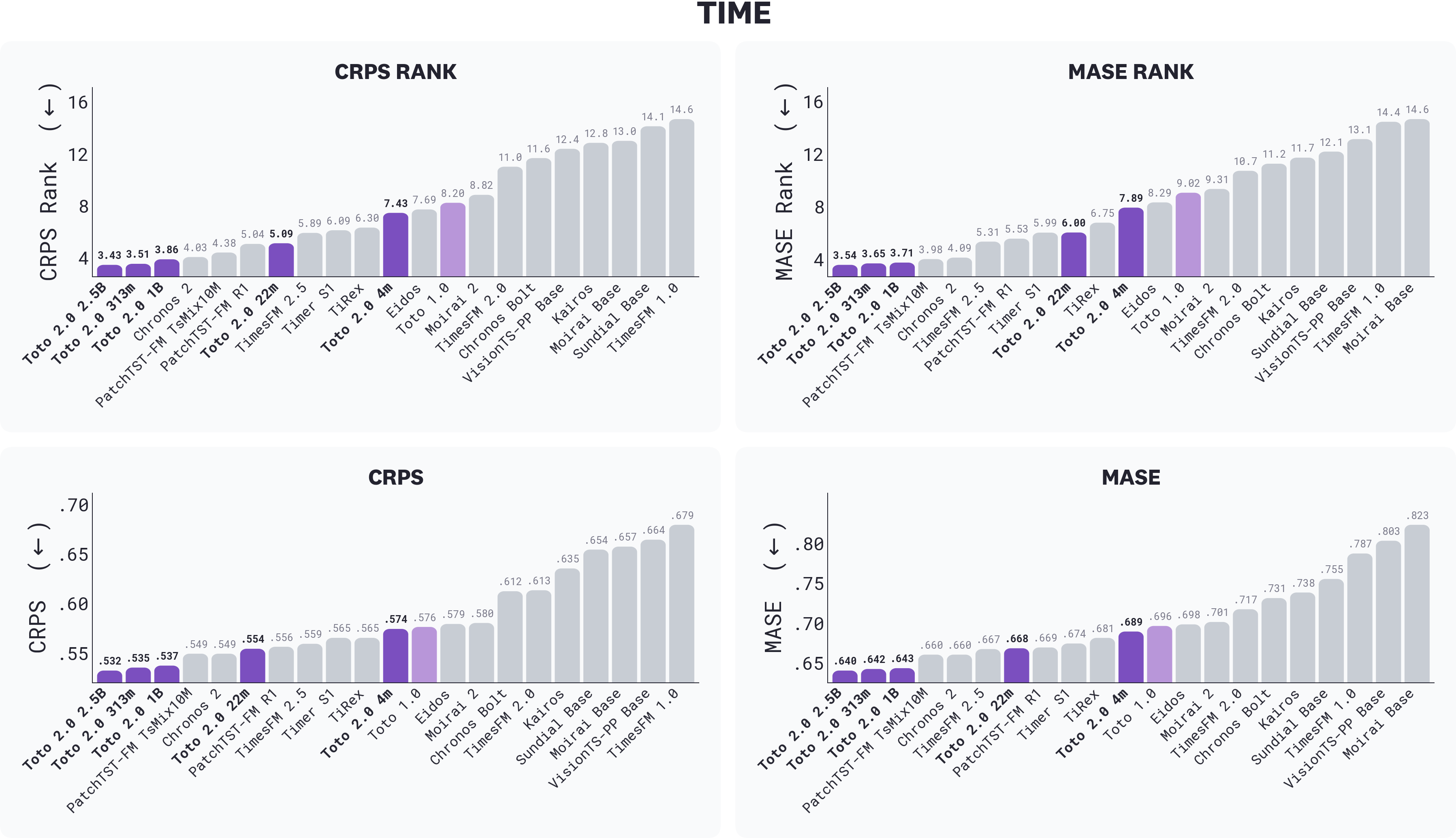
*Results on TIME across CRPS rank, MASE rank, CRPS, and MASE; lower is better. Toto 2.0 sizes are highlighted in purple. The 2.5B is the best Toto 2.0 size on every metric; the only deviation from strict monotonicity is the 313m, which slightly outperforms the 1B.*
### Inference latency
Toto 2.0 includes a series of refinements to the Toto 1.0 backbone, including contiguous patch masking (CPM), which lets the model predict an entire forecast in one parallel pass instead of step by step. CPM doesn't just improve forecast quality, it makes Toto 2.0 dramatically faster. A 1024-step forecast with Toto 1.0 requires up to 16 sequential autoregressive steps; with Toto 2.0 in single-pass mode, it's one forward pass.
We evaluate forward pass latency against Toto 1.0 and Chronos-2, the previous SOTA model on GIFT-Eval. Every Toto 2.0 size is significantly faster than Toto 1.0 at this horizon. Our 313m runs at roughly the same latency as Chronos-2 at 120m parameters. At horizons of 2048+, even the 2.5B in single-pass mode remains faster than Chronos-2.
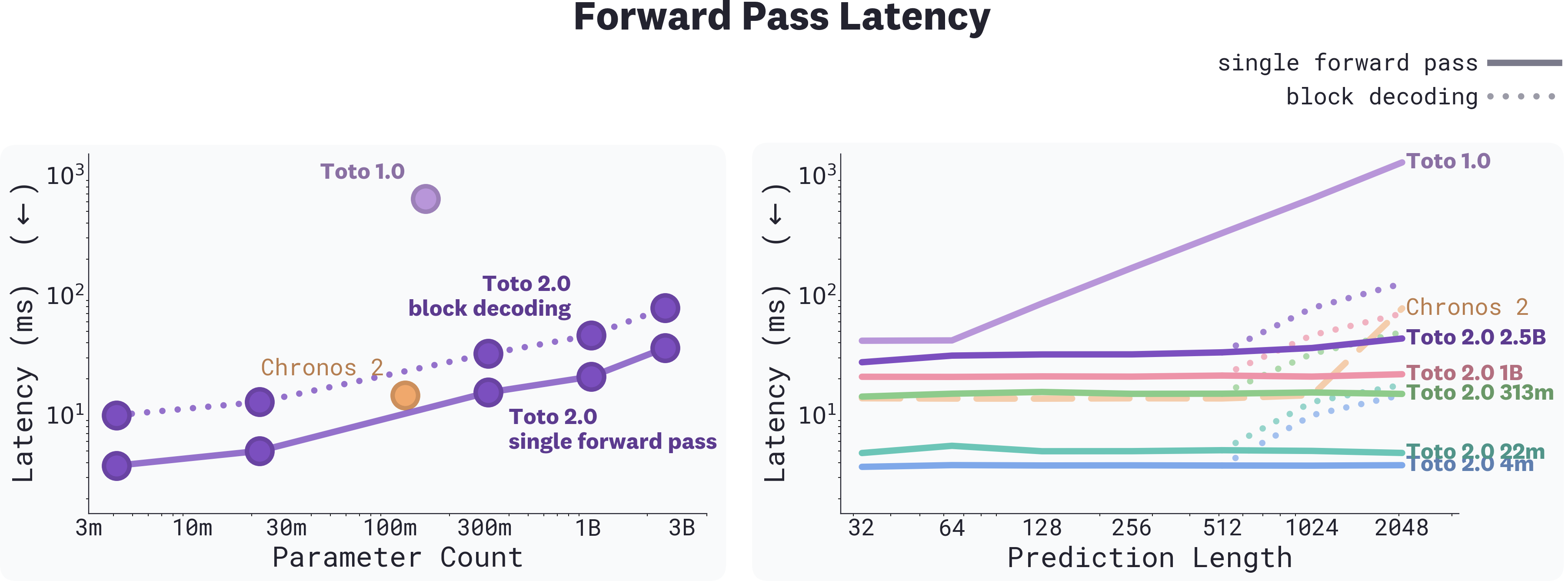
*Left: Forward-pass latency vs. parameter count at forecast length 1024. Every Toto 2.0 size is significantly faster than Toto 1.0. Right: Forward-pass latency vs. prediction length (log scale). Toto 2.0 stays flat in single-pass mode up to a 768-point forecast length, which we found best on synthetic signals.*
The two decoding modes, single-pass and block decoding, trade off speed for long-horizon stability. Single-pass runs the entire horizon in one forward pass and is what we use for leaderboard submissions. Block decoding generates the horizon in segments, conditioning each on the previous segment's median, with KV caching for efficiency. It's slower but reduces drift over long horizons. The CPM training regime exposes both, so the same checkpoint handles either mode at inference.
### Long-horizon stability
Forecast quality on benchmarks like BOOM, GIFT-Eval, and TIME reflects how a model performs within or near its training context. But foundation models don't always behave the same way *beyond* that context. To understand how Toto 2.0 generalizes when asked to forecast much further than it was trained on, we evaluated all five sizes on synthetic multi-scale signals at horizons of 2,048, 4,096, and 8,192 timesteps (well past the 4,096-step training context used for Toto 2.0).
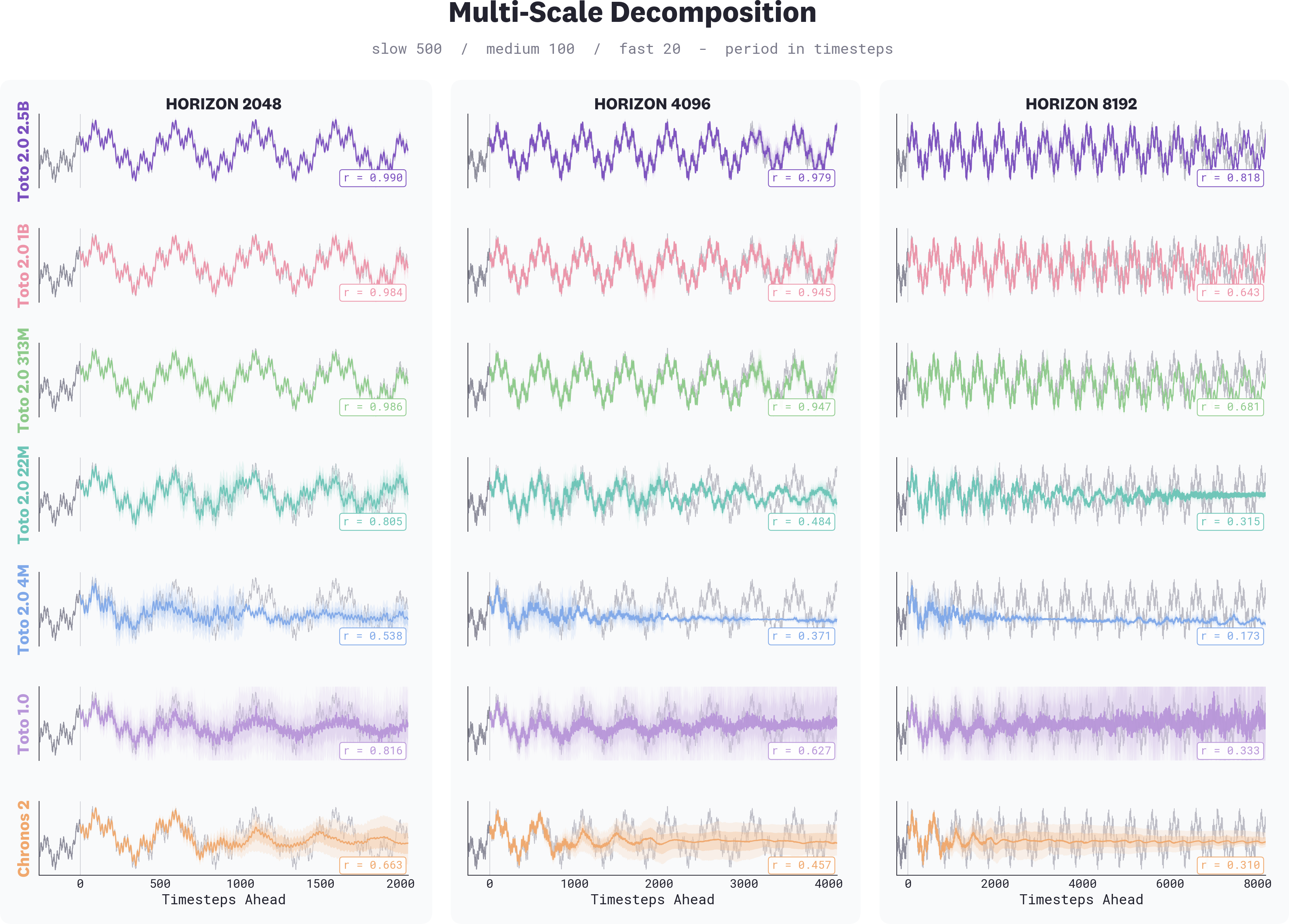
*Forecasts on a synthetic multi-scale signal (superimposed periods of 500, 100, and 20 timesteps) at three horizons. Each row is a model, and each column a horizon. Larger Toto 2.0 sizes maintain coherent multi-scale structure at 8,192 steps; smaller sizes and prior-generation models lose structure progressively. Pearson correlation against ground truth shown in each panel. Toto 2.0 forecasts use block decoding.*
The 4m captures short-range patterns but collapses past its training horizon, producing flat or noisy forecasts. The 22m holds longer but degrades by 4,096. The 313m is stable through 4,096 but loses structure beyond that point. The 1B maintains the underlying pattern across all three horizons, and the 2.5B is more accurate still. Toto 1.0 and Chronos-2, despite Chronos-2 being trained on longer sequences, both lose coherence well before the 1B does.
Foundation models capture dynamics beyond the reach of statistical baselines, but they also exhibit failure modes those baselines never had: drift, mode collapse, and structural breakdown past training context. Long-horizon stability is one such failure mode, and likely not the only one. Scale clearly helps; the gap between 4m and 2.5B is large, and our results show the problem diminishes steadily as parameter count grows. But no size we tested eliminates it entirely past 8,192.
## What’s next for TSFMs?
Time series foundation models had their BERT moment last year. [Toto 1.0](https://www.datadoghq.com/blog/ai/toto-boom-unleashed.md) and a contemporary wave of foundation models beat tuned statistical baselines at zero-shot forecasting, demonstrating that a single pretrained model could transfer across domains the way BERT did for language. But no prior TSFM family had shown compelling scaling across sizes. In fields like NLP and vision, training a bigger version of the same model has reliably produced better results; for time series, it had not.
Toto 2.0 is the first model family for which simply making the model bigger reliably makes it better. Similar to how GPT-2 demonstrated that scaling language models was no longer a research question but a tool, the same is now true for TSFMs. Our results show smooth improvements up to 2.5B with no sign of saturation, and scaling to larger models using more data is a natural direction for future work. We conclude by briefly outlining what we see as some other important open questions to move the field forward:
**Closing the gap with classical baselines. **Foundation models capture dynamics classical statistical methods can't: multivariate interactions, long context, transfer across domains. But classical methods still have properties foundation models lack: clean extrapolation on simple signals, calibrated uncertainty that doesn't degrade with horizon, predictable behavior outside the training distribution, no mode collapse. [Our long-horizon experiments](#long-horizon-stability) are one window into this. Even the 2.5B loses some structure at 8,192 steps where a properly-fitted seasonal model would extrapolate cleanly. The gap shows up in many places: tail behavior, regime shifts, and forecasts on signals far outside any plausible training distribution. Closing it will likely require a combination of targeted architectural changes, continued scaling, and novel post-training objectives.
**Data curation.** Data curation in TSFMs has been ad hoc. We mix observability metrics with synthetic series and a few public datasets, sample frequencies in proportions chosen by hand or by sweep, and call it good. In language modeling, data curation is treated as a first-class research problem: quality filtering, deduplication, annotation, mixing, curriculum. TSFM research hasn't gotten there yet, partly because scaling itself was still the open question. In our own hyperparameter sweep, the optimal mix for pretraining excluded public data entirely, while the optimal mix for fine-tuning was 45% public. These aren't intuitive results, and we arrived at them empirically rather than through principled selection. With scaling now reliable, it's time to take curation more seriously.
**Metrics as a distinct modality. **With Toto 1.0 and 2.0, we have built TSFMs suited for generic time series found commonly in the open. However, here at Datadog, we are interested in modeling the massive amounts of [metrics data](https://docs.datadoghq.com/metrics.md) that we collect. While we have been able to cast Datadog metrics as basic time series, they are in fact a distinct data modality with unique properties. By compressing them into the mold of generic time series data, we are losing significant amounts of information and structure present in our data. In future work, we aim to prioritize the unique challenges of modeling Datadog metrics, such modeling the various metric types on the Datadog platform, and dealing with complex seasonality and complex multivariate structure.
**Multimodality and world models for observability. **While multimodality for time series models has become an increasingly hot topic, it has invariably focused on time series + text with limited datasets and evaluations. At Datadog, we care about models that understand how distributed systems behave. The platform sees everything that happens in production systems, and this means we can develop models that deal with not just metrics, but also traces, logs, topology, code changes, events, alerts, text, etc. Our first step in this direction has been our recently released [ARFBench](https://www.datadoghq.com/blog/ai/introducing-arfbench.md), which focused on evaluating incident-grounded multimodal reasoning. Our longer term goal is to develop a full-fledged world model for observability, extending to all telemetry types, unlocking capabilities such as proactive incident detection, root cause analysis, counterfactual analysis, simulation, and agent training.
## Release
We are releasing:
- **Toto 2.0 model weights**. All five sizes (4m, 22m, 313m, 1B, 2.5B) on [Hugging Face](https://huggingface.co/collections/Datadog/toto-20).
- **Our distributed hyperparameter transfer training wrapper.** u-μP for `torch.compile`, FSDP2, and DDP—[dd-unit-scaling](https://github.com/DataDog/toto/tree/main/dd_unit_scaling).
Both are released under the Apache 2.0 license.
## Quick start
Installation:
```shell
pip install "toto-2 @ git+https://github.com/DataDog/toto.git#subdirectory=toto2"
```
Eval:
```Python
import torch
from toto2 import Toto2Model
model = Toto2Model.from_pretrained("Datadog/Toto-2.0-22m")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device).eval()
# (batch, n_variates, time_steps)
target = torch.randn(1, 1, 512, device=device)
target_mask = torch.ones_like(target, dtype=torch.bool)
series_ids = torch.zeros(1, 1, dtype=torch.long, device=device)
# Returns quantiles of shape (9, batch, n_variates, horizon)
# Quantile levels: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
quantiles = model.forecast(
{"target": target, "target_mask": target_mask, "series_ids": series_ids},
horizon=96,
decode_block_size=768,
has_missing_values=False,
)
```
**We're hiring on the Datadog AI Research team in New York and Paris. **[**Apply here.**](https://careers.datadoghq.com/all-jobs/?s=ai%20research&parent_department_Engineering%5B0%5D=Engineering&utm_source=engblog&utm_medium=corpsite&utm_campaign=engcommunity-2025-ai-toto&gh_src=hm4uekgj1us)