Observability Pipelines Kubernetes Deployment
September 3, 2025
Introduction
As environments grow in complexity and volume, teams need to reduce data sprawl, optimize cost, and maintain data quality across a wide range of sources and destinations. Datadog Observability Pipelines uses on-premise pre-processing capabilities to help organizations manage, transform, and route log data at scale within their environment.
Observability Pipelines helps you control log volume and cost by filtering out the most relevant logs before egressing them to more expensive storage solutions. It also enables you to extract key metrics from logs on-prem before filtering them out, so you can alert on the most important telemetry without sending the full log to your destination.
Deploying Datadog Observability Pipelines in Kubernetes enables scalable, flexible, and efficient log processing across containerized environments. This deployment method allows the platform to manage the availability and scaling of Observability Pipelines Workers, which aggregate, process, and route logs throughout your environment.
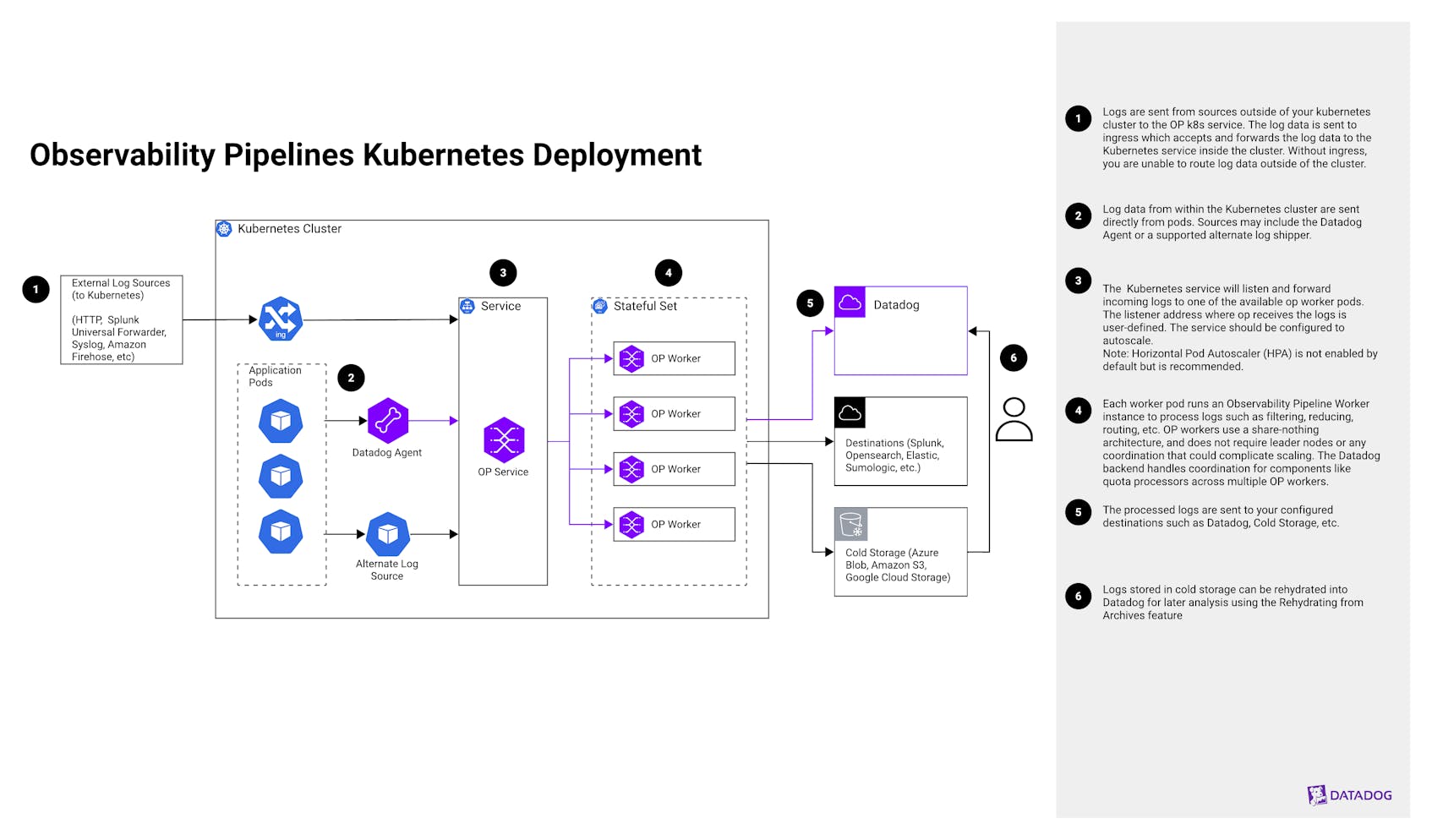
Explanation of the architecture
This architecture deploys Datadog Observability Pipelines in a Kubernetes cluster to ingest, process, and route observability data at scale. It is ideal for organizations that require fine-grained control over telemetry volume, cost, and routing logic—especially in containerized environments with high log throughput. The deployment includes the Observability Pipelines service, which acts as a centralized listener for internal and external log sources, and a set of Observability Pipelines Workers that perform filtering, redaction, transformation, and routing. This setup is well-suited for teams looking to implement cost control, compliance filtering, or multi-destination routing directly within their cluster.
Step 1
Logs are sent from sources outside of your Kubernetes cluster to the Observability Pipelines Kubernetes service. The log data is sent to ingress, which accepts and forwards the log data to the Kubernetes service inside the cluster. Without ingress, you are unable to route log data outside of the cluster.
Step 2
Log data from within the Kubernetes cluster is sent directly from pods. Sources sending log data may include the Datadog Agent or a supported alternate log shipper or source,including but not limited to Splunk, Sumo Logic, Syslog, HTTP, and more.
Step 3
The Kubernetes service will listen and forward incoming logs to one of the available op worker pods. The listener address where Observability Pipelines receives the log data is user-defined. The service should be configured to autoscale. Note: Horizontal Pod Autoscaler (HPA) is not enabled by default but is recommended.
Step 4
Each worker pod runs an Observability Pipeline Worker instance to process logs by performing actions such as filtering, reducing, routing, and more. Observability Pipeline Workers use a share-nothing architecture and do not require leader nodes or any coordination that could complicate scaling. The Datadog backend handles coordination for components like quota processors across multiple Observability Pipelines Workers.
Step 5
Once the logs are processed, they are sent to your configured destinations such as Datadog, cold storage, or any supported destination.
Step 6
Logs sent to cold storage from Observability Pipelines are automatically sent in Datadogs rehydratable format. Logs stored in cold storage can be rehydrated into Datadog for later analysis using the Rehydrating from Archives feature.
Key Benefits
- 1. Log Volume Control: Manage logging costs by applying filters, sampling, bifurcation, deduplication, and quotas to control which logs are sent to multiple destinations.
- 2. Data Enrichment: Modify logs by adding, editing, or removing fields; include or exclude tags; and parsing unstructured logs into structured formats.
- 3. Egress Cost Optimization: Minimize network egress and storage costs by extracting key metrics from logs on-prem before filtering and forwarding only the most relevant data to external or expensive storage solutions.
- 4. Edge-Level Data Redaction: Protect sensitive information by redacting personally identifiable or regulated data before it leaves your infrastructure, helping you meet security and compliance requirements.
Authors
Emily Marshall, Product Solutions Architect